

Why Cloud Warehousing?
Cloud data warehousing is a cost-effective way for companies to take advantage of the latest technology and architecture without the huge upfront cost of purchasing, installing, and configuring the required hardware, software, and infrastructure. It’s designed for the sheer volume and pace of data and it can be used by departments like marketing, finance, development, and sales in organizations of all types and sizes.
With cloud data warehousing, it’s very easy to adapt to dynamic changes in data volume and analytics workloads. Data is available immediately and at every step of modification, supporting data exploration, business intelligence, and reporting. There are no limitations on the number of users and data insights can be always up to date and directly accessible to everyone who needs them. Enterprises are empowered to shift their focus from systems management to analysis and operate at any scale. The process makes it possible to combine diverse data.
Microsoft Azure is a cloud platform for building, deploying, and managing services and applications. It provides secure, reliable access to the hosted data, and it can spin up new services and geometrically scale data storage capabilities on the fly making it cheaper at the same time, offering a number of services for accomplishing the mentioned.
Problem
Our main goal is to show how to quickly create an Enterprise Data Warehouse in Microsoft Azure and load the data automatically from multiple sources located on-premises in order to improve performance, grow storage of computing resources independently, support multiple data formats, improve security, and be able to monitor the entire process as well. And at the end the main goal is, of course, to use the data for analytics and reports. Important guidelines that we need to achieve in this particular case are:
- Lower the financial cost for storage and computations.
- Build pipelines from internal resources to the cloud in a predetermined time frame.
- Ensure data integrity by implementing Slowly changing dimension (SCD) Type 2.
- Monitor pipelines.
- Create alerts and email notifications and overcome seemingly endless details and potential errors.
- Execute security policies.
Solution
The solution is composed of optimized Data Factory pipelines for transforming and loading data into Synapse Analytics. We chose Azure Data Factory as one of the leading tools that provide managed cloud service that is built for complex extract-transform-load (ETL), extract-load-transform (ELT), and data integration projects.
Common functionalities include complex query logic for extracting the data from the source, consuming data warehouse dimensional/fact model with highly optimized operations applied, and many complex transformations for loading the data into the warehouse.
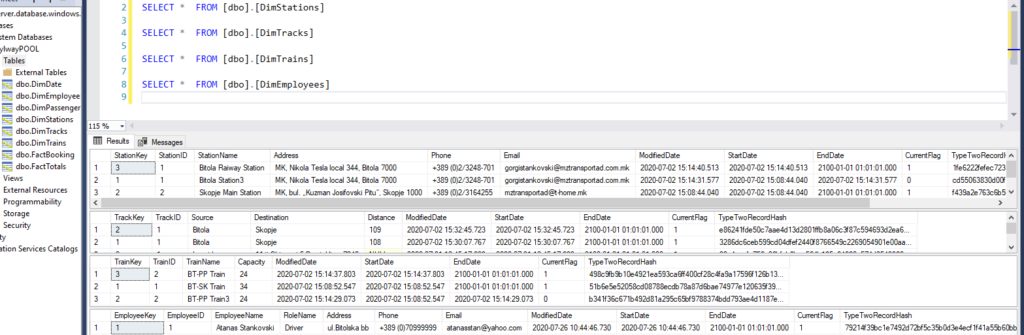
The image below shows sample data from a source relational database and we can see the fields and relations between the tables.
