

Amazon attributes roughly 35% of its revenue to its product recommendation engine. That number gets cited often. What gets cited far less is what it took to build it: years of purchase history, petabytes of behavioral data, and teams of machine learning engineers maintaining an infrastructure that never stops retraining.
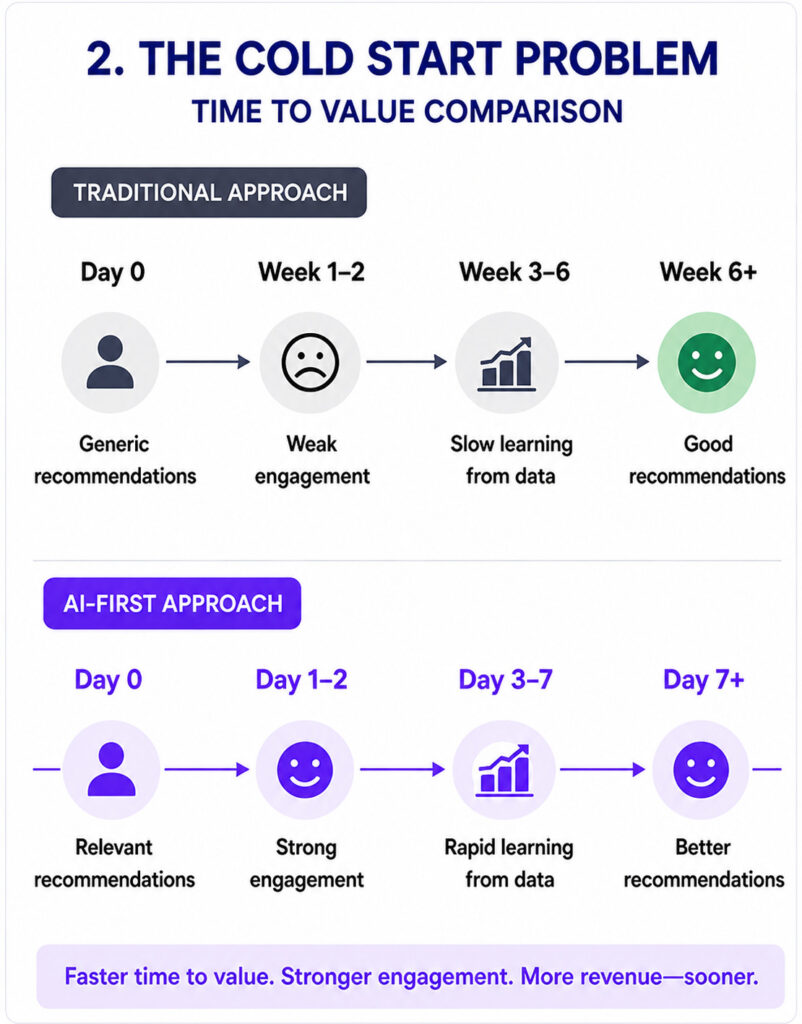
For most retailers, the equation is uncomfortable. A competitive ML-based recommender requires continuous data pipelines, regular model retraining, significant infrastructure investment, and specialist talent to manage model drift and degradation. More fundamentally, it requires months of customer interactions before the system develops meaningful signal on any given product or customer segment.
Launch a new product line, enter a new market, or pivot your brand positioning, and the recommender effectively starts over. This is what the industry calls the cold start problem, and until recently, it was accepted as a structural cost of doing business.
It no longer has to be.
Recent advances in AI, particularly large language models (LLMs) and multimodal embeddings, have fundamentally changed this equation.
