

We already talked about what is SnapLogic, presented a real picture of the platform, and showed the main benefits from using it in our SnapLogic ETL to Redshift dimension loading blog post. So, I don’t want to brag about the platform itself, but here I’ll talk about real problems that we faced and solutions to resolve them using the SnapLogic platform.
In order to understand better we need to explain what is NetSuite first.
NetSuite as a company provides cloud software, which basically is an online service that enables companies to manage all key business processes in a single system. Its benefits are similar to those of using SnapLogic’s platform: there is no hardware to procure, no maintenance fees associated with hardware or software, no complex installations and setups to be done by the users, etc.
Mainly its usage is based on inventory management, enterprise resource planning (ERP), keeping track of financials, hosting of eCommerce stores, maintaining custom relationship management (CRM) systems, Professional Services Automation (PSA), etc.
NetSuite’s highly capable API provides address and update capability to the hundreds of NetSuite objects, custom fields, and custom objects. However, the API is complex, and detailed, and generates pretty big XML requests for the business objects.
All of the above recapped in one sentence:
NetSuite is one unified business management cloud suite that incorporates Accounting/ERP, CRM, e-commerce, and Retail POS in a single, fully integrated SaaS solution.
Custom integration normally requires custom development, a secure and scalable place to host the code, and some Suite script on the NetSuite side. Instead of this, SnapLogic has pre-built, intelligent connectors called snaps that are using NetSuite’s web service, that are smart about its API. Also, SnapLogic has a simple way to build, deploy, and monitor the code to perform a stable production integration.
