
Introduction to Error Handling in SnapLogic
Errors may occur in every program, integration, code snippet, server, and so on for many different reasons. Syntax, semantics, logical, run-time, and Compile-Time problems can cause errors, for example. The main purpose of “Error Handling” in an integration project is to have a common way to handle errors without losing data or disrupting the system.
Every data engineer developer knows that SnapLogic offers many ways to develop a common error handling framework. We’ve leveraged the SnapLogic platform to create the best error handling solution for every project. In this article, we’ll show you some SnapLogic Patterns – pre-built integration templates – we’ve developed. We’ll explain the common framework logic behind the Patterns, the pros and cons of each Pattern, and ways to implement the Patterns.
First, we’ll briefly cover the existing ways you can catch and resolve an error in a pipeline with SnapLogic.
Stop Pipeline Execution
When an error occurs, the default error behavior on a Snap level is “Stop pipeline execution.” As the name suggests, this function will stop the current pipeline execution when an error arises. In the example below, the Mapper Snap (pre-built connector) has a wrong expression setup which will generate an error when we execute/validate the pipeline. When the pipeline fails, a window appears that shows the execution statistics for the pipeline. We can also go into the logs in the Dashboard tab to review the error.

Discard Error Data
The second option is “discard error data and continue,” which will actually ignore an error completely, discard that record, and continue with the rest of the records. If you choose this option, be very careful of partial or no data processing.