What AI First Architecture Actually Means
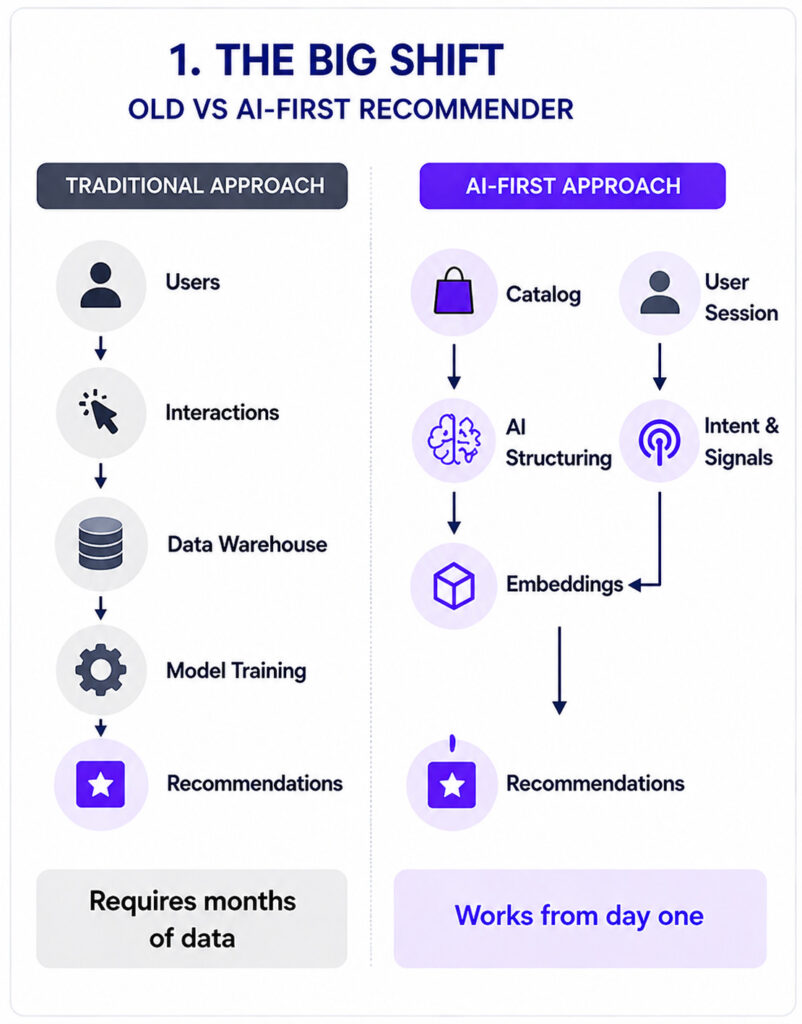
Traditional recommendation systems rely on collaborative filtering, which matches users based on shared interaction histories, often recognizable as ‘users also liked’; and content-based filtering which matches product attributes to known user preferences. These approaches do perform well in giving adequate recommendations, however, require months of accumulated data to personalize effectively and struggle with new users or items with no prior engagement.
Modern Artificial Intelligence has changed the foundational assumption of historical data availability. Large language models (LLMs), semantic embeddings, and zero-shot learning enable recommendation engines to generate meaningful, personalized suggestions without any prior interaction data. The system understands products and users semantically: reading intent, context, and meaning, rather than relying purely on historical pattern-matching.
This is the defining characteristic of an AI-first recommender: AI is embedded as the core logic from day one, not layered on top of a legacy statistical engine. The practical implications are significant.
Early adopters of this architecture have reported markedly improved conversion rates for new visitors, a group that legacy systems historically underserve.
Zero-shot recommenders use pre-trained models to infer preferences for completely unseen users and items no fine-tuning required. A retailer launching today can personalize immediately, not after six months of data collection.
How It Works: Turning a Catalog into Intelligence
Contrary to data first architectures, where the starting point is user data, in AI first recommender systems, the starting point is the product catalog itself. Here is how an AI-first pipeline transforms raw inventory into a personalization engine.