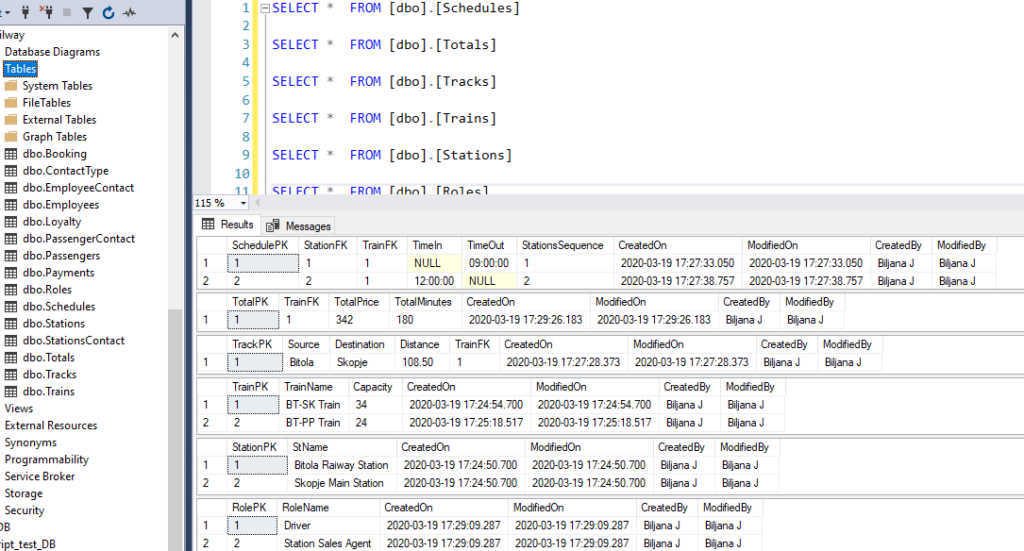
The step of loading the dimension tables is performed by comparing the source data and existing data, while hashing is used for tracking the changes between both. If a record exists it is going to be updated, if not, it is going to be inserted while preserving the rules for SCD Type 2.
When pulling data from the source, we’ll define and use the queries as needed.
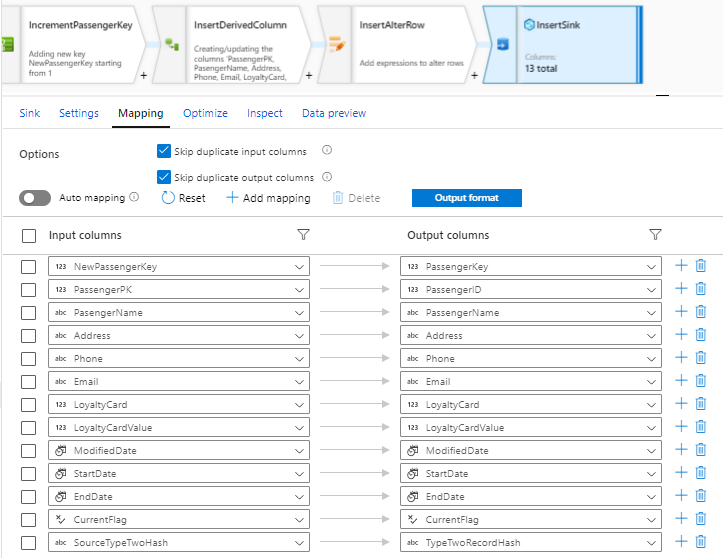
After all transformations are completed, the final step is to insert the data in Azure Synapse Analytics. We will enable the option Allow Insert so the sync will only allow inserts and all of the columns should be mapped correctly with the matching data types:
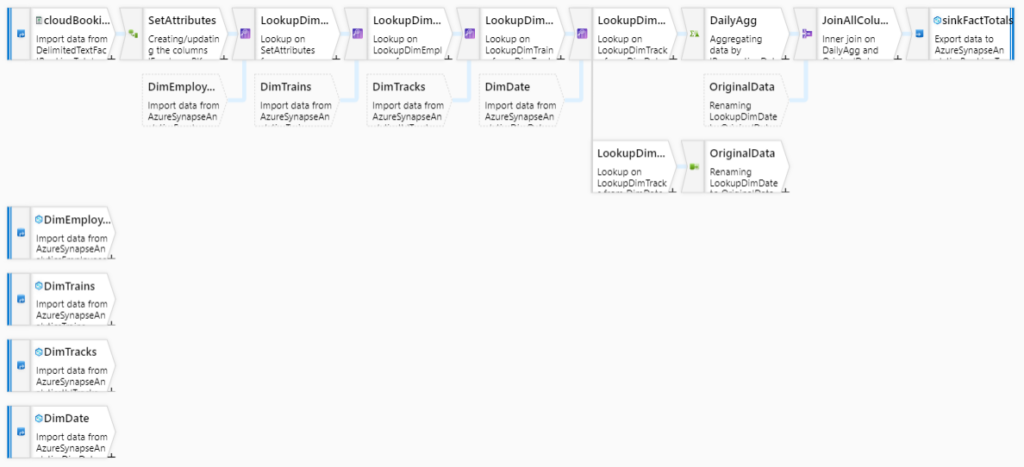
The step of loading data in the fact tables is performed once the dimension tables to which the fact table refers to are loaded. When a key is found using the control Lookup, the key is stored in the fact table along with aggregation if needed.