By rapidly integrating NetSuite with other enterprise systems using SnapLogic’s integration platform, organizations can greatly increase the flexibility of IT processes, ease the pain of adding or retiring applications, and enable ERP teams to focus on more strategic business priorities.
Use case
Depending on the type of data that needs to be integrated into NetSuite, businesses must identify which are suitable NetSuite objects or entities that should be used in order to have consistency in the data. In this specific use case, we will be using the JournalEntry object to insert Revenue / AR, Cash, Payments and Adjustments, Deferred Revenue / Reversing Revenue, and Tax data.
In short, these are the requirements that need to be met with this flow:
- Read CSV files from the FTP server
- Validate the data in the files if it meets all validation requirements
- Transform the data to the appropriate Journal Entry object format
- Insert the transformed data into a Journal Entry form in NetSuite
For each of the processes (pipelines) that we are developing, SnapLogic’s best practices and coding standards are followed and error handling, logging, and retry logic are implemented. In correlation with this, for each flow, there is one main parent and a sub-pipeline. Communication is located in the parent pipeline with the source system and the dynamic call to the sub pipeline where we do all the validations, transformations, and insertion into NetSuite.
First, we will construct a parent pipeline where we will pull CSV files from the source SFTP server in a few steps:
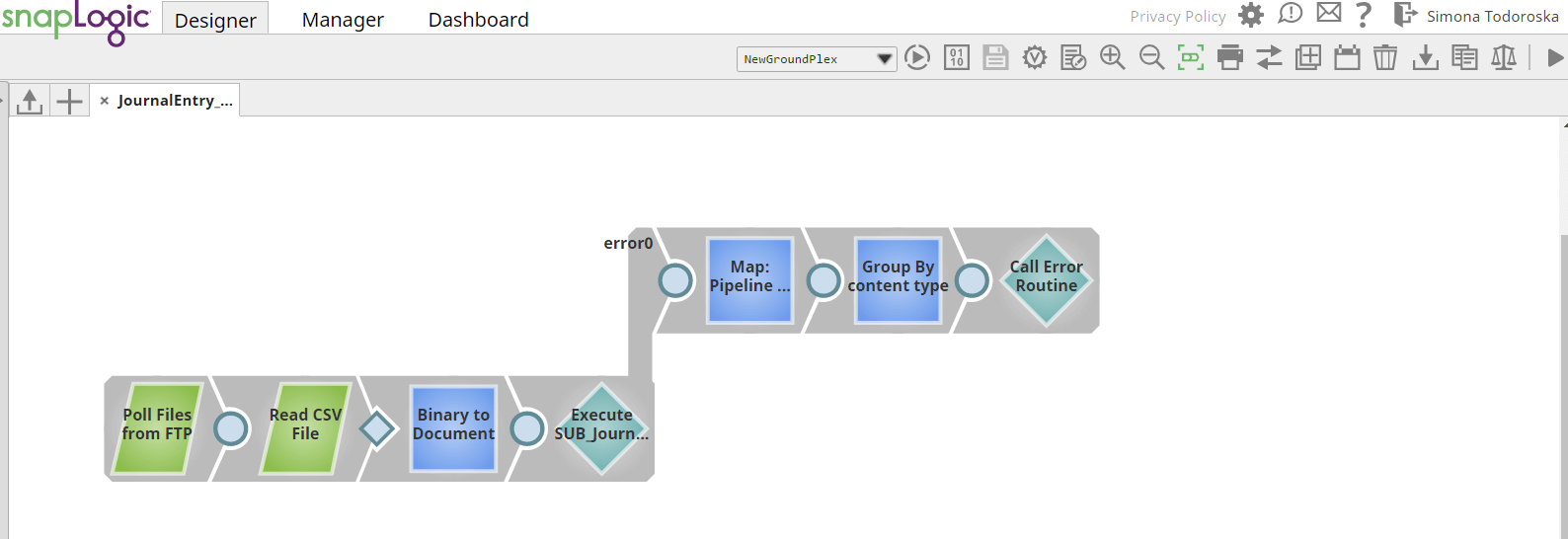
- File puller – Check for files present in the source SFTP server
- File reader – Read polled files
- Binary to document – Encode the file content
- Pipeline execute – Call the child pipeline where all of the transformations are happening
