

Introduction
Message recovery is a commonly used term that holds significant importance in IT. It refers to the process of repeating a previously triggered instance or job in its original form, starting from the initial point of failure. This occurs when a process or job fails to complete successfully due to unforeseen circumstances such as unexpected behavior or temporary outages of external services.
When it comes to recovering from exceptions and reprocessing failures, MuleSoft offers various approaches that can be tailored to meet specific business needs and functional requirements.
One of the options available is Mule’s built-in solution called the “Until-Successful” scope. This static and configurable scope allows us to set the number of retries and the delay between each retry. It is useful in scenarios where the underlying service is temporarily inconsistent and may return unfamiliar errors. The “Until-Successful” scope provides a simple and effective way to handle such cases.
Another approach is using the Try-Catch scope, which is similar to the exception handling mechanism in Java programming. With the native error handling capabilities provided by Mule, we can gracefully handle exceptions and reroute messages based on specific conditions. The Try-Catch scope enables us to define custom error handling logic and efficiently process messages in different scenarios.
In our use case, we will explore two custom “message recovery” solutions that we have implemented in various scenarios. These solutions allow us to control the message flow based on configurable properties and dynamically determine the state of messages using DataWeave expressions.
It’s important to note that “message recovery” refers to “Messaging Errors” where the process instance has been already triggered unlike the “System Errors” which occur at the system level which are controlled by Mule engine.
Solution
Common Reprocess Scope
In order to handle various message exceptions within inconsistent behavior of the External Services we have used common reprocessing scope attached as Mule Shared Library where all Mule applications across CloudHub domain or Anypoint Virtual Private Cloud can reuse it.
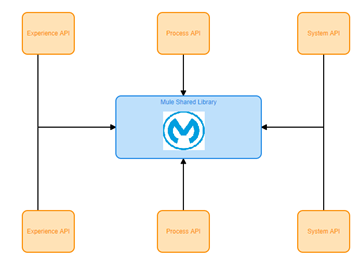
Irrespective of the design pattern, methodology, or building block incorporated into our workflows, we can always leverage the out-of-the-box solution with a custom retry mechanism.
Additionally, we have the capability to store failed messages for future processing. This can be achieved by utilizing a relational database management system (RDBMS) storage or leveraging the built-in caching option provided by Mule. Storing failed messages allows us to retry them at a later time, ensuring that critical data is not lost and processes are not interrupted.
From a business perspective, one of the scenarios we encounter involves checking the current state of invoices in the backend warehouse service. This step is crucial as it helps us determine the severity level and prepare for payment of specific products. By integrating with the backend warehouse service, we can ensure accurate and timely processing of invoices, enabling smooth payment transactions.
Circuit Breaker
In this particular use case, we encountered a situation where the backend service experienced a significant overload, resulting in frequent occurrences of Internal Server Error along with immutable exceptions.
The overload in the backend service caused disruptions in the normal flow of operations, leading to failed requests and error responses. This presented a challenge in ensuring the reliable processing of messages and maintaining the integrity of our system.
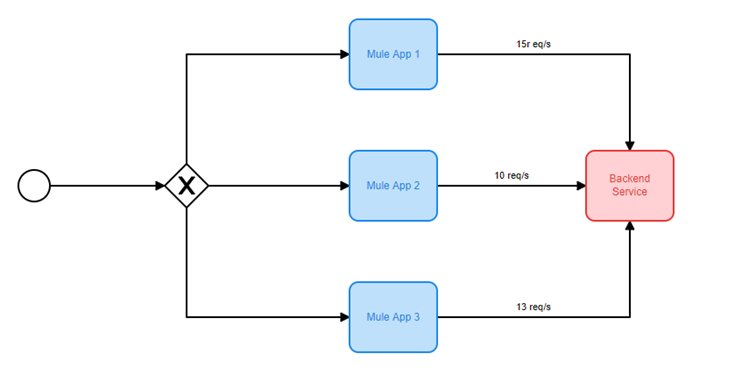
Faced with the urgency of the situation and the need to address the high volume of failed messages, we swiftly implemented a practical solution to ensure the continuous operation of the backend and alleviate the throttling issues.
In order to achieve this, we decided to adopt the Circuit Breaker pattern, a well-known resilience pattern in the world of software development. By periodically monitoring the state of the backend service, we were able to respond effectively when encountering recurring exceptions. The Circuit Breaker pattern allowed us to transition between different states – open, half-open, and closed – based on the observed behavior of the backend service.
In the open state, we responded with a generic message, preventing further requests from being sent to the overloaded backend. During the half-open state, we cautiously allowed a limited number of requests to flow through, monitoring the responses for any signs of recovery. Finally, in the closed state, normal operations were resumed as the backend service returned to a stable state.
DEMO
Common Reprocess Scope
At this stage we will dive deep into the implementation and illustrate common reprocessing library that we have used specifically for following use case.
We have a scenario where we have a warehouse environment and we are checking the status of the invoice.
We have three Mule applications:
- mule-iw-application-server
- mule-iw-application-client
- common-iw-library
Server Application
In the mule-iw-application-server, which represents the invoice data warehouse, we have the flow named apiFlow_Invoice that handles requests for invoice from the client application.
The flow has an HTTP listener serving as the source, configured with the path “/checkInvoice”.
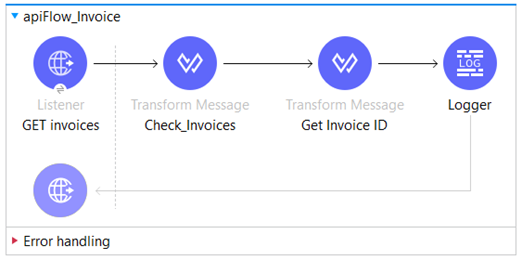
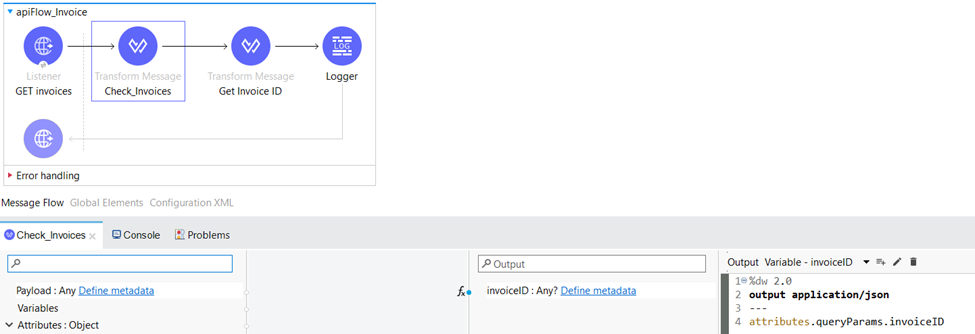
In the Transform Message component “Check_Invoices“ we retrieve the contents of the Cus_Invoice.json file located in the classpath and we assign its content as the payload for further processing.