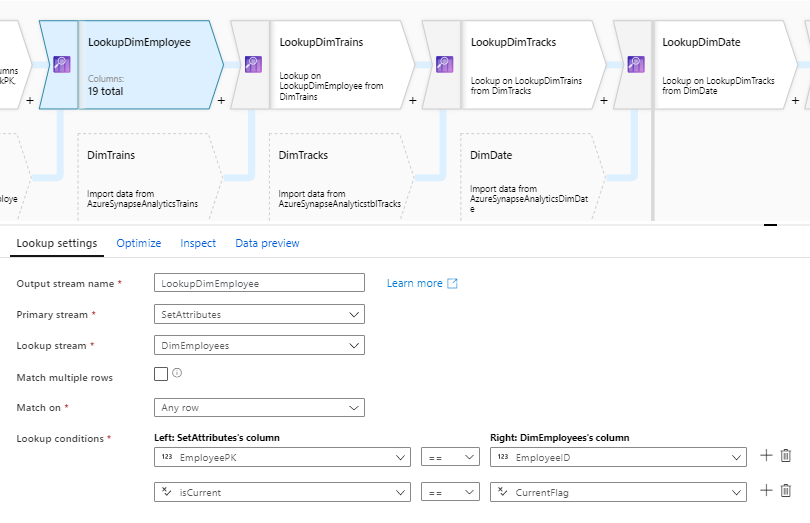
In the Lookup control, the ID from the source is compared only with the current ID from the Dimension table.
Below we can see part of the final appearance of the Azure Synapse Analytics Database and the way historical data tracking is provided.
Common methods such as logging, error handling, and notification settings are obtained by using Data Factory Monitor and Azure Data Factory Analytics.
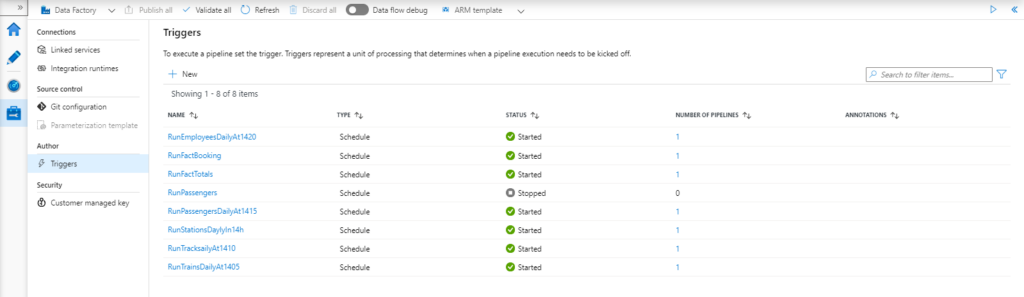
We have created control mechanisms in order to track complex interactions, monitor and effectively manage dependent processes, and set notifications to be sent over e-mail. Azure Monitor provides base-level infrastructure metrics and logs for most Azure services. Diagnostic logs are emitted by a resource and provide rich, frequent data about the operation of that resource.
In the following pictures, we can see how pipelines, triggers, and integration pipelines can be easily monitored and how alerts can be created using Data Factory Monitor and Azure Data Factory Analytics.
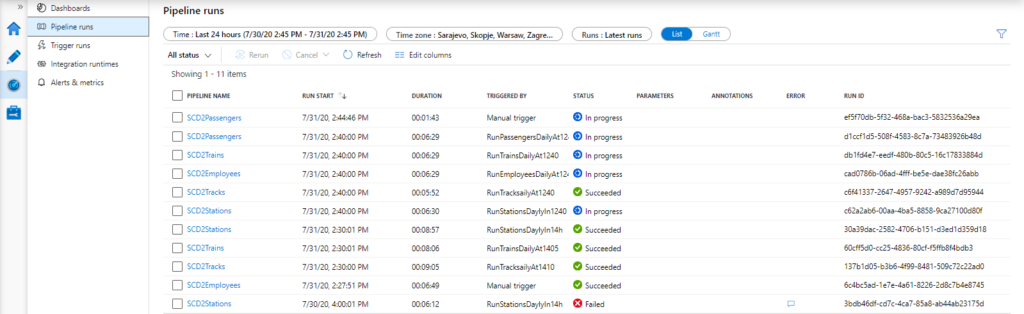

With these dashboards, we can have an excellent visual overview of the overall process, track performance, CPU utilization, memory consumption, and other details that are important to us.
