
1.Introduction
Bad sensor data doesn’t just slow down reporting. It erodes confidence in the numbers that drive operational decisions. This article describes how we designed and built a data processing solution for a sodium bicarbonate manufacturer, turning raw sensor readings into reliable aggregated insights their teams could actually trust.
The system ingests time-series data into a central repository, processes it in configurable batches, and structures it for reporting and analytics. The engineering was straightforward in places and genuinely tricky in others, particularly when dealing with sensors that don’t reset on schedule.
2.Understanding the Data
The sensor setup consisted of two distinct tag types: instantaneous and totalizer. Instantaneous tags cover standard measurements like pressure or temperature. Values fluctuate within a stable range and don’t depend on prior readings. Processing them is clean: group data into predefined time intervals, calculate standard aggregations (minimum, maximum, average, sum, first, last), move on.
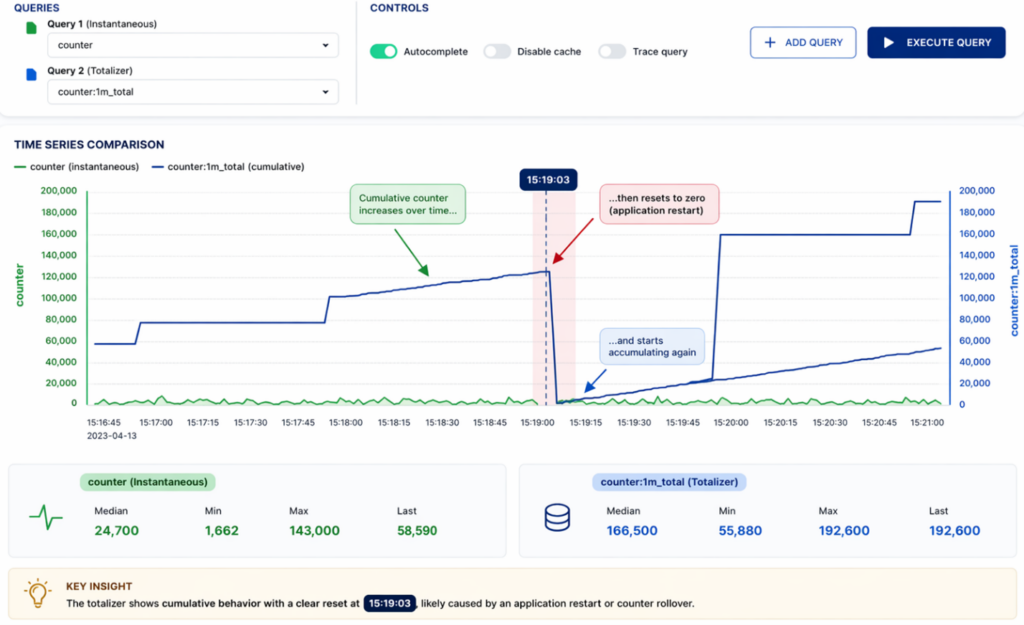
Totalizer tags are a different story. These sensors track cumulative measurements. Values climb steadily over time until a reset occurs, then the cycle starts again. Each tag has a configured reset period, but in practice, resets don’t happen at precise or predictable timestamps. That’s where the real engineering challenge begins.
3.The Core Challenges and Solutions
3.1 Detecting Reset Boundaries in Imperfect Data
Real-world totalizer resets are rarely clean. Instead of a neat drop from maximum to zero, the data often contains noise, empty cycles, gradual declines, or multiple drops in quick succession. Resets also tend to drift , occurring slightly earlier or later than expected, so rigid time-based segmentation isn’t enough. The solution needed to be dynamic and data-driven.
3.2 Performance and Scalability Considerations
With high volumes of incoming sensor data, processing efficiency wasn’t optional. The architecture had to scale without sacrificing accuracy.
3.3 Handling Late-Arriving Data
Network latency, system interruptions, and upstream delays are facts of life in industrial environments. Without proper handling, late data leads to incomplete or inconsistent aggregations, and reports that can’t be trusted.
3.4 Historical Reprocessing
The system also needed to handle large volumes of historical data when required, without duplicating logic or building separate workflows for each scenario.
