

In today’s time of data-oriented applications, there is a need to constantly change the data in terms of migration and transformation, to meet certain requirements of data onboarding from and to varied sources. And in all this, you might find yourself stuck between traditional and time-consuming methodologies of data migration which cause costs, overheads and time-consuming efforts.
In the Amazon Cloud environment, there are multiple services used for automation of data-driven workflows including AWS Data Pipeline, AWS Glue, AWS Database Migration Service or AWS Step Functions, regular Lambda functions and so on, each with proper scenarios. Choosing the right service for the right purpose is the most important part.
In this and next blog posts we will describe how to use some of these services for proper data management and ETL operations.
What is AWS Data Pipeline?
AWS Data Pipeline is a powerful service that can be used to automate the movement and transformation of data while leveraging all kinds of storage and compute resources available.
Data Pipeline can be used for all data-driven workflows to migrate data between varied data sources, create simple to complex ETL (extract, transform, load) operations that can be properly triggered or scheduled, organizing dependent operations, etc.
AWS Data Pipelines consists of the following basic components:
- Data Nodes – represent data stores (locations) for input and output data. Data Nodes can be of various types depending on the backend AWS Service used for data storage: DynamoDBDataNode, SqlDataNode, RedShiftDataNode, S3DataNode.
- Activities – specify the work to be performed on data stored in DataNodes. Activities are extensible and can run custom scripts to support endless combinations. Different types of activities are provided depending on the application: CopyActivity, RedShiftCopyActivity, SqlActivity, ShellCommandActivity, EmrActivity, HiveActivity, PigActivity etc.
- Resources – the activities are executed on their respective resources depending on the nature of the activity. They can be of type EC2Resource or EmrCluster.
The Challenge
Companies often need to move and transform data from their cloud or on-premise databases and use that data for analytical or BI purposes. We have a scenario where we have multiple systems that should be integrated and one integration module requires RDS MySQL instance as a source and PostgreSQL as the final destination. Various transformations should be done within the process.
Now, how we can leverage AWS Data Pipeline service to achieve this?
The Solution
First, we’ll move the records of the specified table to S3 bucket as S3 is used as a storage for our data lake sourced from multiple systems. Then the data is consumed by multiple applications for different purposes, but in our example to keep things simple, we’ll load the data only in PostgreSQL destination database.
We have a table weather from MySql source database with the following structure:
| column name | data type |
| id | integer |
| sensor_id | integer |
| perception_date | timestamp |
| temperature | decimal (6,2) |
| wind_speed | decimal (6,2) |
| rain_fall | decimal (6,2) |
| humidity | decimal (6,2) |
Destination table in PostgreSQL has similar structure and one additional column to make calculations within:
| column name | data type |
| perception_time | smallint |
Now, we compose pipeline definition objects in a pipeline definition file
{
"objects": [Define common fields, resource and schedule period
{
"id": "Default",
"name": "Default",
"scheduleType": "timeseries",
"failureAndRerunMode": "CASCADE",
"role": "DataPipelineDefaultRole",
"resourceRole": "DataPipelineDefaultResourceRole"
},
{
"id": "DefaultSchedule",
"name": "My Schedule",
"startDateTime": "2020-01-01T00:00:00",
"type": "Schedule",
"period": "1 hours"
},
{
"id": "Ec2Resource",
"name": "EC2 Resource",
"schedule": {"ref": "DefaultSchedule"},
"role": "DataPipelineDefaultRole",
"type": "Ec2Resource",
"instanceType": "t2.micro",
"resourceRole": "DataPipelineDefaultResourceRole"
},First, we’ll make Full Copy of RDS MySQL Table to S3. We’re going to use SqlDataNode for retrieving data from source (MySql table weather), CopyActivity to copy data into CSV file and S3DataNode to store that data into S3 bucket.
{
"id": "MySqlDataNode",
"name": "MySQL RDS Data",
"username": "mysql-username",
"schedule": {"ref": "DefaultSchedule"},
"*password": "mysql-password",
"connectionString": "jdbc:mysql://mysql-instance-name.id.region-name.rds.amazonaws.com:3306/database-name",
"selectQuery": "SELECT * FROM #{table}",
"table": "weather",
"type": "SqlDataNode"
},
{
"id": "S3DataNodeForMySQL",
"name": "S3 Data from MySQL",
"schedule": {"ref": "DefaultSchedule"},
"filePath": "s3://my_bucket/mysql-output/weather.csv",
"type": "S3DataNode"
},
{
"id": "CopyActivityMySqlToS3",
"name": "Copy MySQL to S3",
"input": {"ref": "MySqlDataNode"},
"schedule": {"ref": "DefaultSchedule"},
"runsOn": {"ref": "Ec2Resource"},
"output": {"ref": "S3DataNodeForMySQL"},
"type": "CopyActivity"
},After the data is stored in S3, we going to make a connection using JDBC driver to our PostgreSQL target database. To make summarization easy, we are going to create and populate our data from CSV to a temporary table in PostgreSQL.