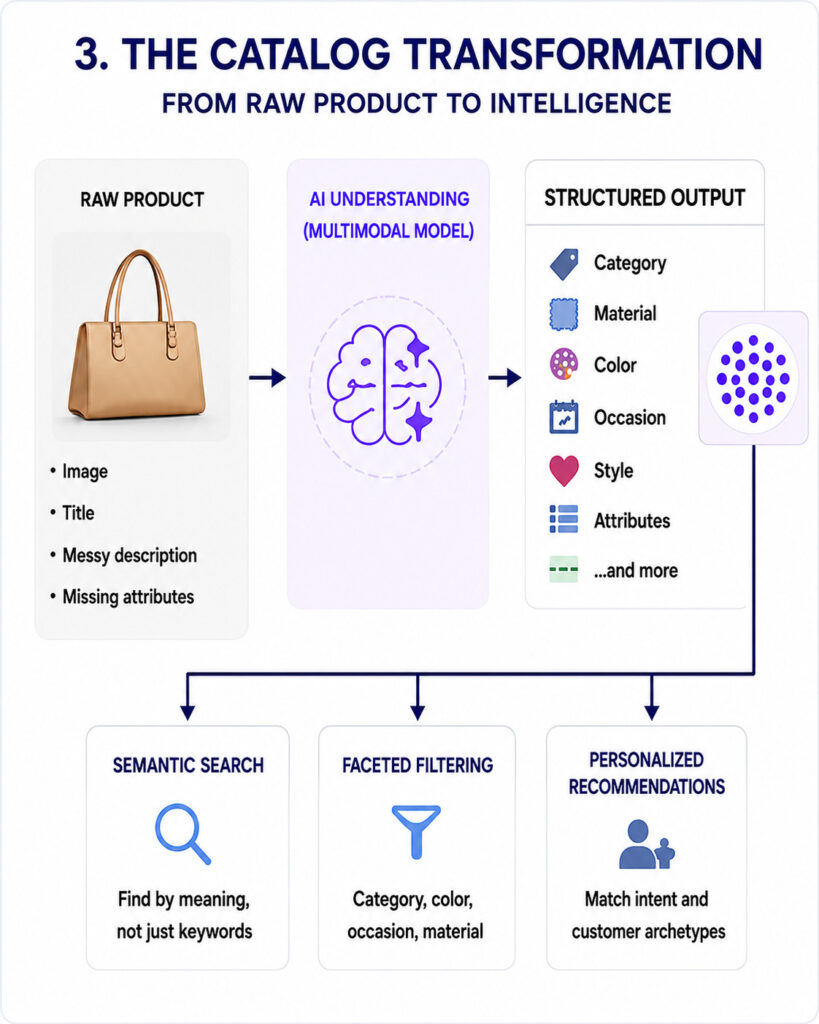
Step 1: Automated Semantic Tagging
Products arrive on a platform with inconsistent, incomplete, or entirely missing metadata. A multimodal AI model, one that can process both images and text simultaneously, examines each product and generates a rich, standardized profile covering category hierarchy, material, occasion, color, aesthetic style, and other business specific fields, for example the buyer’s brand visibility preference.
This process is defined for the platform’s business nature and customizable according to client’s preference or business model.
This replaces what would otherwise require a team of human cataloguers. In practical terms, classifying 10,000 products using current vision-language models currently costs around $10 in API fees, making the approach viable at virtually any scale.
Step 2: Vector Embeddings for Semantic Search
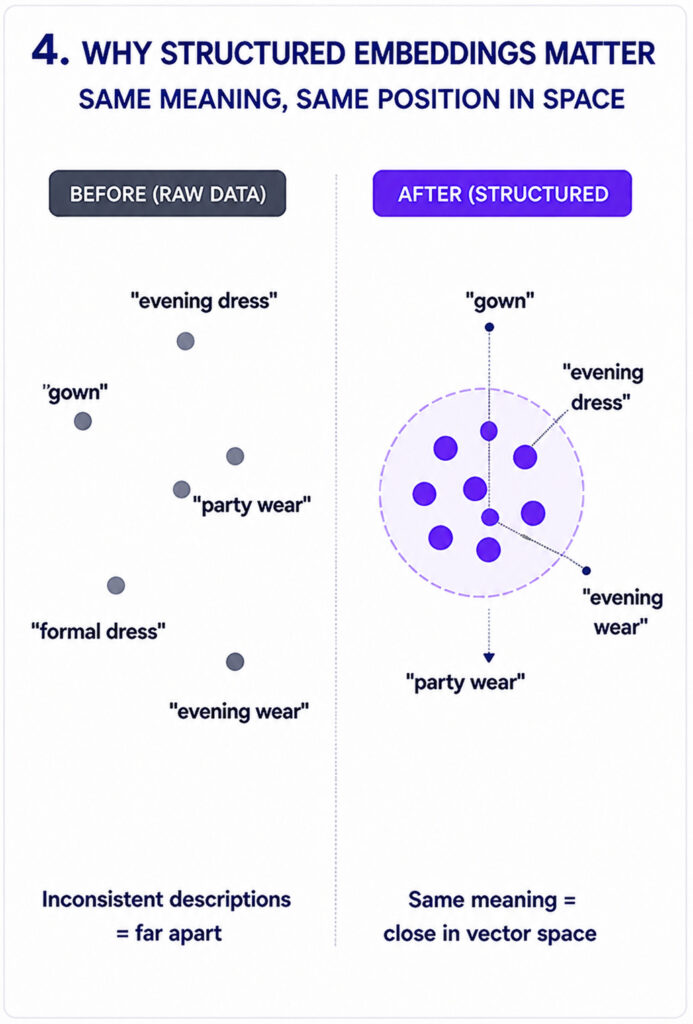
The structured taxonomy for each product is converted into a high-dimensional embedding vector and stored in a vector database. This vector is a mathematical representation that captures the semantic meaning of the product derived from the automated tagging.
This distinction matters enormously. One seller writes “ivory silk gown,” another writes “cream evening dress,” and a third uploads a photo with no description. After AI classification, both are represented by the same structured profile and their embedding vectors sit close together in semantic space. Products that are genuinely similar end up geometrically adjacent, regardless of how their original listings were written.