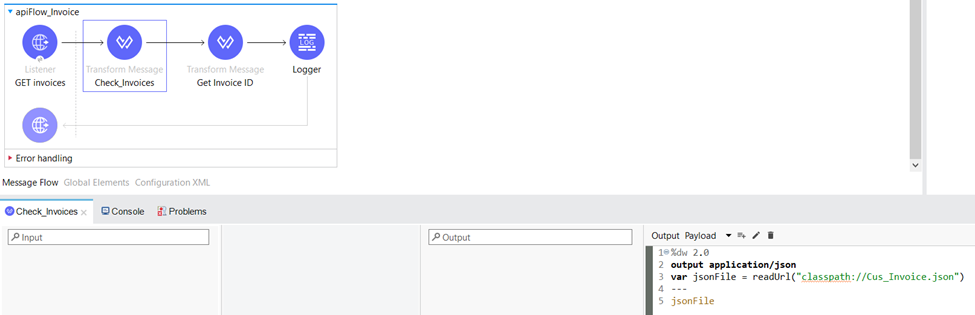
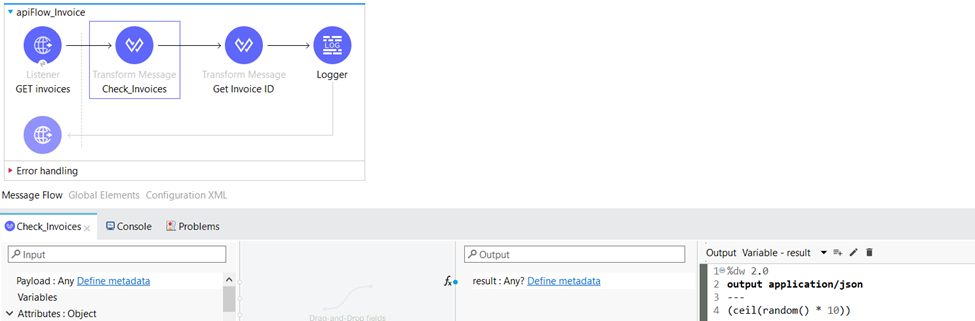
Within the Transform Message component, we employ various data manipulation techniques to extract and process relevant information. Firstly, we retrieve the value of the invoiceID query parameter, storing it as the variable “invoiceID”. Additionally, we generate a random number between 1 and 10, which is then rounded up to the nearest whole number. This resulting number is saved as the variable “result”. These operations enable us to capture and manipulate data dynamically, facilitating further processing and analysis in our workflow.
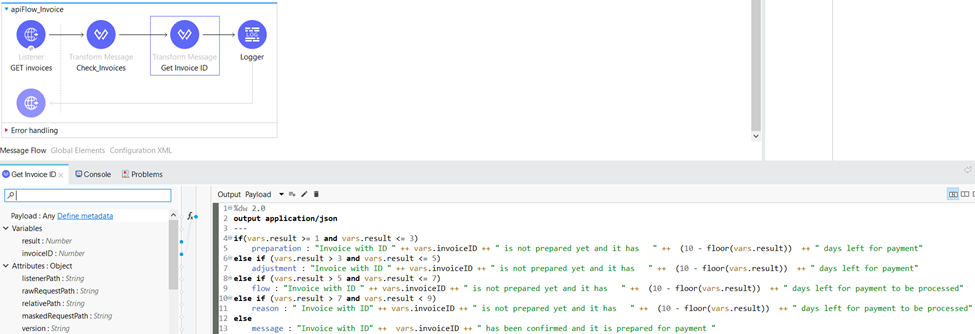
Within the “Get Invoice ID” Transform Message component, we leverage the previously generated “result” variable obtained from the “Check_Invoices” Transform Message component. The status of the invoice is determined based on the value of the “result” variable. In this particular scenario, specific messages are assigned depending on the range in which the value of the “result” variable falls. This enables us to handle and process invoices dynamically based on their corresponding status, ensuring efficient and accurate message handling within our workflow.
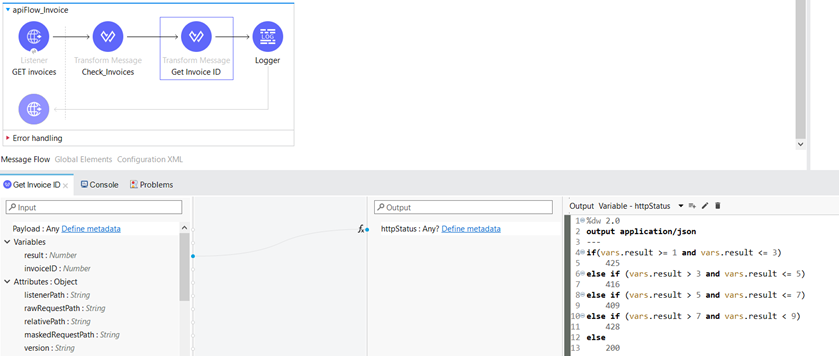
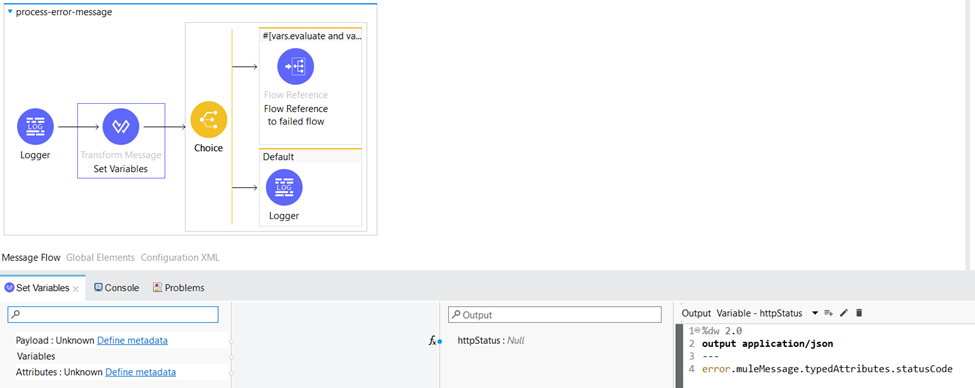
We also set the httpStatus in the same Transform Message component depending on the “result” variable.
For each status of the invoice we have a specific HTTP status code:
- 425 – Invoice is in preparation
- 416 – Invoice is being adjusted
- 409 – Invoice is in state “flow” (processing)
- 428 – Invoice is almost completed
- 200 – Invoice is confirmed
If the HTTP status code received is anything other than 200, it indicates that the invoice is not yet confirmed and is undergoing preparation, adjustments, processing, or nearing completion. In these situation, the httpStatus corresponds to specific HTTP response status codes, namely: 425, 416, 409, or 428. In such cases, we have implemented a reprocessing mechanism in the common-iw-library to recheck the confirmation status of the invoice.
Client Application
In the mule-iw-application-client we have a flow which is used to send an HTTP request to the mule-iw-application-server. The purpose of this request is to retrieve an invoice from the server.
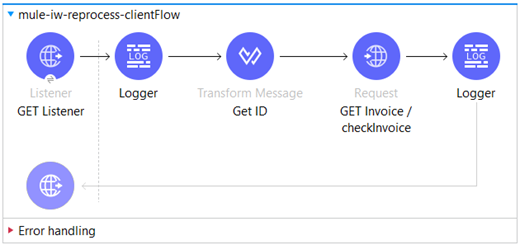
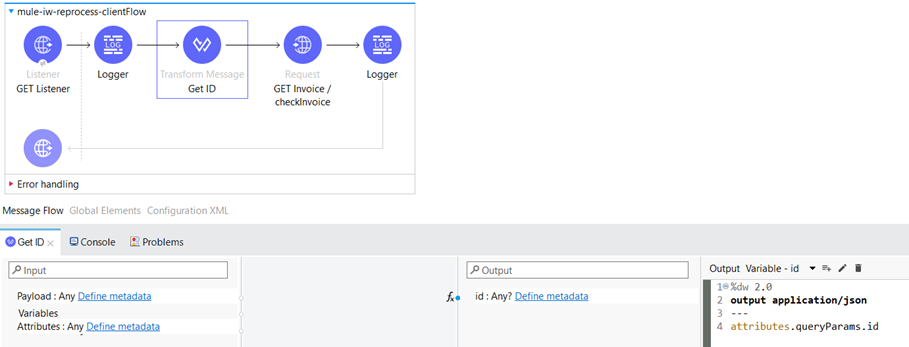
The path for the HTTP listener is configured as “/resource”. Within the Transform Message component, we extract the value of the query parameter “id“ from the request and store it as a variable named “id“.
