Hallucination blind spots
Confident, wrong answers that damage trust. The system sounds certain while it fabricates, and standard tests never flag it.


Overview Discover how a leading UK legal technology company successfully migrated from on-premises Jira + Xray Server to Jira Cloud, overcoming complex challenges and tight

Challenge Our client, a leading banking group in Southeast Europe, faced the daunting task of creating a complex web application for loans that seamlessly integrated

The Challenge Software applications, particularly web applications, are in a constant state of evolution. This dynamism, while essential for innovation, can create significant hurdles for

Client Overview Our client is a prominent telecommunications holding company based in Asia, renowned as one of the largest in the industry globally. Established in
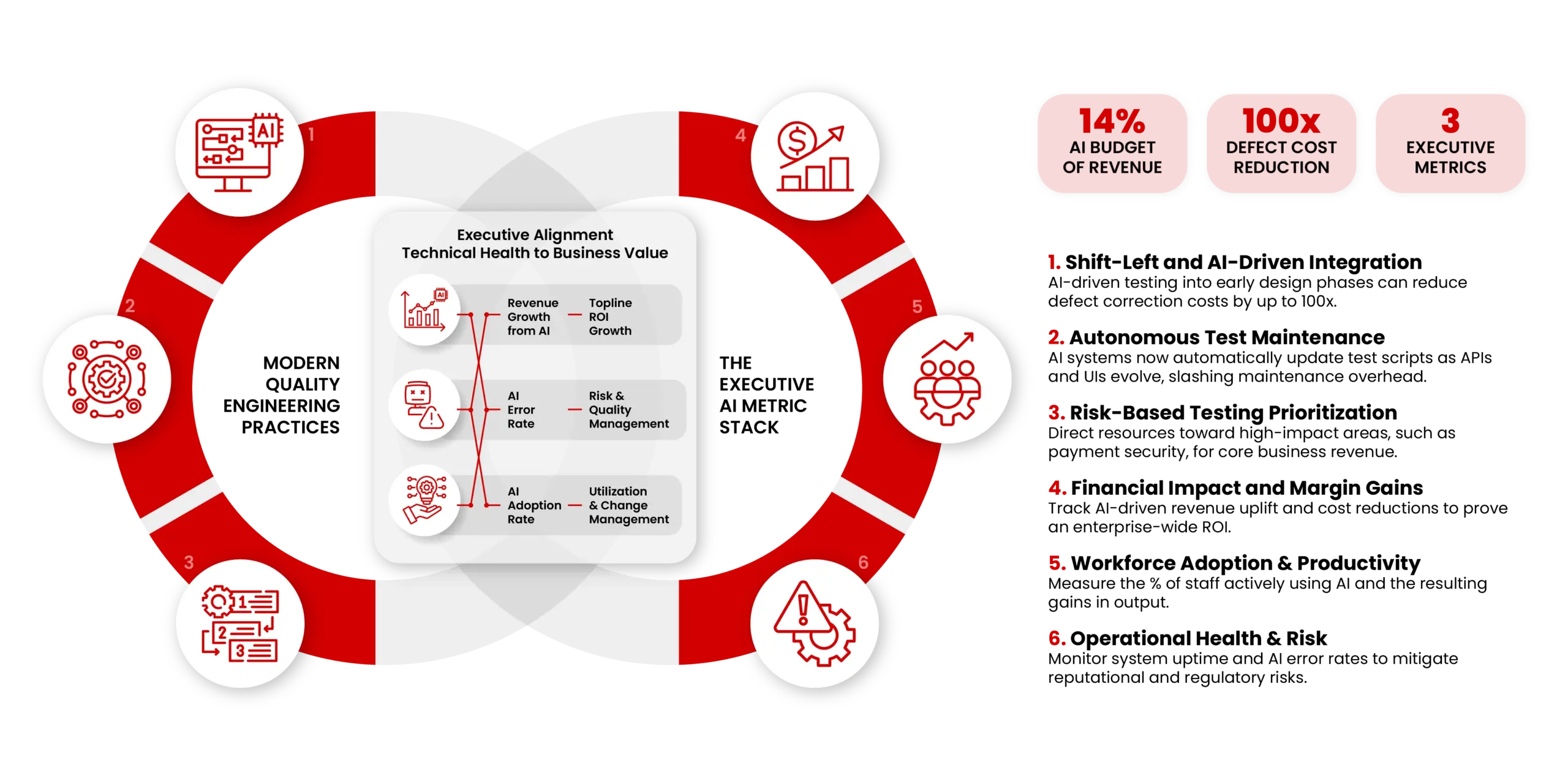
A practical guide to connecting AI quality work to business outcomes, written for the people who fund it and the people who build it.
By signing up for the waiting list now, you'll secure your spot for early access and claim these valuable benefits.