
The rise of streaming data
A stream can be defined as a sequence of data, continuously generated by different sources. Streams have potentially unlimited data, unlike any other collection of finite data used in traditional batch processing. Now, where can examples of stream data in real life be found, and how can they be used? Let’s take for example any large e-commerce provider (online shop) like Amazon, eBay, or AliExpress. It can be easily noticed that after some period of looking and searching for different items we are getting suggestions for products, that is, the content displayed has been optimized based on our search or clicks. So how is that done? First, the stream here is generated by the clicks on the web page by the millions of different users accessing the page at any given time. This can be called a web clickstream of records and it is usually enriched with specific data for the user, like demographic info or purchase history. Next, this stream of data is being processed in real-time as it flows. And finally, suitable feedback, based on additional machine learning techniques (user collaborative filtering or market basket analyses) is provided back to the user, delivering relevancy and optimized content.
Another example would be stock price movement (continuous never-ending stream), player-game interaction in any online gaming, data from mobile apps, IoT Sensors, or application logs. The digitalization level in today’s everyday life is generating massive quantities of streaming data from various sources, and streaming data usage is on the rise like it was never before.
Stream processing
Processing those data streams today raises new challenges, one of them is to process the streams in real-time. Recent data is highly valuable, in the e-commerce example we need the processing results while the user is in the online shop once he has left we don’t have much use for that data. Then again a combination of old and recent data is even more valuable, combining current web clicks and purchase history can produce greater relevance.
Amazon Web Services Streaming platform
Amazon Kinesis is Amazon Web Services (AWS) platform that provides the infrastructure needed to build streaming data applications. Currently, Amazon Kinesis provides three cloud-based services:
- Amazon Kinesis Streams, are used for continuously capturing and storing terabytes of data per hour from hundreds of thousands of different sources.
- Amazon Kinesis Firehose is used for loading the streaming data into any AWS services like S3, Redshift, or Elasticsearch.
- Amazon Kinesis Analytics is used for processing the streaming data in real-time. This is the latest from Kinesis Services, released in August 2016. It was announced by Amazon as “a fully managed service for continuously querying streaming data using standard SQL.” In a nutshell, Amazon Kinesis Analytics enables one to run continuous queries against the streaming data, using standard SQL. Processing data in means of filtering, transforming and aggregating can be done in minutes without using anything more complex than a SQL query. Therefore the service can be used without the need of learning any new programming skills, making the learning curve here very short for anyone with SQL knowledge. The most common integration of Kinesis services can be seen in Image 1.

Creating an Amazon Kinesis Analytics application can be done in minutes, first AWS account is needed, and next a couple of easy steps in the Kinesis AWS Management Console.
After creating the application, (named “KinesisDemo” here) stream source needs to be configured (the input data for our SQL):
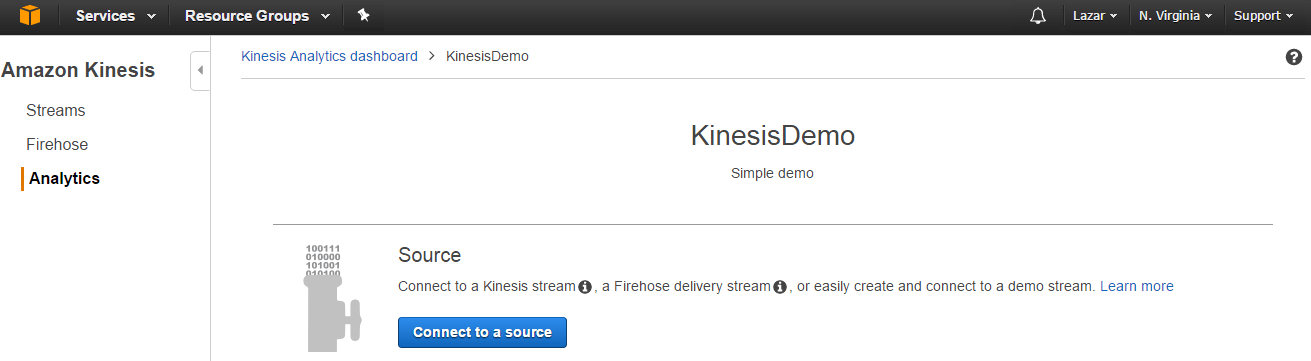
A new stream can be configured using a demo stream so there is no need to configure a real Kinesis Stream or Firehose for a simple demo. Here it can be noted that as a stream source only Kinesis Stream and Firehose can be used, so Amazon Kinesis Analytics is closely integrated with those two AWS’s, there is no space for any standalone usage in terms of source, like creating some customized stream source.