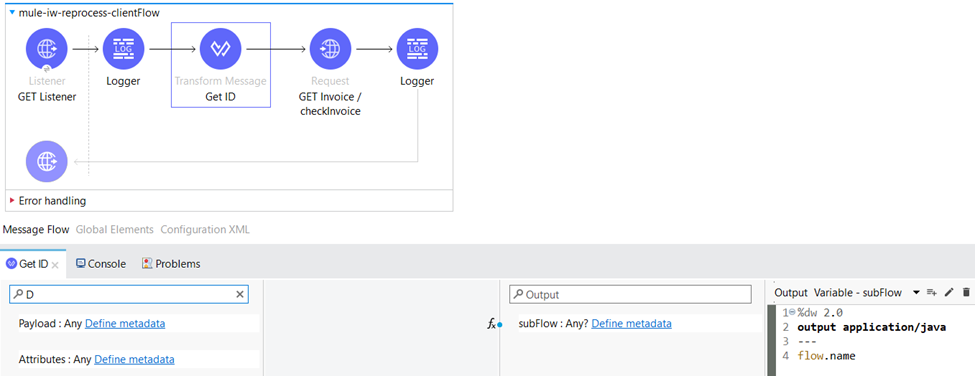
We also save the subflow name as variable in the same Transform Message component.
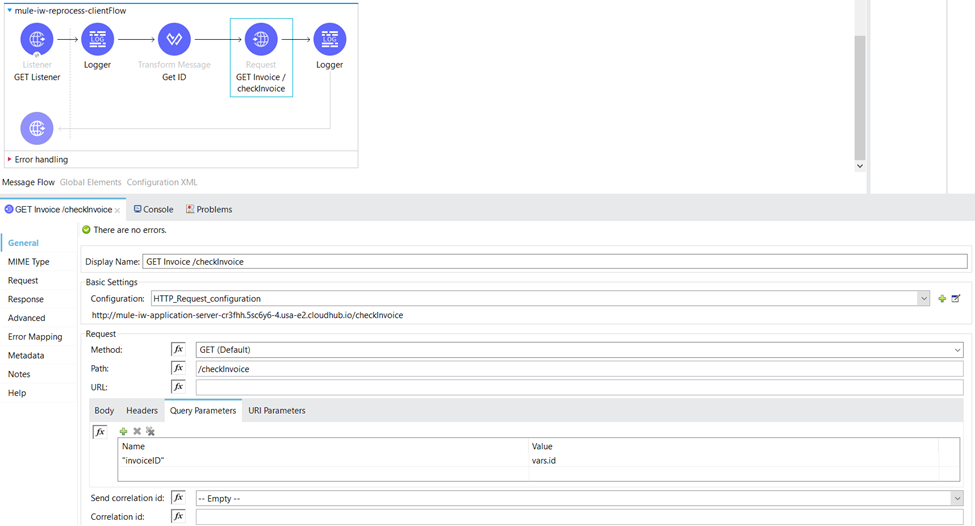
Next, we have an HTTP Request component that has been set up to communicate with the server in order to fetch an invoice. Hence, we are specifying the endpoint of the Mule Service Provider “/checkInvoice” and a query parameter called “invoiceID” to uniquely identify the desired invoice.
Common library
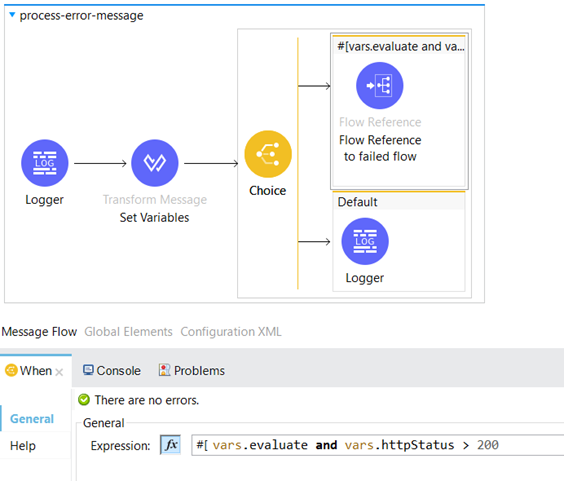
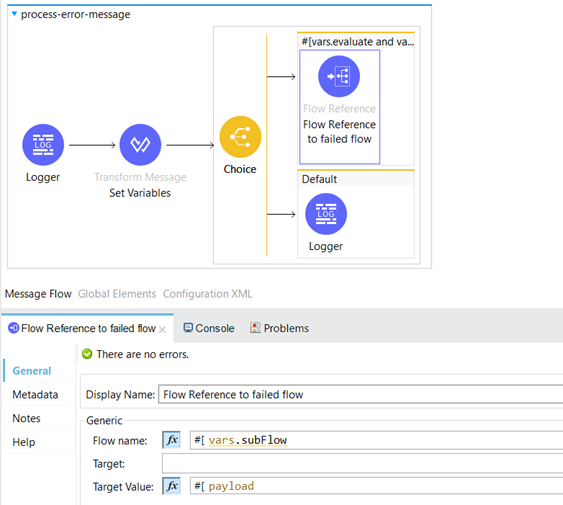
In the common-iw-library we have an error handler with On Error Continue scope which includes a Flow Reference to process-error-message subflow.
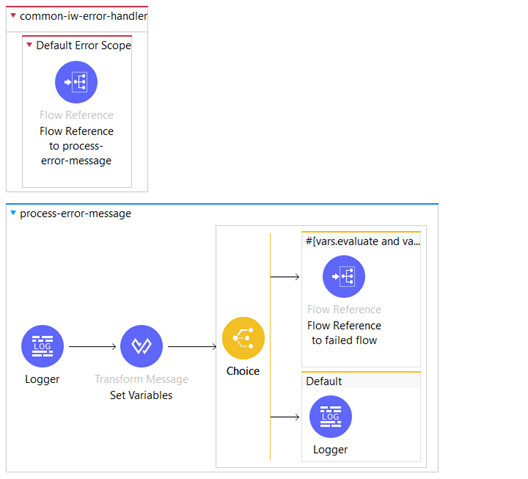
In the process-error-message subflow we set the “httpStatus” variable to error.muleMessage.typedAttributes.statusCode which is used to retrieve the HTTP status code associated with an error.
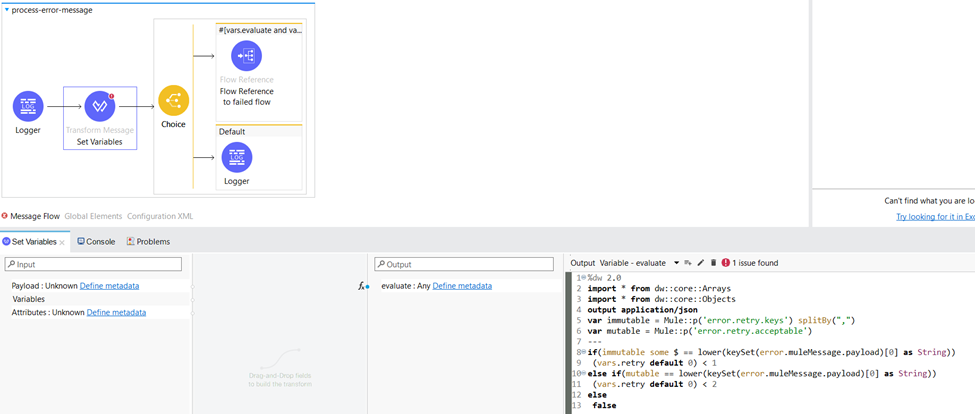
The following DataWeave code can be used to determine whether an error should be retried based on the error codes and keys associated with the error. The conditions in the DataWeave code define the retry criteria and the output is saved in a variable named “evaluate”.