There are multiple rules in the Journal Entry object that must be followed, such as that Credit and Debit SUM of total lines must balance, incoming account should be validated according to a previously defined list of accounts, validation of field types and etc.
Once we successfully call the child pipeline where all the extracting, transformation, and load actions are happening, these are the steps we’ll perform in it:
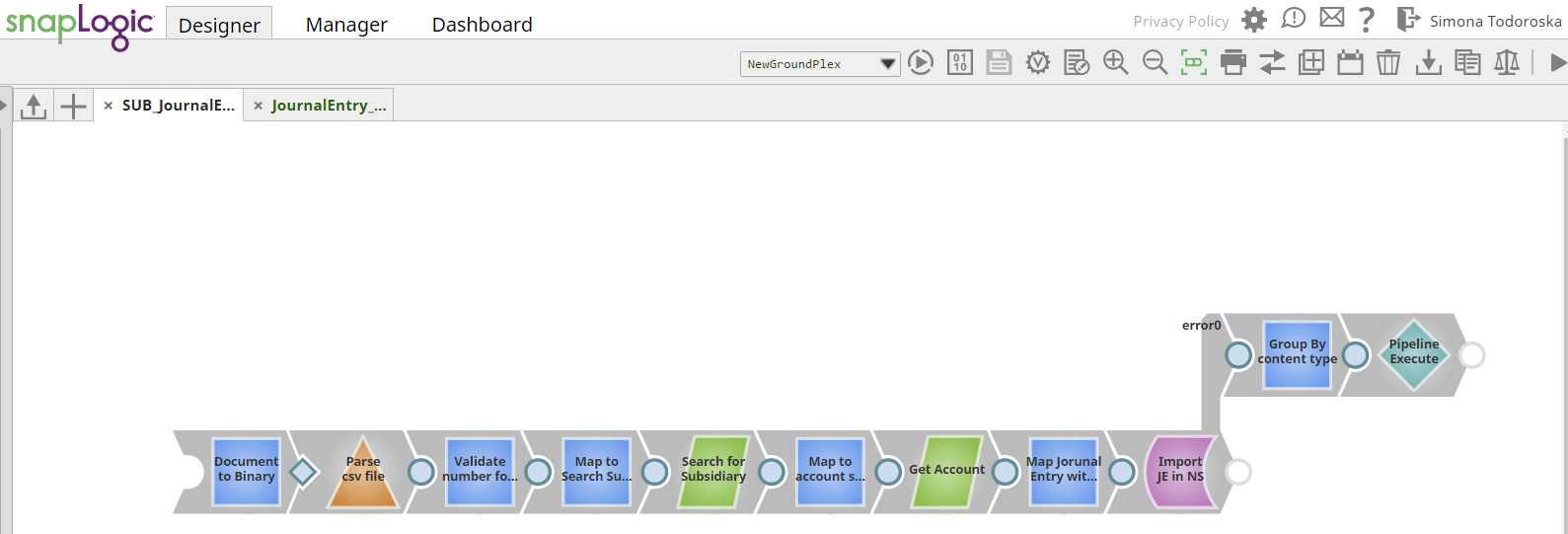
- Document to Binary – Decode Base64 content that we receive from the parent pipeline
- CSV Parser – Parse CSV data
- Data validator – Validate data according to predefined validation rules
- Mapper – Create a message to perform a Search operation in NetSuite
- NetSuite Search – Perform Search operation in NetSuite for the Subsidiary object
- Mapper – Create a message to perform the Get operation in NetSuite
- NetSuite Get – Perform the Get operation in NetSuite for the Account object
- Mapper – Create a message to perform the Create operation in NetSuite
- NetSuite create – Perform Add operation in NetSuite for successfully inserting a Journal Entry record in NetSuite
In order to successfully get an account from NetSuite, SnapLogic exposes the NetSuite schema of the Get operation and we can easily map values into its required fields with a mapper snap:
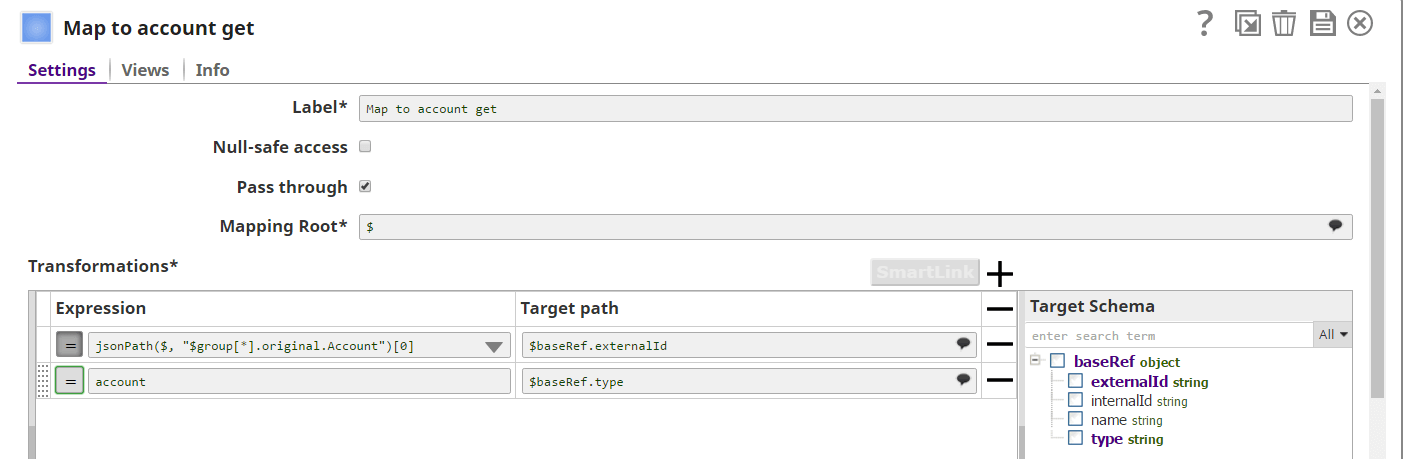 (Image 4 – Mapper snap where NetSuite Get account request is mapped)
(Image 4 – Mapper snap where NetSuite Get account request is mapped)
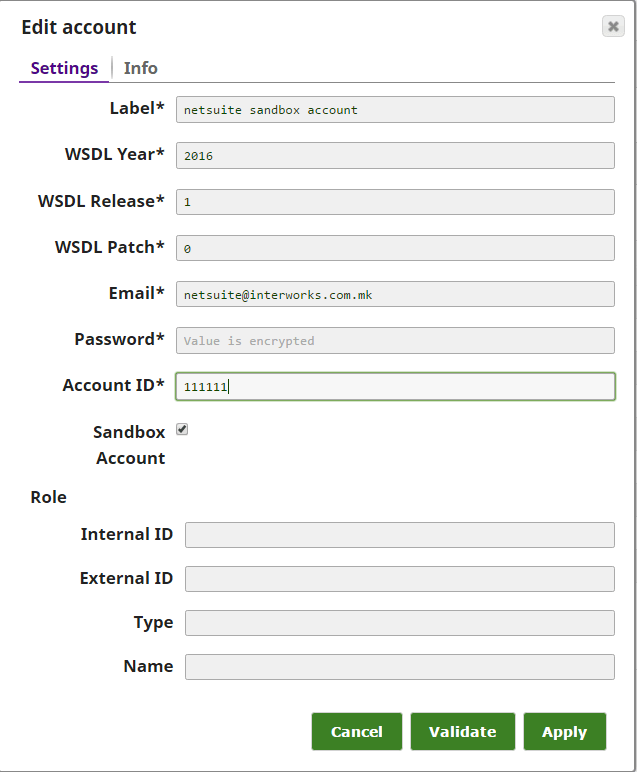
After we have successfully done all the validations and lookups, we create an Add request to NetSuite for creating a JournalEntry. In each of the NetSuite snaps an account should be configured for successful authentication and in it we are defining which WSDL release we want to use, putting predefined credentials, account ID, and role.