The same logic powers search and feeds the recommender. When a user types “understated silver jewelry for a wedding,” that query is embedded using the same model, and the database returns products whose vectors are closest, surface matches that may never contain those exact words.
A recommendation engine then re‑uses these same vectors to surface items that are semantically aligned with a user’s past behavior, current session, or on‑screen context, so personalization is driven by meaning, not just by raw keywords or historical co‑occurrence. The result is a search and recommendation experience that feels intuitively correct rather than merely keyword‑matched.
Step 3: Day-One User Profiling
Traditional recommenders treat new visitors as unknowns, defaulting to generic bestsellers. An AI‑first system begins building a preference profile from the very first session.
This is done in the following way:
Every interaction, a view, a pause, a skip, or a save of a previously tagged item maps to the semantic dimensions already encoded in the product embeddings. Because products are pre‑tagged and embedded, the system can accumulate these signals into a dynamic “user vector” that represents the visitor’s emerging preferences in the same semantic space. For example, a user who lingers on investment‑quality pieces while dismissing trend‑driven items reveals a clear preference signal within minutes.
By session end, the system holds a confidence‑weighted latent portrait of the user, derived via cosine similarity search across the product vector space: it compares the user vector against the vectors of unseen items, ranks candidates by semantic affinity, and surfaces recommendations that are both novel and meaningfully aligned with the user’s inferred taste.

