
Data governance is the single biggest factor that decides whether an AI initiative ships or stalls. AI models are only as trustworthy as the data they rely on. That’s why our approach to data governance isn’t a policy document. It’s a live framework built directly into Snowflake, and it runs the data platform.
Why Do AI Initiatives Stall Before They Start?
Most AI projects don’t fail because of models. They fail because of the data underneath them. Budgets get approved and talent gets hired. Then the team tries to build something real, like a forecasting model, and the work grinds to a halt on data nobody trusts.
The pattern repeats everywhere. If Customer means one thing in the CRM and something else in billing, with no canonical definition anywhere, every model inherits that confusion. Gartner predicts that through 2026, organizations will abandon 60% of AI projects that aren’t supported by AI-ready data.
This is the quiet crisis in most data teams. It’s also why governance can’t be an afterthought.
Governance as Configuration, Not Documentation
Our framework treats data governance as pipeline configuration, not documentation. The governance layer isn’t a third-party catalogue or a policy wiki. It’s a structured Snowflake schema that pipelines query at runtime. When a data steward updates a rule, platform behavior changes. No engineer touches code.
Traditional governance produces documents. Policies get written, dictionaries get populated, and then they go stale while the platform keeps evolving. The documentation ends up describing a reality that no longer exists.
Governance-as-configuration closes that gap. In our framework, the governed metadata is what the pipelines actually run on:
- Ingestion pipelines read entity catalogues and data contracts at runtime. No hardcoded field lists in pipeline code.
- Validation procedures apply the right quality checks per entity, pulled from a governed rules catalogue.
- Failing records are routed to a governed quarantine based on severity. Nothing is silently dropped.
- Exception approvals are written back into operational metadata with a business reason, an approver, and a fixed expiry date.
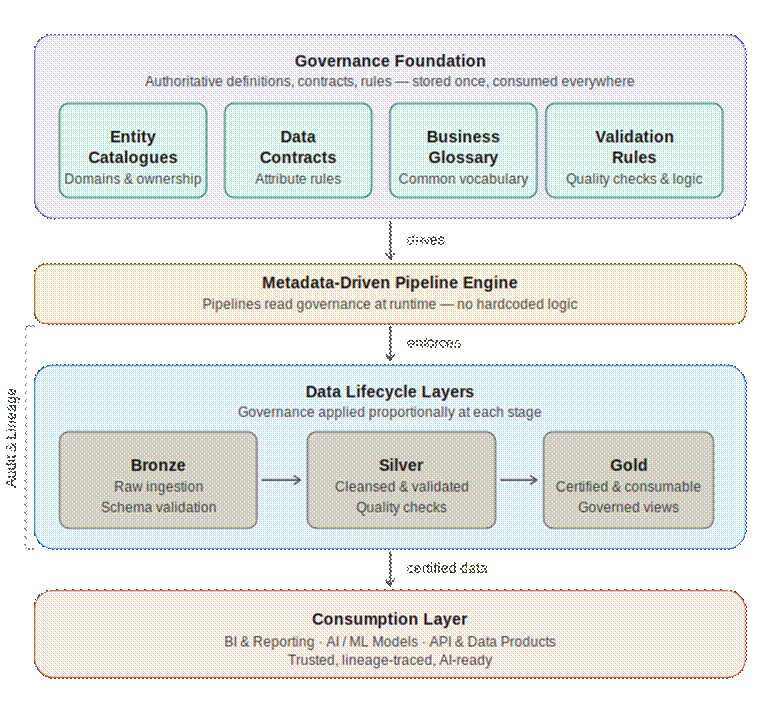
Figure 1: From governance foundation to AI-ready consumption
How Does the Framework Enforce Snowflake Data Governance?
Snowflake data governance in our framework is enforced in layers, with stricter checks at each stage. Bronze applies structural validation at ingestion. Silver runs full attribute-level checks against governed data contracts. Gold exposes only certified data through semantic views, with lineage traceable from source system to consumption.
At Bronze, the platform checks that expected entities arrive with the correct shape. Structural violations trigger immediate quarantine, so nothing broken moves forward.
At Silver, completeness, uniqueness, validity, and referential integrity are measured against the governed contracts. Records are promoted, flagged, or quarantined. Stewards control the severity thresholds.
At Gold, semantic views expose certified data with governed metric definitions. Full lineage from source to consumption is what makes AI outputs explainable later, and it’s built in from day one rather than reconstructed after the fact. No archaeology required. We’ve applied this layered model in production, including in our Snowflake data governance work for enterprise clients.
What Does AI-Ready Data Actually Require?
AI-ready data is consistently defined, quality-measured, lineage-traced, and certified for use. Every AI initiative depends on four properties, and none of them exist without a governance foundation underneath.
- Explainability requires lineage. Regulators and stakeholders now ask how an AI output was produced. Without traceable lineage, that question has no answer.
- Reliability requires consistent definitions. A model trained on a Customer entity needs that entity to mean the same thing no matter which system supplied the data.
- Trust requires measurement. Data quality KPIs show whether data is fit for a given use case before any model ships.
- Scale requires metadata-driven design. New entities are onboarded by populating catalogue and contract tables, not by writing new pipeline code.
How Do You Evaluate an AI-Ready Data Platform?
The fastest way to evaluate an AI-ready data platform is to ask where governance lives. If it sits in documents beside the platform, it will go stale. If it’s infrastructure inside the platform, queried on every pipeline run, it compounds in value with every entity you onboard.
The same test works whether you’re sitting through a vendor pitch or auditing your own architecture. Ask four questions:
- Can a data steward change a rule without an engineer redeploying code?
- Is every failing record quarantined with a reason, or silently dropped?
- Can you trace any number in a dashboard back to its source system?
- Does onboarding a new entity mean configuration, or a new project?
Our framework answers yes to all four because it treats governance as infrastructure, not as a workstream running alongside the platform. The more entities you onboard, the richer the audit trail, the more reliable the data, and the more confidently you can build on top of it.
AI capability is commoditizing fast. The companies that move fastest won’t be the ones with the best models. They’ll be the ones with the best data, and governance is how you get there.
If your AI roadmap is blocked on data trust, talk to our data team. We’ve built this exact foundation before, including trusted AI for a global medical affairs partner, and we’ll show you what it looks like on your platform.
Frequently Asked Questions
AI-ready data is data that’s fit for the specific AI use case it serves. It’s defined the same way across systems, validated against clear quality rules, traceable to its source, and certified for use. Readiness isn’t a one-time state. It’s kept that way by governance running inside the platform.
Start with shared definitions, not with models. Define canonical entities and a common business glossary. Capture data contracts and validation rules in a governed store. Enforce them in your pipelines, and certify only the data that passes. Once that foundation exists, model development gets much faster.