If the invoice is in preparation, being adjusted, processed, or almost completed and hasn’t been ever retried (the first condition) or it has been retried once (second condition) then the value of the “evaluate” variable will be true.
Here is the content of the property file:

Here we set the “retry” variable which represents the number of retries.
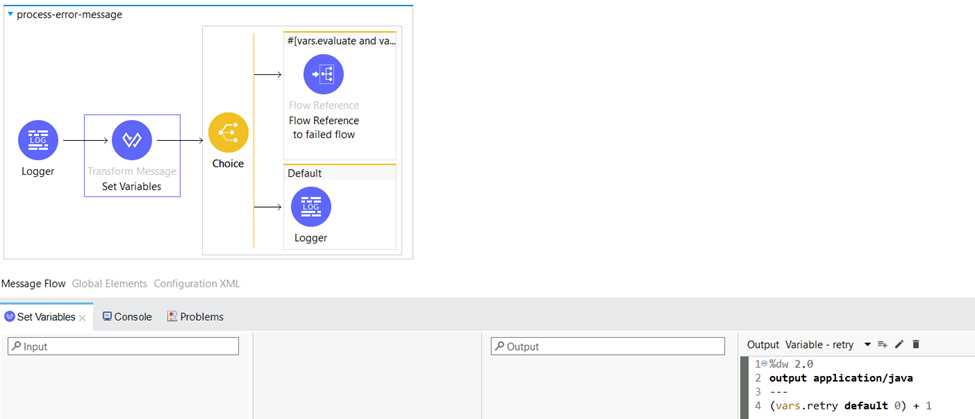
The “evaluate” variable (true or false) and the value of the httpStatus can be used to trigger the appropriate reprocessing logic. If this condition evaluates to true then the message will be reprocessed.
Circuit Breaker
Circuit breaker pattern is commonly used across digital transformation and especially in Microservice architecture which indicates monitoring and handling the number of failures occurring at specific period of time.
Since MuleSoft does not have in-house solution for Circuit Breaker pattern, we have decided to create our custom functionality which will keep save the upstream service from outage and save the memory resources of redundant long running instances in our memory brittle and fragile applications.
Server Application
The server application functions as a warehouse, containing data about products and customers. It serves as a handler for requests originating from the client application. Within the server application, there are two distinct flows: “apiFlow_products” and “apiFlow_customers.” These flows are responsible for managing and processing requests related to products and customers, respectively.
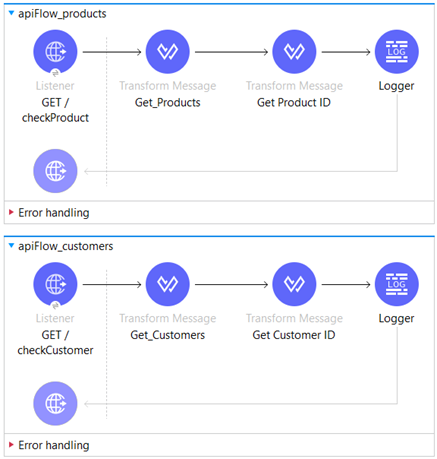
Let’s dive into the details of the “apiFlow_products” flow.
This flow begins with an HTTP listener, which acts as the source and is set up with the path “/checkProduct”.
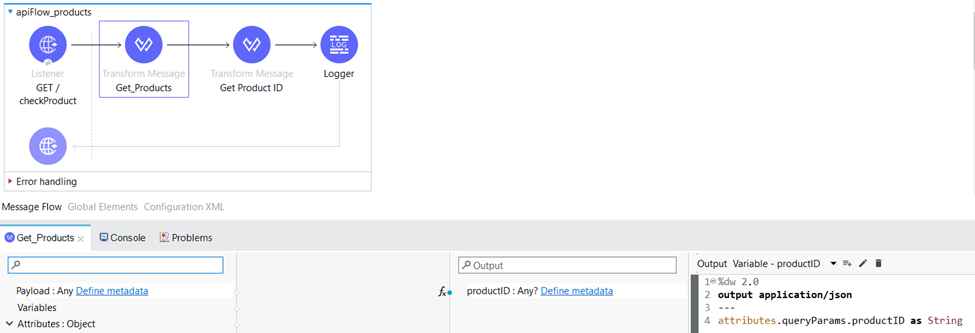
In the Transform Message component named “Get_Products”, we extract the data from the “Products.json” file located in the classpath. Subsequently, we assign the retrieved content as the payload for subsequent processing within the flow.
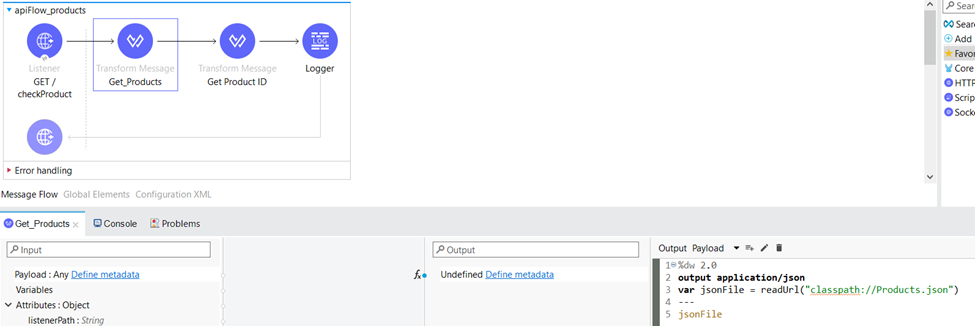
Within the same Transform Message component, we do not only extract and save the value of the productID query parameter as “productID,” but we also utilize a DataWeave code snippet to generate a random boolean value. This boolean value is then assigned to a variable named “criteria” for further use within the flow.
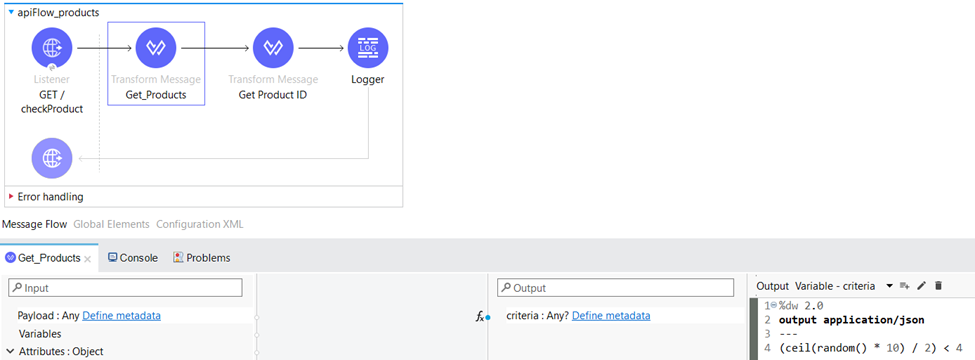
In the “Get Product ID“ Transform Message component, we use the previously generated “criteria“ variable from the “Get_Products“ Transform Message component in our logic.