The Strategic Opportunity for AI in Retail
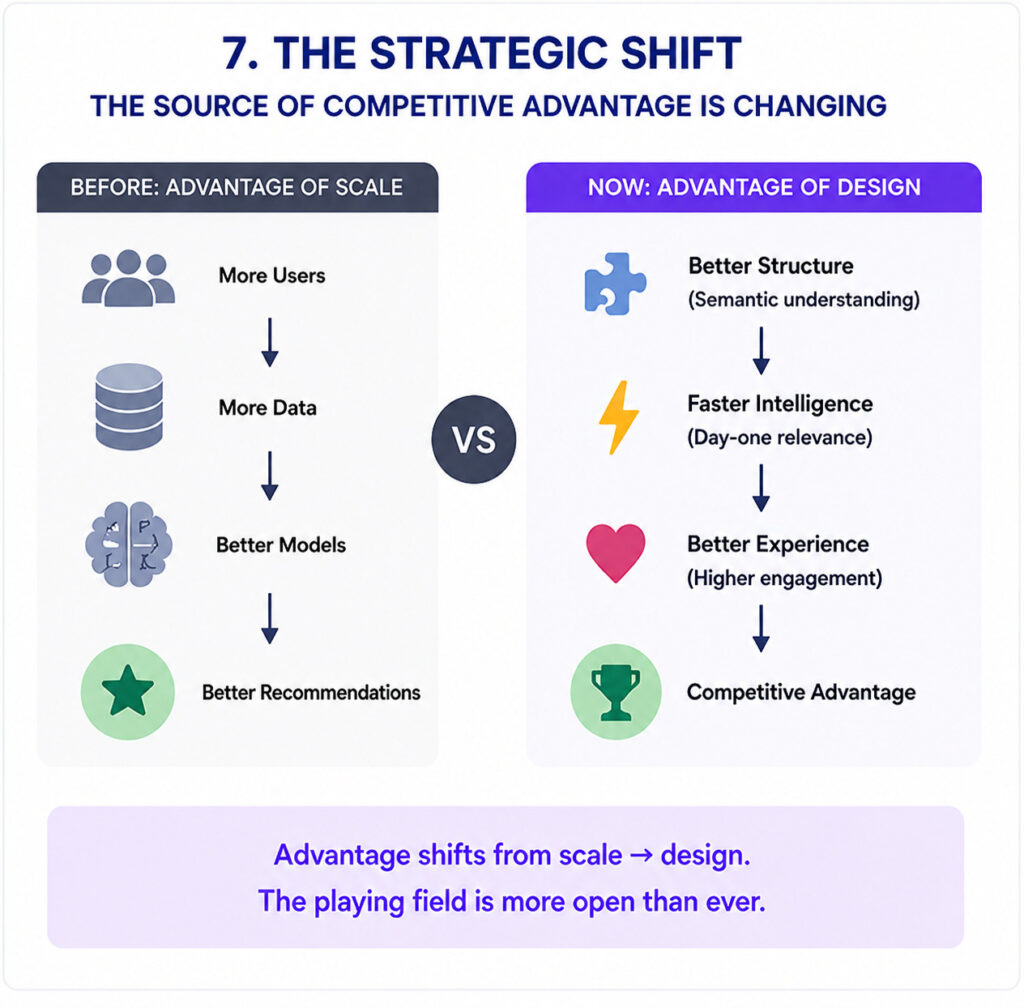
Historically, sophisticated recommendation infrastructure was a moat available only to companies with Amazon- or Walmart-scale data assets. The cost of entry in terms of time, engineering talent, and infrastructure was simply prohibitive for most retailers.
AI-first architecture changes that calculus. A modern bootstrap stack, combining open-source embedding models, a managed vector database, and LLM APIs for catalog enrichment can be stood up for significantly less, and can be developed even alongside regular application or website development from the very beginning. That is within reach of DTC brands, specialty retailers, and emerging-market commerce platforms that would previously have had no path to meaningful personalization.
A retailer launching today can personalize immediately, not after six months of data collection.
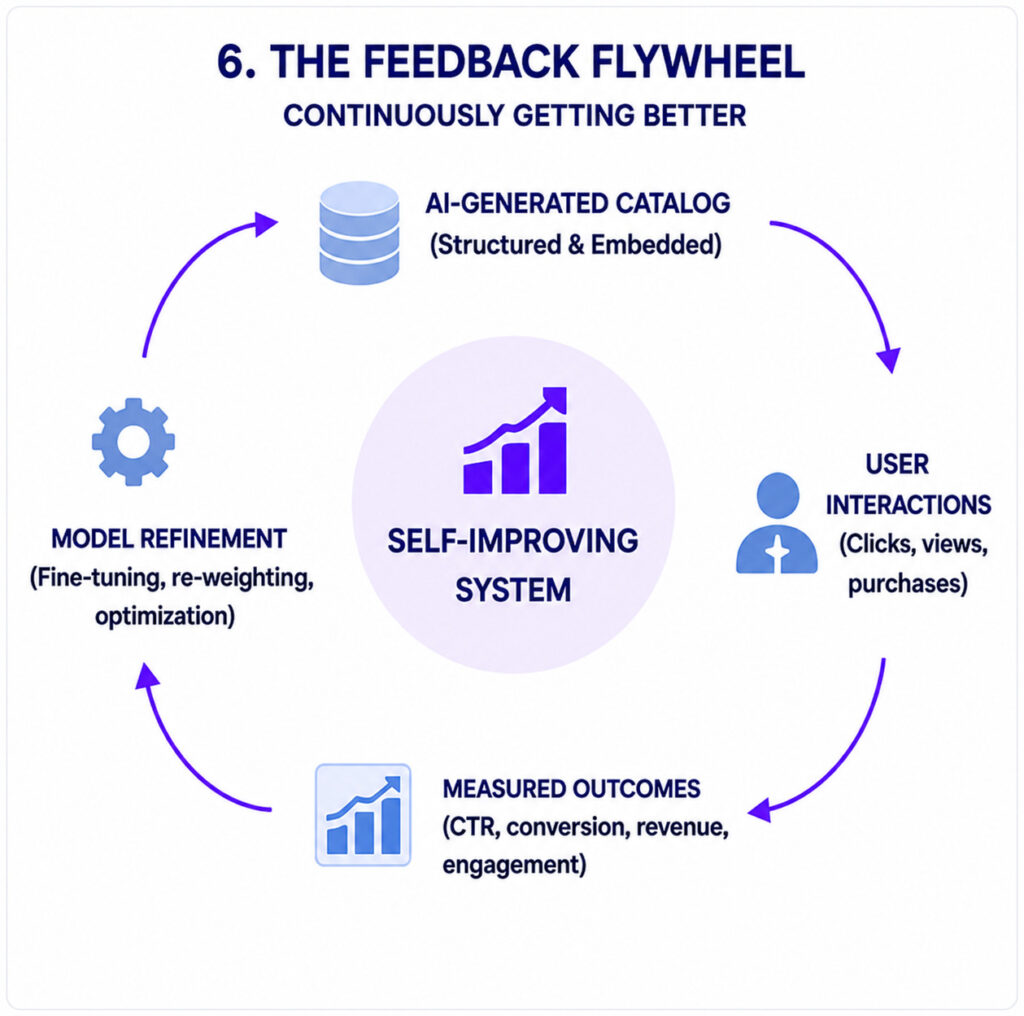
There is also a compounding advantage. Once the system is live and collecting real interaction data, that data can be used to validate and refine the AI-generated tags through A/B testing on click-through and conversion rates. Over time, it is also possible to gradually switch to fine-tuned models using techniques like LoRA (Low-Rank Adaptation) that can reduce inference costs by up to 80% while improving accuracy turning an initial AI investment into a self-reinforcing competitive edge.
Key Takeaways for Leadership
| Consideration | What It Means |
| Cold Start | New users and new products are personalized from first interaction, no accumulation period required. |
