


In this article we will continue our story about the development of our custom snaps for the SnapLogic platform. When I started working on the SnapLogic platform I was always interested to know how the snaps are developed and what the code behind them is. While working on the development of pipelines using SnapLogic’s platform I encountered some scenarios where the need for some particular snaps made me think more about developing custom snaps for specific scenarios.
I have chosen one scenario for development that will be explained in the article, and I believe it is simple and understandable.
Let’s say we have 3 main steps in a pipeline and our requirements are that all of the steps need to be executed. In the first step we have MySQl Select which is selecting some records from a database, then in the 3rd step we are executing some query with multiple statements and in the final snap we are just inserting some records into the database.
The problem with this case is that if the first MySQL Select snap does not return any data, nothing will get executed after that, which is not according to our requirements i.e. that all snaps/steps need to be executed.

We were using a work-around for this particular scenario which includes using a JSON Formatter snap with the Ignore Empty Stream checkbox unchecked connected to a Binary to Document snap in between each of the MySQL snaps.

This means that if the data is returned from the MySQL Select snap, that data will be JSON formatted and converted back to Document format using the Binary to Document snap which means the data would pass through onto the second MySQL snap and so on. But if no data was returned from the MySQL Select snap (like in the picture above) the JSON Formatter snap will always produce some data which will reset the flow and execute the next snap in the pipeline without any data required from the previous snap. As you can see this is not a good example on how to build the pipelines and it is missing the point of the SnapLogic’s platform which is its ease of access and having a connector for a simple function like this.
When the opportunity presented itself I immediately wanted to develop a custom snap with the name Flow Reset which will tackle this scenario.
I am assuming you have all of the requirements set up for starting the development of the custom snaps. If you don’t, I recommend that you read our previous article written for the custom sleep snap where we talk more in depth about setting up the environment, and all the necessary stuff for custom snap development as well as some basic things to know prior to starting the development of custom snaps.
Defining Snap Anatomy

We can see from the picture above the snap name is defined to be “Flow Reset”, also we have set up the snap to have a minimum of 0 input views and a maximum of 1 input view and to have 1 output view, of course this can be configured to our desires. The Flow Reset snap will be of READ Snap Category.
Setting Up the defineProperties and Configure methods
Define Properties

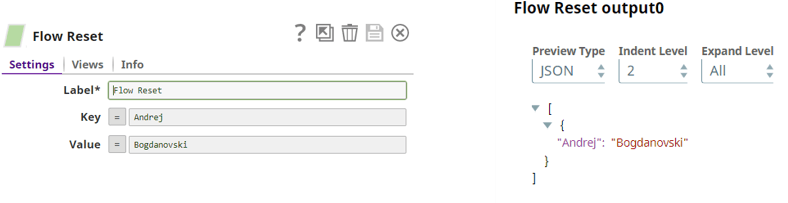
Like we mentioned in our previous article, the defineProperties is defining the snap properties using the given Property Builder. In our case in the defineProperties method we are defining two input variables, Key and Value. The purpose of these variables is to create an output which is defined by the user even though an input data is not present.
Example:
If you leave these fields empty and no data flows on input of the Flow Reset snap, the default values will pass through on output for the two fields which are: “Start” for the Key field and “Flow” for the Value field.
As you probably saw in the pictures we can define expressions as values for the fields. In the code with the .add() method we are enabling the options to add values for the two fields and with the .expression() we are enabling the option to add expressions for these fields. You might have also noticed that we don’t have the .required() method because it is not mandatory to put values for these fields because we have default values for both of these fields in case there is no value by the user.
Configure Method

Next in the configure method we are configuring the snap with the property values provided by the user’s input.
This code is simply checking if there is no data on input for the fields and if so, it will declare the default values for each of these fields. If the user placed some value it will take that value and declare it to the variable key/value.
Execute Method
After we have defined and configured all of the properties for the snap we are continuing to the main method that is the execute method.

First, we are checking if the input views of the snaps are greater than 0. If the condition is false that means that there is no input view open on the snap and we can output the values that we defined in the Key Value fields.
If the input view size is greater than 0 then we are taking the documents from that input view using the .getDocumentsFrom() and we are declaring it as a Document. Next we need to check if there is any data on input, we are doing that with the .hasNext() method. If there is no data on input the value for the count variable will be 0. If there are records on input then the counter will increase by 1.
We are using that count variable to check if the value is 0 then that means that there are no records on the open input view of the snap and we can output the data that is in the Key Value fields. If the count variable is not 0 that means there are records on the input view of the snap and we are executing the block of code after the else statement. Hence, the Map function is used in combination with the write method which will create an output data based on the input records.
Testing

The requirement for this pipeline is to execute all of the steps. As you can see in this example no data was returned from the My SQL Select snap and nothing got executed after that, and that is not what we want.

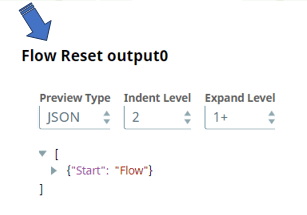
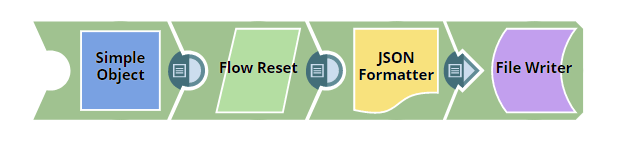
In this next pipeline you can see the Flow Reset snap is doing its job and it is actually resetting the flow of data when no input data flew through the MySQL Select snap. We did not specify any values for the Key and Value fields in this case and it passed through the default values for the Key and Value fields which are Start and Flow.
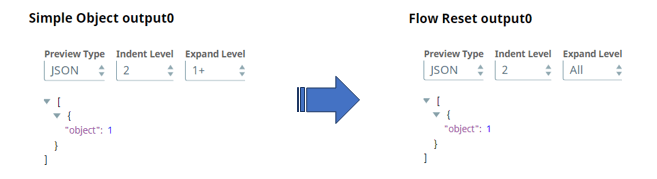
Let’s see an example where we have data on input of the Flow Reset snap. In this next example we have an object with the value of 1 on input of the Flow Reset snap.
As you can see the data just passed through the Flow Reset snap. Also the Flow Reset snap is tested and working with different Json structured data on input.
Conclusion
This is another simple snap that we developed that will be of use in some scenarios. It is really simple and it can certainly be improved. We have some idea of adding suggest in it and few other configurations, but that is not on the priority list for now. Feel free to reach out to us, if you want to discuss this in details.