

Simple Storage Service (S3) is an online storage service that you can use to store and retrieve any type of data, at any time and from anywhere on the web. In this blog I will dive in three additions that were announced on day 1 of re:Invent 2018.
Object Lock
Amazon S3 object lock enables you to store objects using a “Write Once Read Many” (WORM) model. This feature is generally available in all AWS Regions. With this feature you can protect objects from being deleted or overwritten for a fixed amount of time or indefinitely. In order to use S3 Object Lock, you first have to enable Object Lock for a bucket.
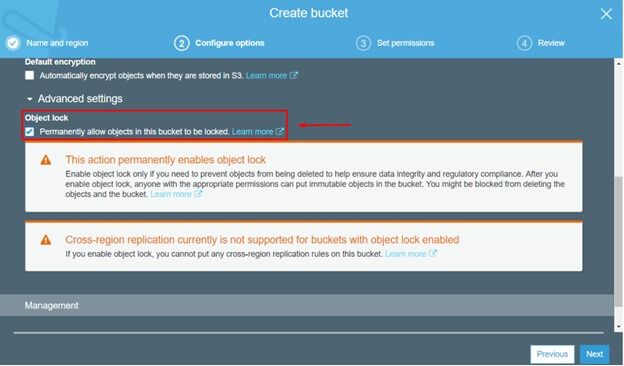
In order to manage object retention, you have two options available: retention periods and legal holds.
A retention period is a fixed period of time during which your object will be WORM protected and can’t be deleted or overwritten. There are two retention modes: Governance and Compliance. In Governance mode, users can’t overwrite or delete an object version or alter its lock settings unless they have special permissions. Unlike Governance mode, in Compliance mode, a protected object version can’t be overwritten or deleted by any user, including the root user in your AWS account.
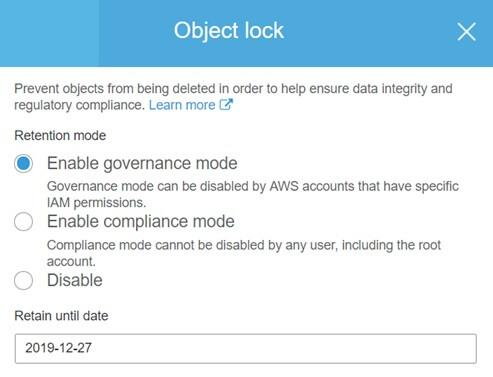
A legal hold is the same as the retention period but it doesn’t have an associated retention period which means it has no expiration date. It is independent from retention periods.
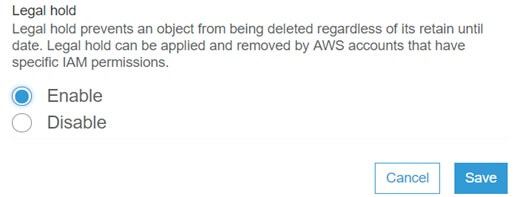
An object version can have both, a retention period and a legal hold.
Intelligent-Tiering
Now, let’s dive in AWS Intelligent-Tiering. This storage class is ideal for customers who want to optimize storage costs automatically when data access patterns change. In order to monitor access patterns and to move objects you have to pay a small monthly per-object fee. It is the best decision for data with unknown or changing access patterns. It incorporates two access tiers: frequent access and infrequent access. When you upload object to S3 and choose this new storage class, the object is placed within the ‘frequent access’ tier. If the object has not been accessed for 30 consecutive days, then AWS will automatically move that object to the ‘infrequent access tier’ which is cheaper. Once that same object is accessed again, it will automatically be moved back to the ‘frequent tier’. The good thing is that there are no additional tiering fees when objects are moved between access tiers.
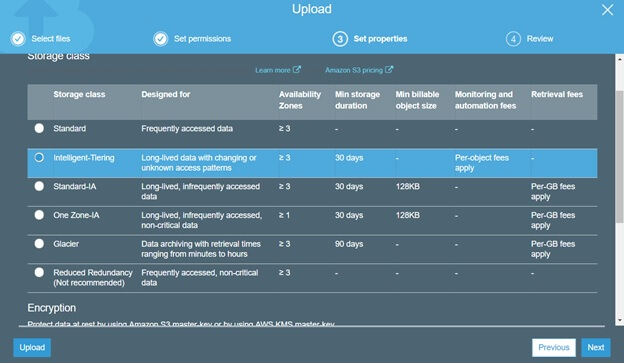
You can simply choose the new storage class when you upload objects to S3 (shown on the picture below):
Also you can create Lifecycle Rules (shown on the picture below) in order to transition data to Intelligent-Tiering storage class after certain period of time depending on your needs. Lifecycle configuration rules are ideal for objects that have a well-defined lifetime.
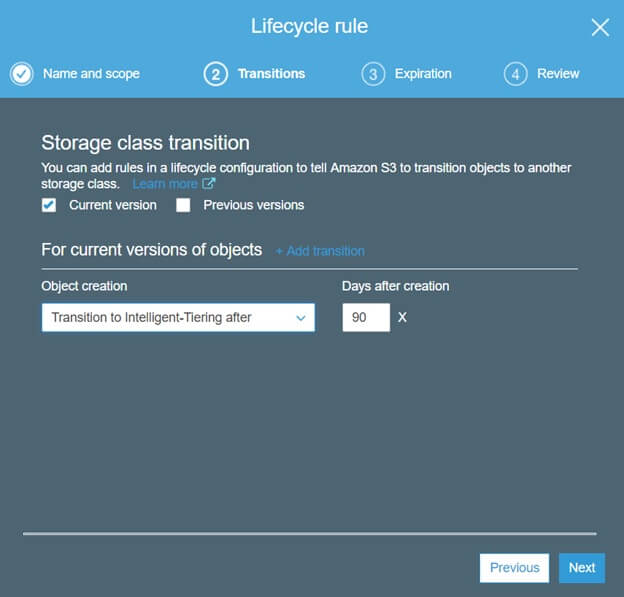
The Intelligent-Tiering storage class is designed for 99.9% availability and 99.999999999% durability.
Batch Operations
In my opinion, this announcement is an ideal decision if you want to perform large-scale batch operations on Amazon S3 objects. In order to do this, you have to create a batch job which means you have to specify the operation that you want Amazon S3 batch to perform on all objects listed in the manifest. You can use an Amazon S3 Inventory report as a manifest or use your own customized CSV list of objects.
Amazon S3 batch operations support the following operations:
- PUT copy object
- PUT object tagging
- PUT object ACL
- Initiate Glacier restore
Each operation type accepts parameters that are specific to that operation which means you can perform the same tasks as if you performed the operation one-by-one on each object. You can create more than one job and depending on your needs you can prioritize them in any way that you want but you have to keep in mind that strict ordering isn’t guaranteed. In order to ensure strict ordering you have to wait until one job has finished before starting the next.
Batch operations use the same Amazon S3 APIs that you already use. You can also perform these operations using the AWS CLI and AWS SDKs. S3 Batch Operations are currently in preview but will be available in all AWS commercial and AWS GovCloud (US) Regions.
Conclusion
To sum up, these three announcements are the most important and unmissable storage features that were announced by Amazon in order to make the managing of billions of objects stored in Amazon S3 easier for customers and to optimize storage costs.