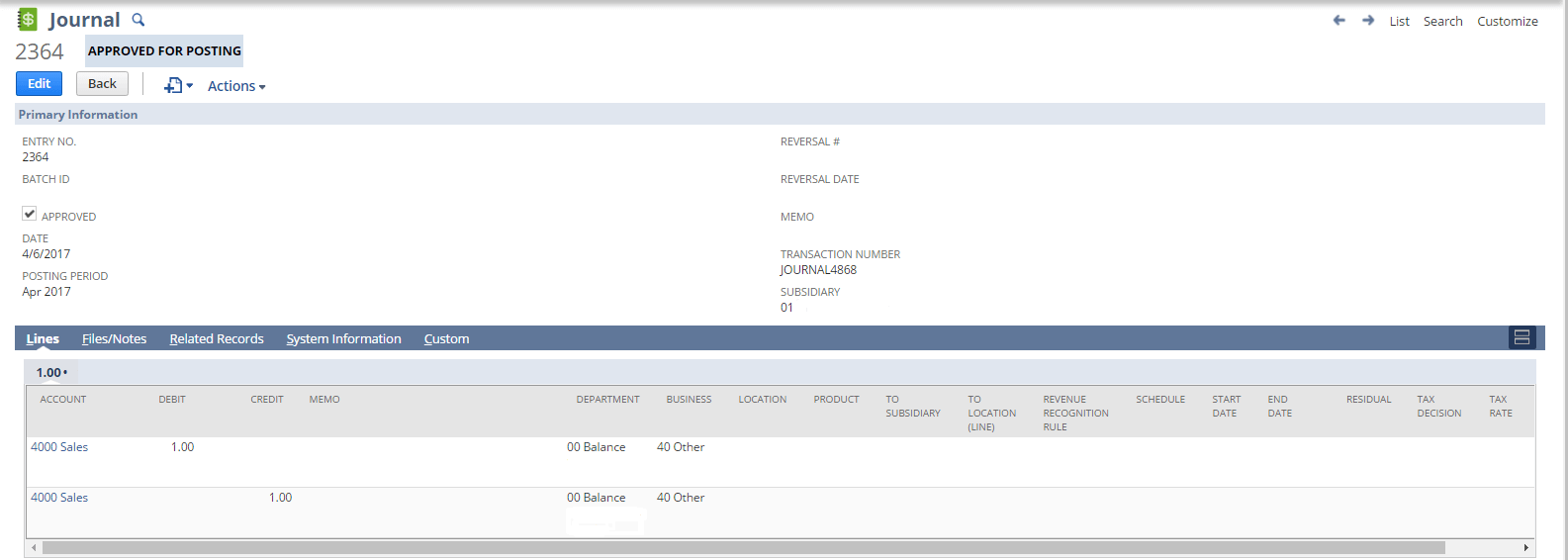
So, after the pipeline is finished with its execution we can preview the created Journal Entry into NetSuite and check if the data is inserted correctly.
In the pictures of the main and child pipeline, you can see that there are error views connected to the pipeline execute and NetSuite creates a snap, and the error views are basically mapping the errors in an error schema and calling a common error routine pipeline.