4.How we solved it
4.1 Reset Boundary Detection (Addressing Challenge 3.1)
The core solution combined window-based processing with set-based logic — avoiding the performance cost of row-by-row evaluation.
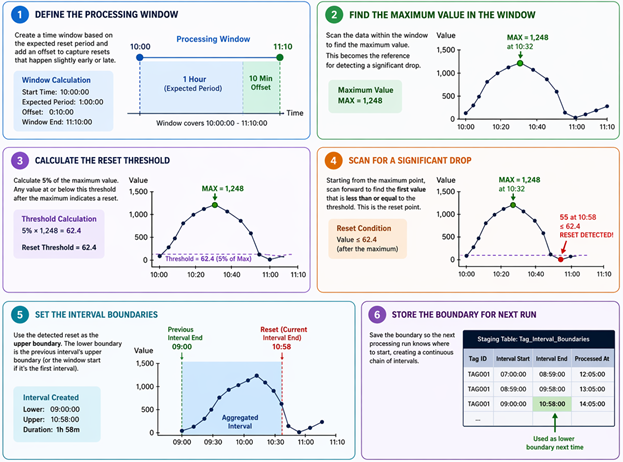
For each totalizer tag, data was divided into time windows based on the expected reset period. An additional offset window was added to each interval to catch resets that drifted slightly outside the expected timeframe.
Within each window, the algorithm identifies the maximum value and uses it as a reference point. It then scans forward to detect a significant drop, defined as a decrease to 5% or less of the maximum. That drop marks the reset point.
When multiple drops appear in the data, the logic selects the most recent and relevant one. Once identified, the reset point becomes the upper boundary of the current accumulation cycle. The lower boundary comes from the previous cycle’s upper boundary, creating a continuous chain of intervals. These boundaries are stored in a dedicated staging table, so the system maintains accurate state across multiple processing runs. Every aggregation is then performed on the correct data subset, even when resets are irregular or delayed.
4.2 Performance Optimization
Two strategies kept processing efficient at scale. First, a threshold-based approach: tags with shorter reset periods run hourly, while those with longer intervals are written to a landing table and processed once per day. Second, the reset detection logic itself, starting from the maximum value within a window rather than scanning row by row, cuts processing time significantly on large datasets.
4.3 Handling Late Arriving Data
When late data arrives for a tag that’s already been processed, the system reuses the upper boundary of the last valid interval as the starting point for recalculation. Affected intervals are recalculated, boundary records are updated, and final results are merged into the target tables without duplication. Existing records get corrected rather than replaced.
4.4. Historical Data Processing
The same stored procedures handle both real-time and historical execution, controlled through input parameters. Large volumes of historical data can be reprocessed without separate workflows or code duplication, and historical and real-time processing can run at the same time without interfering with each other.
5. Results
The solution gave the manufacturer a reliable foundation for operational reporting. Reset boundaries are detected accurately even in noisy, irregular data. Late arrivals are handled without compromising historical records. And when reprocessing is needed, it runs cleanly alongside live data. For teams evaluating how to handle cumulative sensor data at scale, the key takeaway is this: totalizer metrics need their own processing logic.
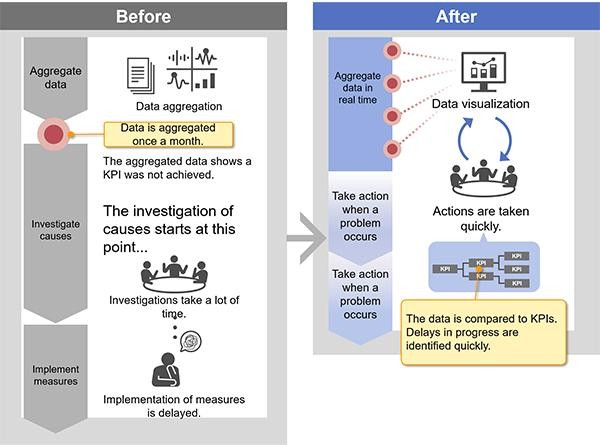
Standard time-based aggregation isn’t enough. Get the reset detection right, and everything downstream, reporting, analytics, operational decisions, becomes more dependable.