The “criteria” variable plays a crucial role in determining the availability of the product within the warehouse. By evaluating if the randomly generated number is less than 4, we establish a condition that results in an 80% probability of evaluating to true. This criterion is then utilized to trigger an error message or perform other actions within the workflow. Within the “Get Product ID” Transform Message component, specific messages are assigned based on the condition specified, enabling us to handle different scenarios and responses based on the product’s availability.
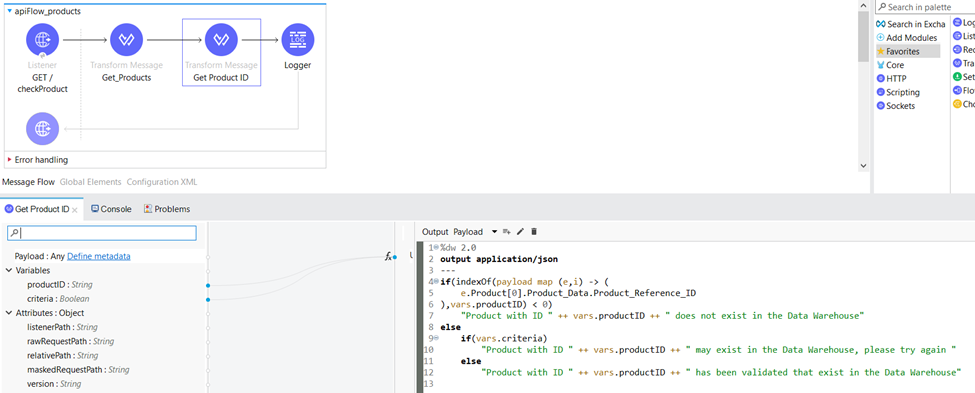
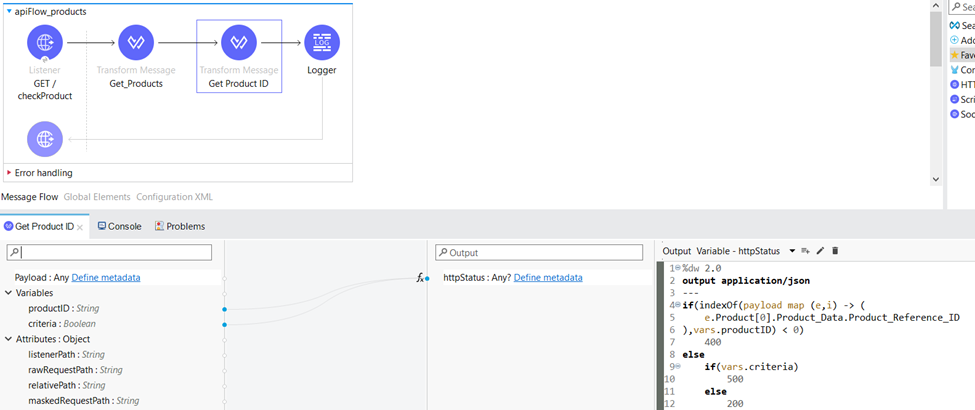
Within the same Transform Message component, we set the httpStatus variable. For each distinct HTTP status code, we provide a specific reason or explanation associated with it:
- 400 – Product does not exist in the warehouse
- 500 – Product may exist in the warehouse, so the request can be retried
- 200 – Product has been validated that exist in the Data Warehouse
The implementation for “apiFlow_customers” is identical to that of “apiFlow_products”, with the only difference being that it is used to verify the availability of customers instead of products.
Client Application
We have implemented the Circuit Breaker pattern in the client application mule-iw-application-client.
We have two scheduled flows that execute at regular intervals of 5 minutes (we are aligning the interval based on the demand of the application and throughput volume).
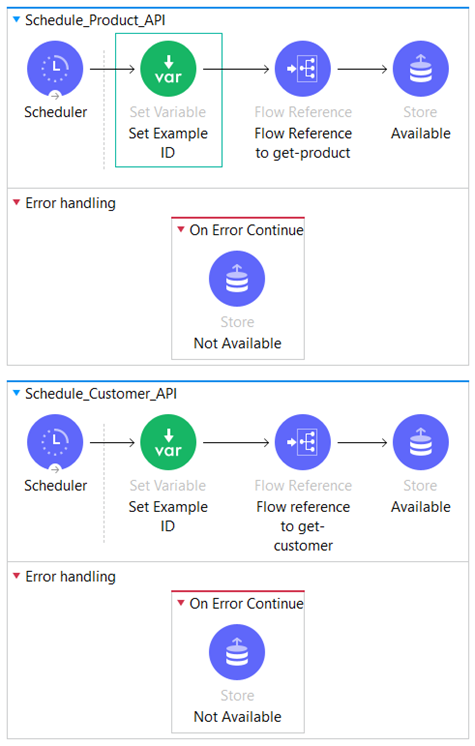
The primary objective of these scheduling flows is to monitor the availability of upstream services, specifically the Mule Service created earlier, and dynamically switch the workflow’s state between Closed, Half-Open, and Open.
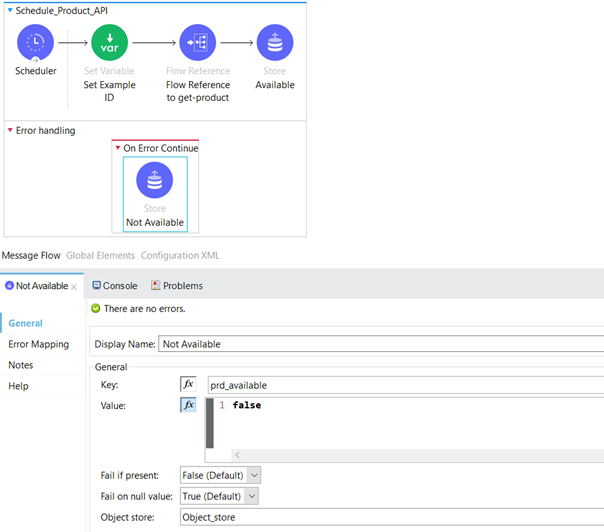
Now, let’s dive into the details of the “Schedule_Product_API” flow. In this flow, we begin by initializing the “ID” variable, which is assigned a hardcoded value representing a product that we know exists in the system. This serves as a starting point for the subsequent steps in the flow.
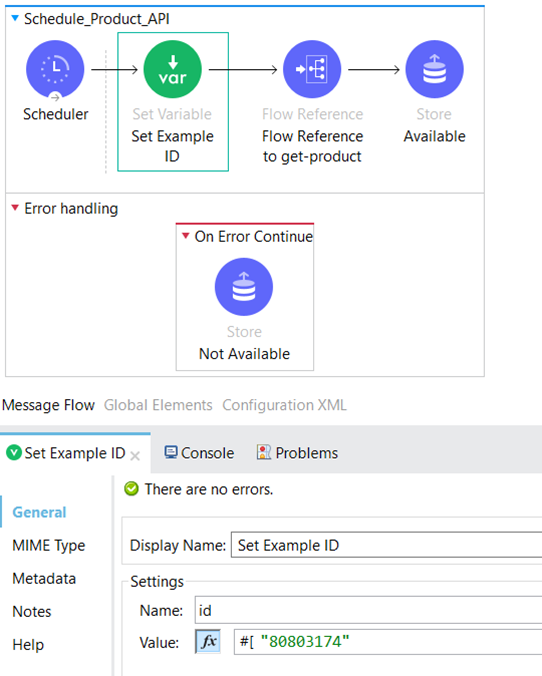
Following that, we have a Flow Reference component that directs the flow to the “get-product-api” subflow.
