

We, at Interworks, work with Elasticsearch to cover a number of use cases. Elasticsearch is a distributed, RESTful-based and multitenant full-text search and analytics engine based on Apache Lucene, with HTTP web interface and schema-free JSON documents.
Sometimes, matching only the exact words that the user has queried is not enough and we need to expand the functionality and also search for words that are not exactly the same as the original, but still meet the criteria. Full-text search is a battle between precision and recall – returning as many more relevant and less irrelevant documents as possible.
Analysis is the process of converting text into tokens or terms that can be searched, and added to the index for searching. An index is a logical searchable namespace that can be imagined as a relational database. Each index contains a mapping which defines multiple types. Analysis is performed by an analyzer which can be either a built-in analyzer or a custom analyzer defined per index.
Each custom analyzer consists of:
- tokenizer – used to break a string down into a stream of terms or tokens
- character filters – used to preprocess the stream of characters before passing it to the tokenizer
- token filters – used to add, modify or delete tokens and make the search criteria more relevant.
Our custom analyzer is used by a company that has several divisions and takes records about each user employee and his/her interests. This analyzer is used in the index named ‘division’ with ‘standard’ tokenizer. We want to add one custom token filter called ‘custom_filter_synonym’ of type ‘synonym’ in which we define group of words that we want to act as synonyms. Then in our custom analyzer we list our custom filter, plus two other built-in filters: lowercase to normalize token text to lowercase and porter-stem token filter.
Most of the languages are inflected, meaning that words can change their form to express differences in number, tense, gender etc. For example, the words ‘plays’ and ‘playing’ both belong to their root word ‘play’. Stemming is the process of removing the differences between different forms of a word.
Stemming is not easy at all because it is as an inexact science for each language. Also, it often deals with two issues: understemming – inability to reduce words with the same meaning to the same root and overstemming – inability to keep two words with different meanings separate. In Elasticsearch, there are two stemmer classes available that cover most use-cases: algorithmic stemmers and dictionary stemmers.
Porter_stem token filter in our custom analyzer is used to transform the token stream for English language following the Porter stemming algorithm.
The definition of our custom analyzer is presented below:

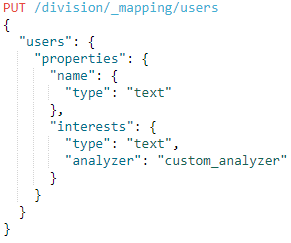
Next, we specify mapping for the type ‘users’ that belongs to the ‘division’ inverted index that we have previously created. Our type ‘users’ have two fields:
- name – standard text field
- interests – text field that will use the custom analyzer.
……………….
“educ”: {…}
“learn”: {…}
“note”: {…}
“read”: {…}
“record”: {…}
“studi”: {…}
“write”: {…}
……………….
Note that we got ‘learn’ for ‘learning’ which is probably what we want, but we also got ‘educ’ for ‘educate’ and ‘studi’ for ‘study’ which might not always be the desired outcome. Hence, choosing the right options that will meet our requirements is a must and we need to be very detailed and consider a number of factors like quality and performance.
If we want to search our index for users that have ‘record’ in their interest, it will list all of them that have record and/or synonyms of note as well. We can search only by several letters and not the entire word, for example ‘rec’:

Response:

Once we have gotten the desired results, we want to analyze and summarize our data set. In Elasticsearch, this is accomplished with aggregations. Aggregations operate alongside search requests meaning that we can both search/filter documents and perform analytics at the same time, on the same data and in a single request. Aggregations are very powerful because they offer to visualize our data in real time and build super-fast dashboards and many companies are using large Elasticsearch clusters specially for analytics.
Aggregations are combination of two concepts:
- Buckets – collections of documents that meet certain criteria
- Metrics – statistics calculated on the documents in a bucket
In our scenario, a company that is taking care about its employees organizes events or offers benefits to support employees’ interests and their well-being. To make an annual plan that will fit in the company budget, analyses for the costs are required.
We’ll be using a histogram, a bar chart that works by specifying an interval and is very often used for reporting. We want to calculate total amount per interval. Оur query looks like this:

In the result set, we can preview specific intervals and total amount spent for each interval:

Aggregations have a composable syntax meaning that the independent units of functionality can be mixed and matched to provide the custom behavior and result data can be converted into charts and graphs very easily using Kibana or some other BI tool. In other words, they offer limitless possibilities.
Conclusion
Elasticsearch offers very powerful options for searching and analyzing the data. In addition, using the built-in features or some other custom solution we can accomplish everything – from creating complex search patterns for different purposes to dealing with human language in intelligent way and using aggregations to explore trends and patterns in our data.