In order to execute this use case in a scheduled interval we need to create a task in SnapLogic manager to run on a specific interval.
What is a task in SnapLogic? Tasks are nothing but a way to execute a process (pipeline). From the tasks page in the SnapLogic manager, you can view what tasks are already available and create new ones. Since the pipelines executed by tasks will be running without you doing anything, email notifications can be sent for the status of the pipelines.
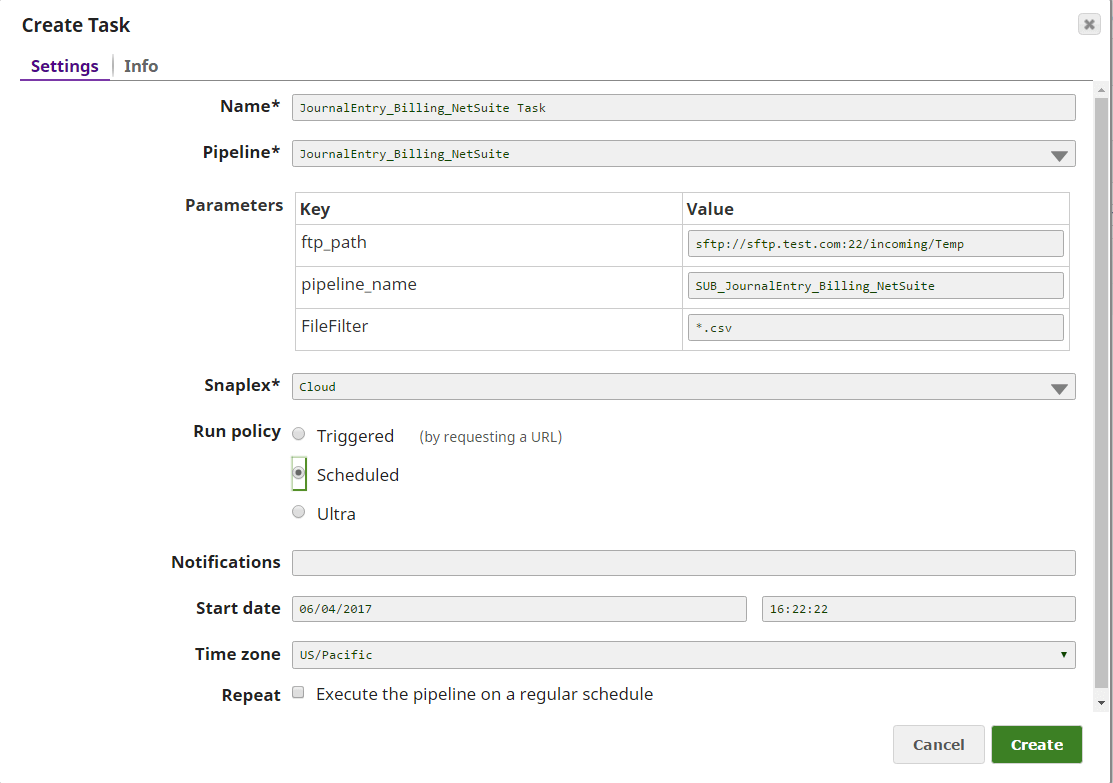
When creating the task, as seen in the picture, except for the interval, we must: configure the Pipeline that we want to execute, pipeline parameters, which are exposed values that we don’t want to hardcode in the code, Snaplex on which we want the pipeline to run, because it can run on cloud and on-premise also.
Worth mentioning here is that in SnapLogic we can make not just a scheduled job, but also a triggered job which can simply be invoked directly from the code or from a different application by triggering an exposed URL from SnapLogic with a given authentication. But for a detailed explanation of this, stay tuned on our blog or simply contact us.
Conclusion
As explained in the above use case, SnapLogic has an easy way to integrate with NetSuite without writing long custom codes. In this way you’ll get short design and development time, fast data insert into NetSuite objects, easy changes detecting and code debugging, visual development of a diversity of transformations and data operations using a big set of fundamental snaps, and effortless code deployment and maintenance.
So in conclusion, we can easily say that SnapLogic and NetSuite are a perfect match for easy and fast integration of your existing or real-time ERP data.