Within the “get-product-api” subflow, we initiate a request to the server application to verify the existence of the specified product.
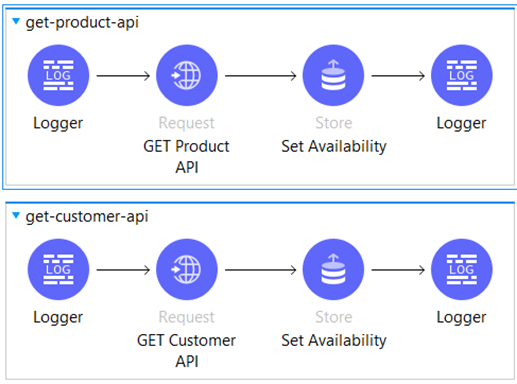
In the event that the API is operational and running smoothly, we update the “prd_available” key in the Object Store to a value of true, indicating that the API is in the Closed state. This allows other processes to utilize this resource effectively. However, if the API is unavailable due to reasons such as an outage, high CPI memory, or system overloading, we respond with a 400 or 500 HTTP status code (in our case, based on the “criteria” generated random variable within the Server Application). This triggers the server to switch to the Open state, indicating that the API is currently unavailable for processing requests.
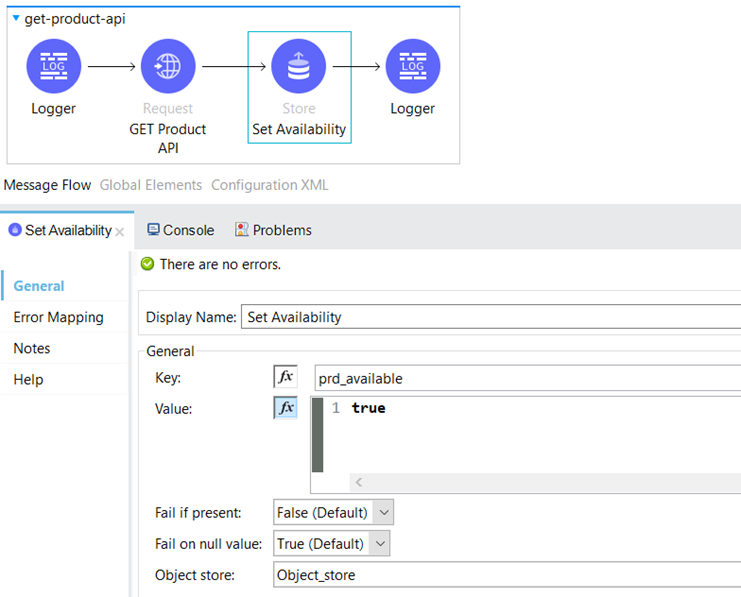
In case we receive a 400 or 500 HTTP status code, the request is directed to the Error Handling Section within the On Error Continue Scope. As part of the error handling process, we set the Object Store key “prd_available” to false.
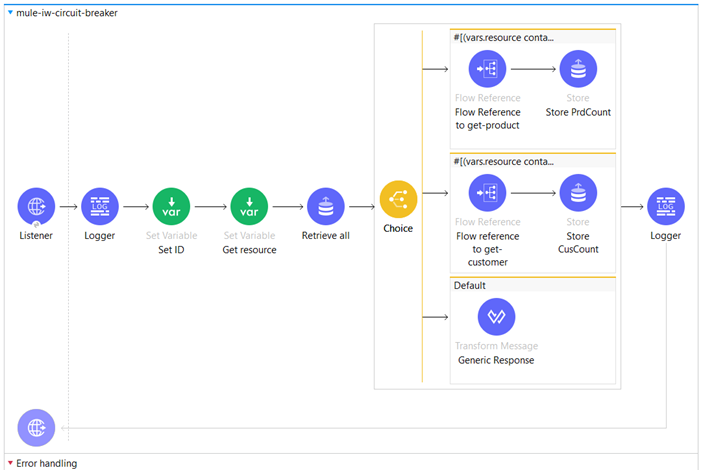
Here is our primary flow, known as the “mule-iw-circuit-breaker” flow.
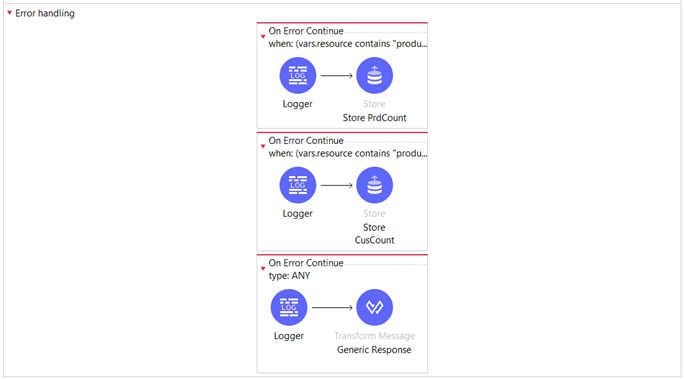
This represents the error-handling segment of the flow:
The flow begins with an HTTP Listener serving as the source, configured with the path “/checkResource”. We have saved the values of the “id” and “resource” query parameters as variables for further processing.
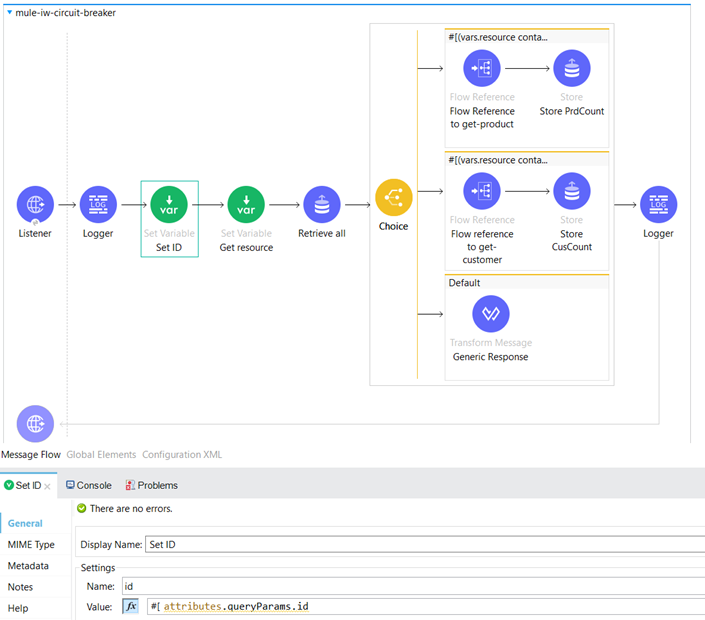
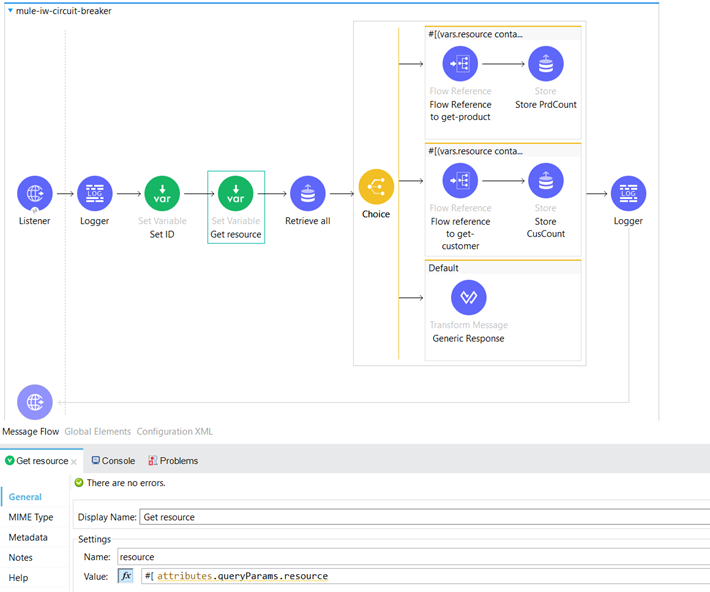
Here we retrieve all keys and their values present in the Object store.