In less than a minute a stream schema is generated with sample data as shown in Figure 4. And of course it can be customized or tuned.
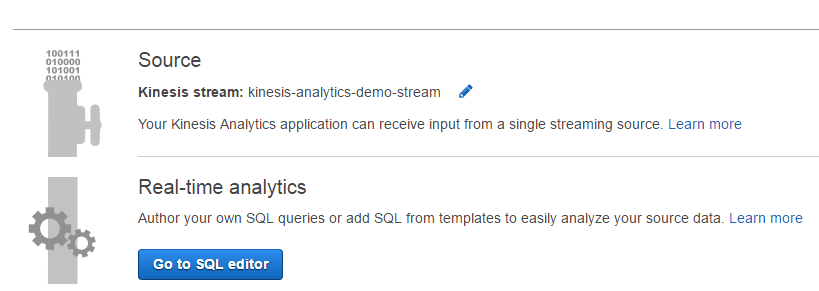
The next step would be running the SQL editor:
The demo application can be run at the same time providing sample data streams for the SQL code to be run in real time.
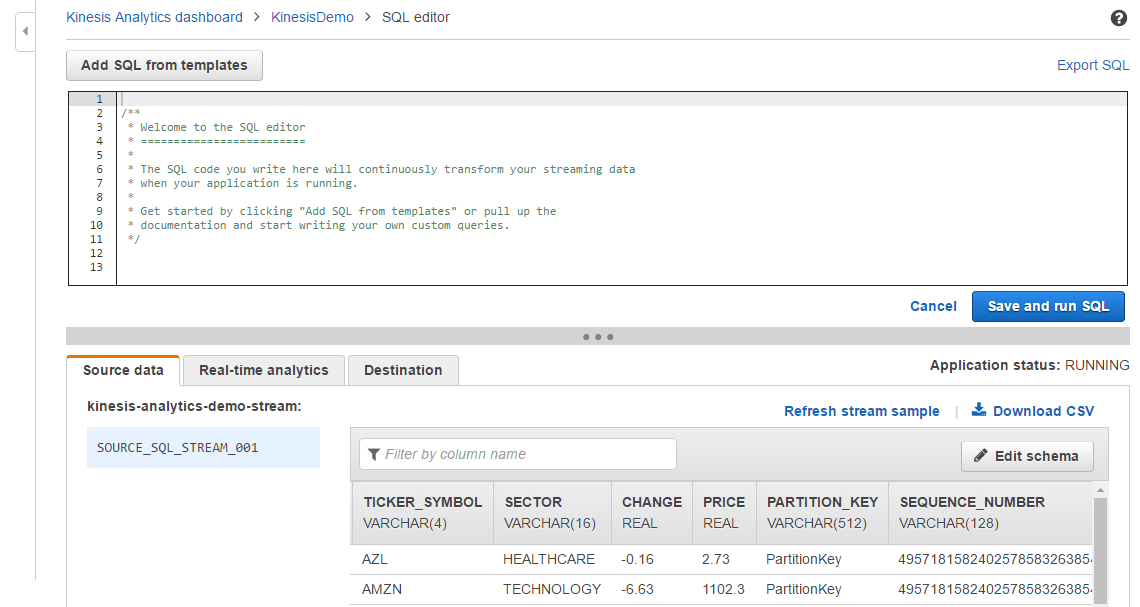
Here the SQL code can be entered and tested, there are even templates available. One modification of the “Simple alert” template would look like this:
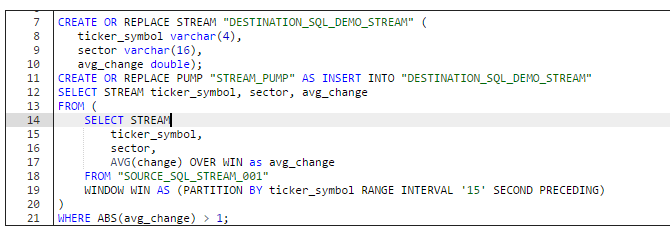
The code here is pretty much self-describing, selecting from a stream is similar like selecting from a database table, the only difference in syntax is using the keyword “STREAM”. The result of this query is a sub stream from the source stream where the average change value is greater than one in a tumbling window with a range of 15 seconds. Also the average value is being returned. The results from the query are returned in the DESTINATION_SQL_DEMO_STREAM created here for this purpose, and a pump is being used for continuously running INSERT INTO. The results can be seen in the Real-time analytics tab once the SQL has been run:
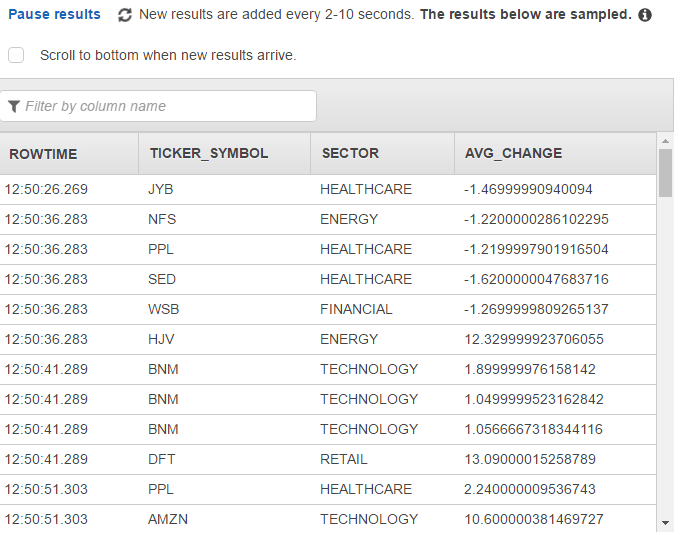
The final step would be connecting to a destination, again a Kinesis Stream or a Firehose. For this simple demo, we don’t need to do that.

As stated in the beginning the simple but complete demo application can be created in a matter of minutes, in the end, we can stop the application, it doesn’t need to run on the cloud if we don’t need it J (there is no Free Tier for Kinesis)
So how did Amazon manage to launch such a good service, usually it can take years to develop a complete event streaming platform. Well, the answer is pretty simple Amazon Kinesis Analytics is a licensed and adapted implementation of a product called SQLstream created by a company with the same name. So it’s nothing innovative but it’s very well integrated with most of AWS services and SQLstream ( company) is a proven leader in the field of Streaming Analytics (It is placed just after TIBCO and Oracle in Forrester Big Data Streaming Analytics for 2016).
To summarize Kinesis Analytics is easy to use, provides real-time processing, uses standard SQL for analytics, has automatic elasticity and one needs to pay only for what it uses just like all other AWS services. The cost is calculated in Kinesis Processing Units (KPU), representing 1 virtual CPU and 4 GB memory. One KPU hour is $0.11 in US-east-1. For example, filtering events to different destinations for a 1MB/sec stream would be ~ $80/month.