| Catalog as Asset | Your product inventory becomes a pre-mapped semantic space, queryable for precise customer-intent matching before a single sale occurs. |
| Cost of Entry | AI first stacks cost $2K–$10K/month to operate accessible to mid-market retailers, not just enterprise. |
| Data Flywheel | Real interaction data validates and improves AI tags over time, compounding accuracy and reducing inference costs. |
| New Market Entry | Entering a new geography or launching a new category no longer resets your recommender. Semantic understanding transfers across contexts. |
The Bottom Line
The cold start problem is not an inevitability of retail anymore, it is rather a limitation of traditional recommendation systems. AI‑first architecture eliminates that constraint by turning your product catalog into an intelligent, ready‑to‑use asset from day one.
AI‑first retail recommendation systems transform the economics of personalization. Instead of waiting months for data to become useful, retailers start with intelligence already embedded in the product catalog, powered by semantic embeddings, LLMs, and zero‑shot learning.
This means new visitors, new products, and new markets can be personalized from day one, not after a long data‑collection phase. The result is faster revenue impact, lower long‑term technical debt, and a compounding advantage: every interaction both validates and refines the system, making it more accurate and cost‑efficient over time.
For leadership, the value is clear, AI is no longer a luxury reserved for data giants, but a strategic lever every mid‑sized retailer can and should turn on.
Innovation, not data volume, is now the differentiator. The infrastructure to act on that has never been more accessible.