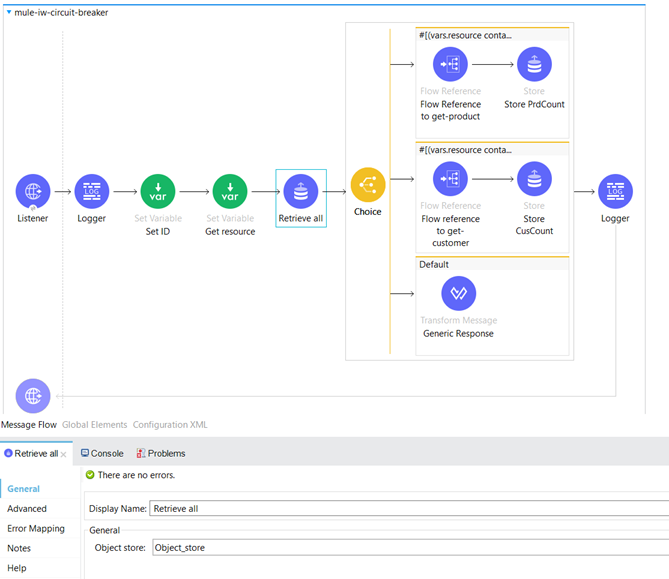
Next, we have a conditional statement where we check whether the “resource” variable contains the term “product”. This condition enables us to determine if the incoming request is related to checking the availability of a product and subsequently verifies if the specified product is currently available.
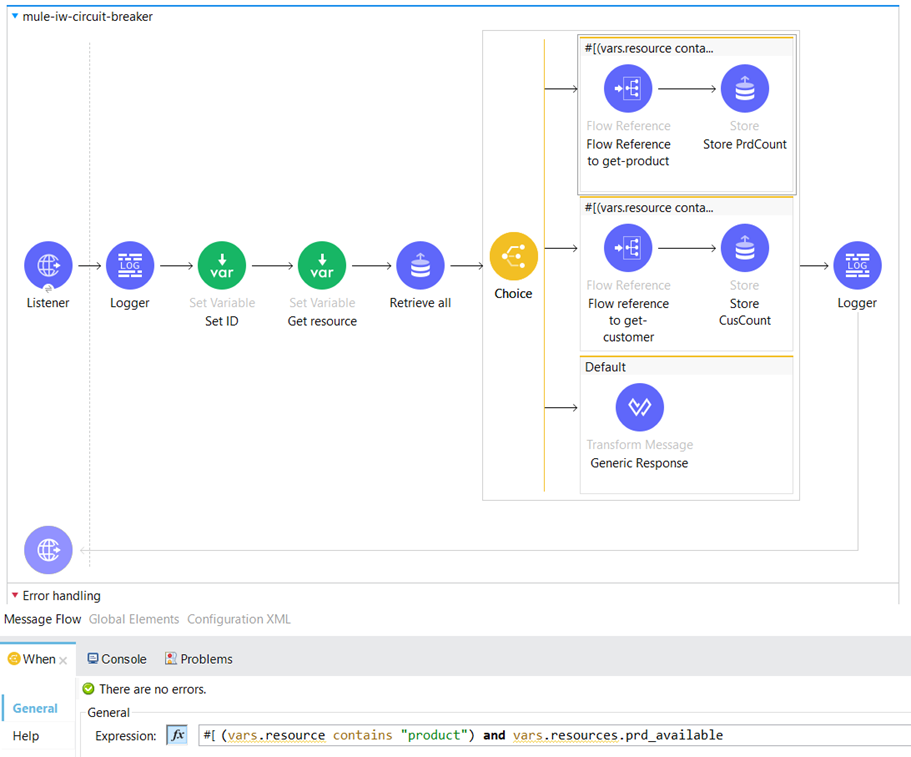
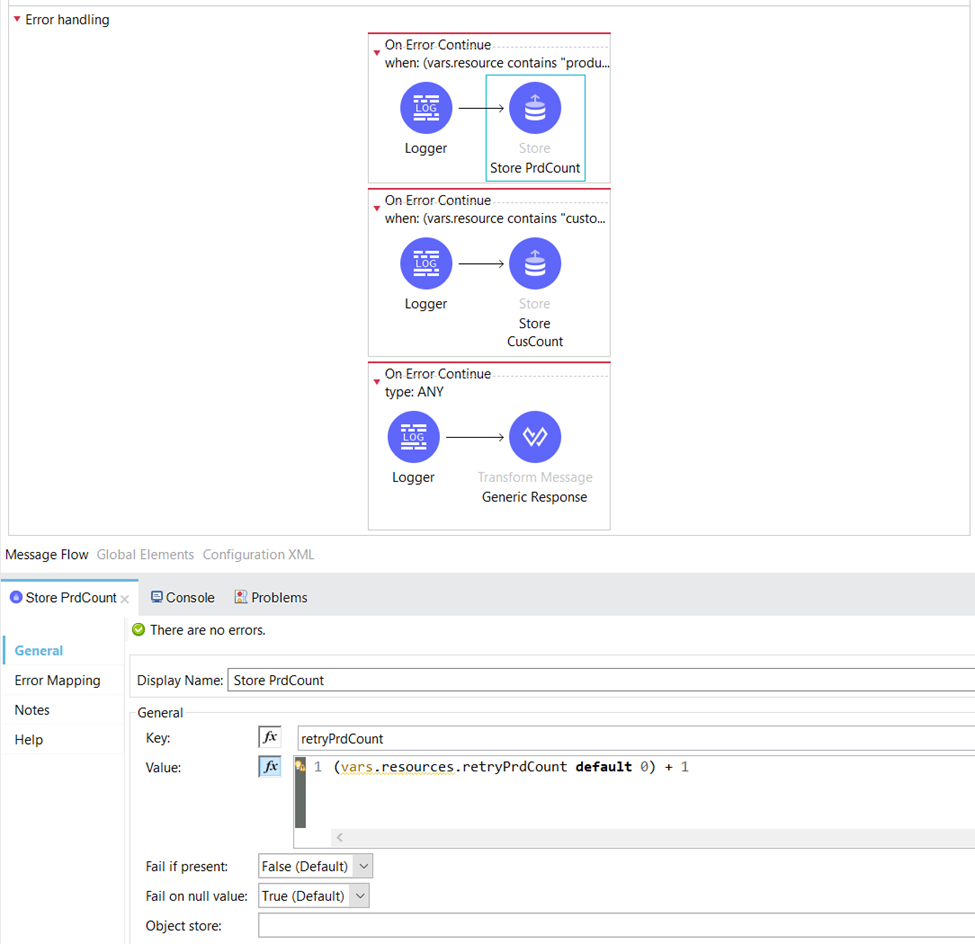
If the server application confirms the availability of the product, indicated by returning an HTTP status code of 200, we proceed to update the “retryPrdCount” key in the Object Store and set its value to 0. This indicates that there have been no retries for the product and it is ready for further processing.