The final step is to summarize that data from the temp table and insert it into the destination table in PostgreSQL database. Of course, we can make any transformation like aggregations, joins with other tables in the destination, lookups, parent-child relationships, etc.
{
"id": "rds_pgsql",
"name": "RDS PostgreSQL",
"connectionString": "jdbc:postgresql://postgresql-instance-name.id.region-name.rds.amazonaws.com:5432/database-name",
"*password": "postgresql-password",
"jdbcProperties": "allowMultiQueries=true ",
"type": "JdbcDatabase",
"jdbcDriverClass": "org.postgresql.Driver",
"username": "postgresql-username"
},
{
"id": "TempTableWeatherCreateActivity",
"name": "Create Temp Weather",
"schedule": {"ref": "DefaultSchedule"},
"database": {"ref": "rds_pgsql"},
"runsOn": {"ref": "Ec2Resource"},
"type": "SqlActivity",
"script": "CREATE TABLE IF NOT EXISTS temp_weather (id integer, sensor_id integer, perception_date timestamp without time zone, temperature numeric(6,2), wind_speed numeric(6,2), rain_fall numeric(6,2), humidity numeric(6,2));"
},
{
"id": "LoadTempWeather",
"name": "Load data into temp_weather",
"schedule": {"ref": "DefaultSchedule"},
"output": {"ref": "tempNodeWeather"},
"input": {"ref": "S3DataNodeForMySQL"},
"dependsOn": {"ref": "TempTableWeatherCreateActivity"},
"runsOn": {"ref": "Ec2Resource"},
"type": "CopyActivity"
},
{
"id": "tempNodeWeather",
"name": "temp_weather",
"schedule": {"ref": "DefaultSchedule"},
"database": {"ref": "rds_pgsql"},
"dependsOn": {"ref": "LoadTempWeather"},
"insertQuery": "INSERT INTO #
table} (id, sensor_id, perception_date, temperature, wind_speed, rain_fall, humidity) VALUES (?,?,?,?,?,?,?);",
"type": "SqlDataNode",
"selectQuery": "select * from #{table}",
"table": "temp_weather"
},
{
"id": "InsertIntoPostgeSQLActivity",
"name": "Insert summarized data",
"schedule": {"ref": "DefaultSchedule"},
"input": {"ref": "tempNodeWeather"},
"database": {"ref": "rds_pgsql"},
"dependsOn": {"ref": "LoadTempWeather"},
"runsOn": {"ref": "Ec2Resource"},
"type": "SqlActivity",
"script": "INSERT INTO test.weather (perception_date, perception_hour, temperature, wind_speed, rain_fall, humidity) SELECT perception_date::date, MAX(extract(hour from perception_date)), AVG(temperature), AVG(wind_speed), AVG(rain_fall), AVG(humidity) FROM temp_weather GROUP BY perception_date::date; DROP TABLE temp_weather;"
}
]
}Here is a picture of our Data Pipeline in the AWS Architect working environment:
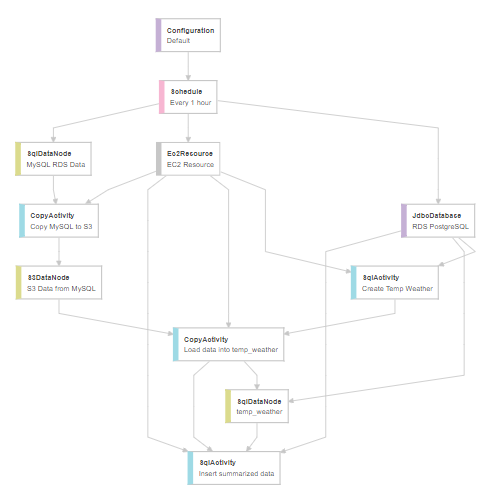
For the sake of truth, connectors and built-in activities for different source and destination types are not always fully supported and for some scenarios, additional coding, research and playing with data is required in order to set connectivity and transformations in place.
Conclusion
AWS ETL and data migration services and AWS Data Pipeline as one of them clearly open up the path for data engineers, scientists, analysts, etc. to create workflows for any possible scenarios with their low cost, flexibility, availability and all other advantages of the cloud environments. Companies can run only a few data transformation jobs or thousands, but the service can accommodate any requirements and scale up or down as needed.
In the following articles, we’ll show scenarios with other on-premise and cloud-based data services as well. So, you can start playing right away and please share your experience with us.
If you are interested in other blog posts related to Data – you can check them here – Data Management Blog Posts.