Error View
“Route error data to error view” is an option that actually handles the error. If you handle all of the errors on this way in the pipeline, the pipeline status will remain completed. In the scenario below, we route the data to an error view of the Mapper Snap and then decide what to do with the error (store in a file, in a database, etc.). Handling errors this way is beneficial for specific scenarios where we need to take a certain action for that particular error. This is not the best practice for overall error handling of the whole project because, over time, as the pipelines get developed, they will increase in size, the number of Snaps, and complexity, making them nearly impossible to maintain.
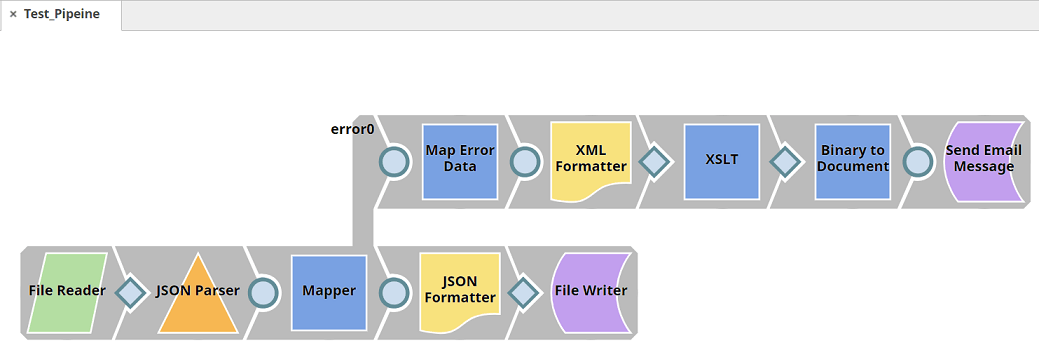
Error Pipeline
Using an Error Pipeline is a fairly new method of handling errors on a pipeline level. It’s quite an efficient way to manage and control which actions should be performed when errors occur.
The Error Pipeline is the place where we set all of the actions that should be executed when an error happens. It is always a reusable piece of code which will be called dynamically to handle the errors in one or more projects. This method stands out as one of the better ways to handle errors because it lets us add as many integrations/pipelines as we want while making little-to-no changes in the Error Pipeline.
The setup for the Error Pipeline can be found in the SnapLogic documentation: Error Pipeline Configuration.
Best Practices
When designing an error handling solution, we should always bear several things in mind: 1) the pipeline must be as reusable as possible; 2) it should be parameterized so it can be dynamically invoked in as many projects as needed; 3) it should be very well structured to minimize the effort of modifying it; 4) it should have the best performance possible; and 5) its executions should be reusable when possible.
Our best practices so far have included many ways to store error data, which ultimately helps business users identify errors quickly. These best practices will enable you to deliver meaningful error messages to business users, use as little time as possible on mitigating those errors, reduce the effort of the support team in fixing or escalating the issue, facilitate good communication between different teams (Support, QA, DEV, Business, etc.), avoid full inboxes with errors that you are not responsible for, and enjoy many other benefits. To get all this, we identified a few steps that should be included in most cases:
- Error file creation to an Sftp/ftp, smb, sldb, local file system, Amazon S3, Azure blob storage, etc.;
- Email notification to appropriate email groups according to the type of error and the responsibility of the teams for a specific type of issue;
- Inserting the errors into a database;
- Automatic ticket creation in some tracking system like Jira, Service Now, etc. and dynamically assigning them to appropriate groups according to the type of error.
Below is one common error handling routine which includes all of the steps mentioned above and captures all the business values we talked about:
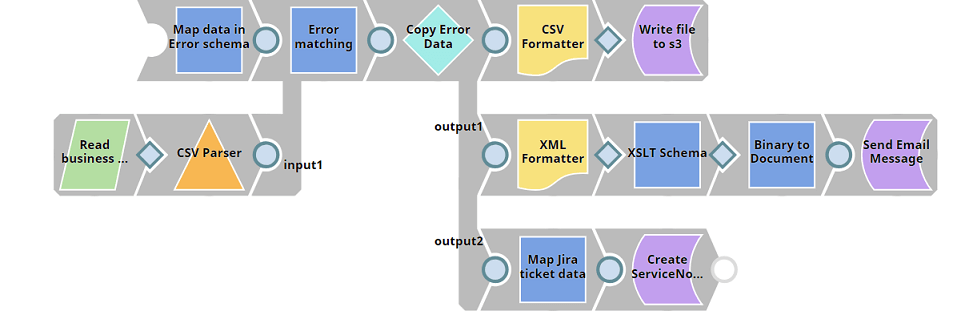
Steps that are included in the error routine:
- Map the error data to an error schema
- Match the incoming error with the business errors
- Store error data into a csv file and save it on an S3 bucket
- Send an email message to the respective team
- Create a ServiceNow ticket and assign it to the respective team
This is a simple solution where we deliver all the KPIs for one error routine to provide the needed value for the Client. Matching the error data with a predefined set of translated errors with meaningful business descriptions is especially important. Here’s how you do it.
So, every error message that will come as an input in the error routine will have the same keys in its message because that is how the default error message structure that SnapLogic generates appears.
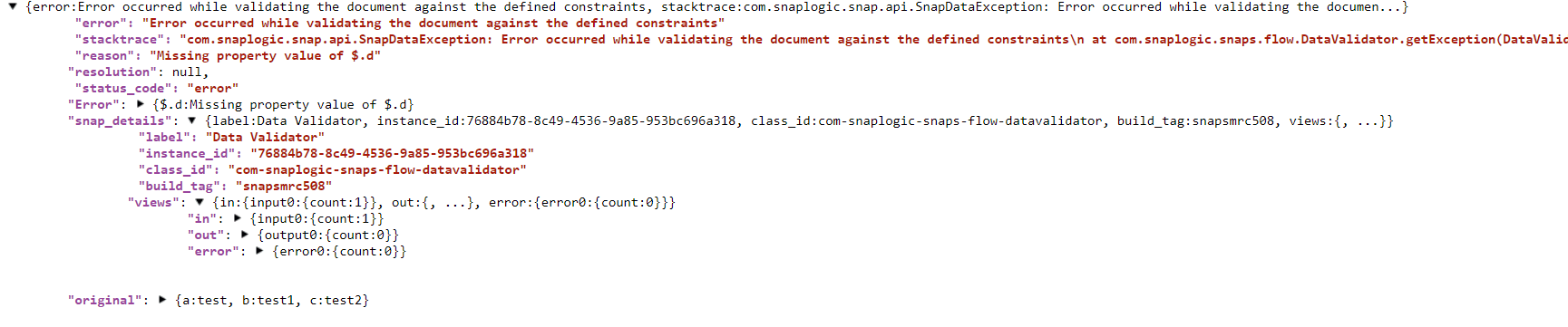
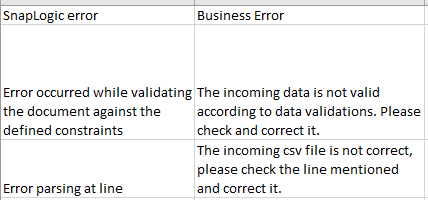
The file that will have the translated error messages will look something like this:
The error that comes from SnapLogic will be translated to the Business-meaningful error message that will help the business identify and fix the issue connected with it. These messages will be sent as an email notification to the groups according to the error that happened. For example, if it is a code issue, the error notifications will go to the SnapLogic developers; if it is a source data issue, the notification will go to the owners of the source data; connection issues go to the infrastructure team, and so on. To generate useful, easy-to-understand error reports, we use XSLT schema transformation by which we dynamically transform every error message into a valuable error report.

As you can see, the ServiceNow ticket is included in the email message as well. The step for creating it is very similar to the email notification step, where we decided which category each ticket should go to.
Based on those previous category assignments, Service Now identifies the assignment group for that incident.

Conclusion
SnapLogic makes it easy to create an error routine. The important thing to remember is that you must first define the requirements, capabilities of your system, and your expectations. Then you must design and develop a good common error-handling solution that can be reused in every future project and connect with every integration that you put in place down the road.
If you need help in any of the steps I mentioned, including business analysis, design, development or any phase in which you have insecurities, do not hesitate to contact us.