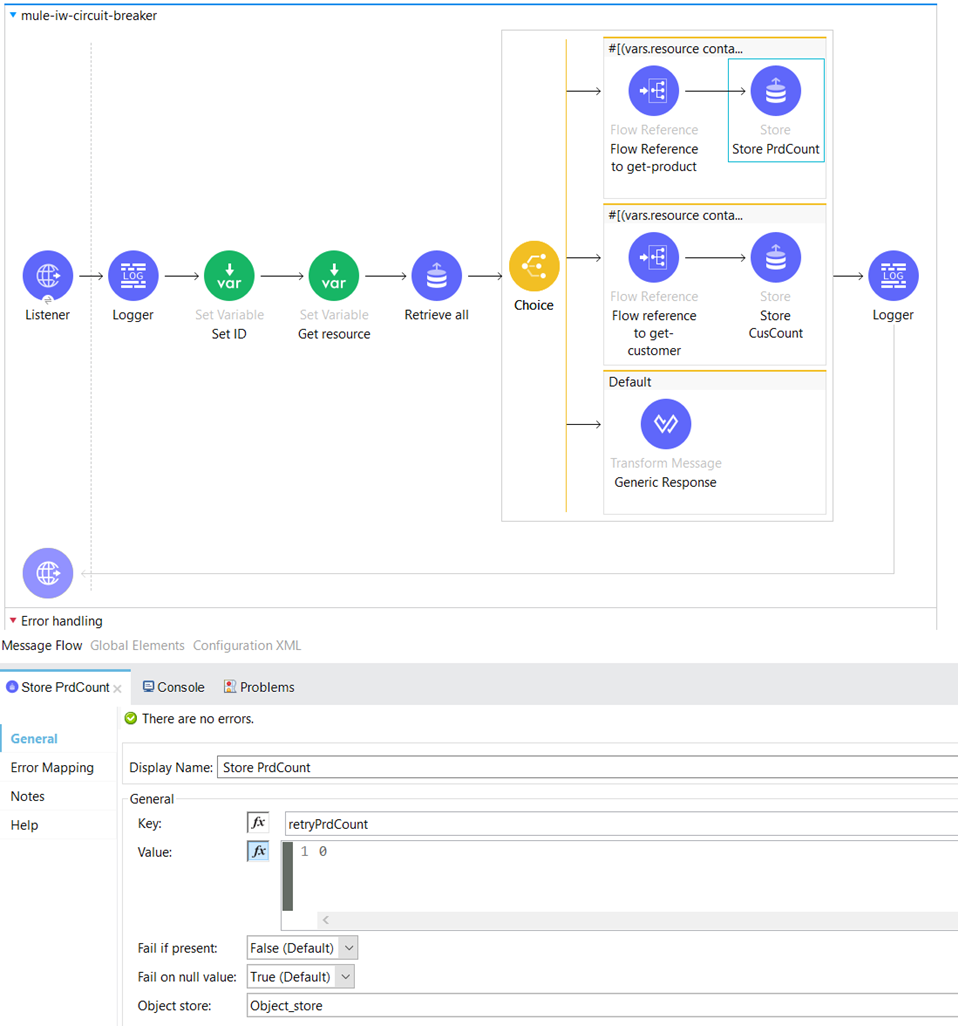
If we get HTTP status code 400 or 500 from the server application then the request routes to the Error Handling part of the flow, in the first On Error Continue Scope where this condition is set:
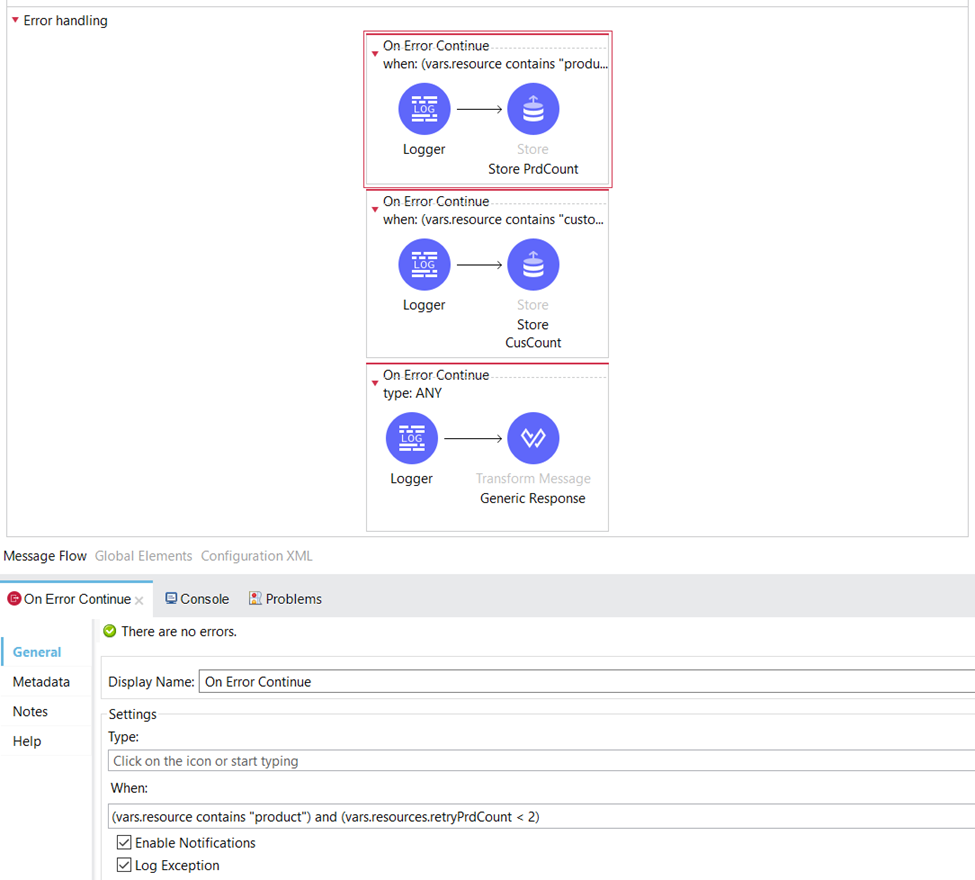
There, we increase the value of the retryPrdCount by 1.
The same implementation applies to checking the existence of a customer. If we keep receiving errors from the Backend Server, after the third retry and incrementing the retry variables, the flow is routed to the default error handler. In this error handler, we have set a generic response indicating that either the Inventory or Customer Resource Management is currently unavailable. This approach helps us avoid throttling the backend and allows us to wait for the scheduling services to check the state of the APIs before transitioning from the Open state to Half-Open, and finally to Closed.
Conclusion
There are still numerous other approaches for message recovery in Mule that we haven’t discussed in this blog post. However, it’s worth mentioning that Mule’s built-in caching capabilities allow us to customize the message reprocessing based on specific business requirements and adjust the error handling accordingly.
In this section, we have described our custom solutions for message recovery in MuleSoft. Initially, it was a challenging task from a functional perspective as we aimed to create reusable solutions applicable to all applications and covering the most common scenarios. However, the effort paid off, as our solutions successfully addressed all possible error scenarios. Particularly, the Circuit Breaker custom solution served as an additional layer for efficient memory usage across the domain.
If you would like more information about custom Mule solutions, please don’t hesitate to reach out to us. We would be happy to provide further assistance.