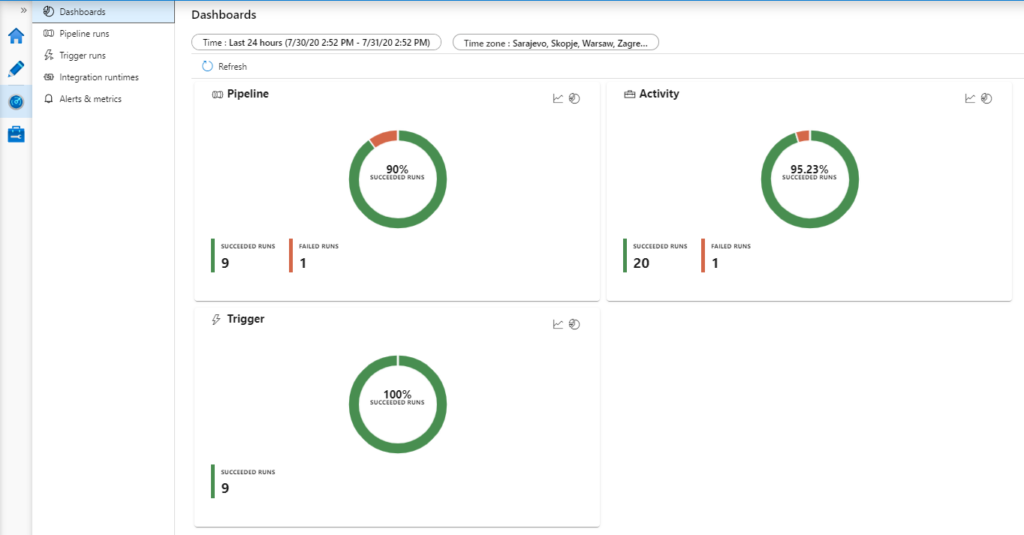
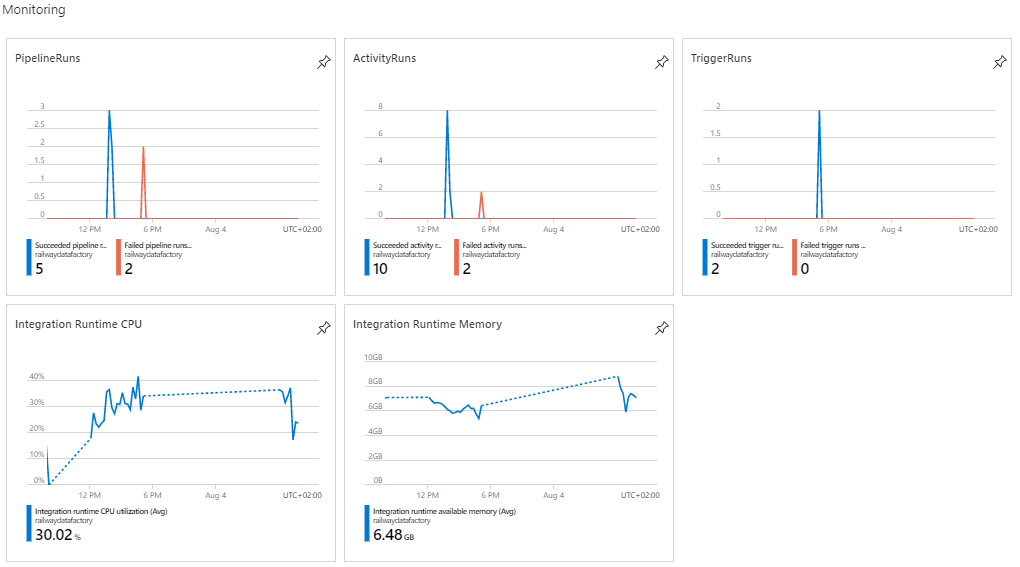
The same metrics are also tracked with Azure Data Factory Analytics which can provide a visual summary of the overall health of the Data Factory, with options to drill into details and to troubleshoot unexpected behavior patterns.
Advanced security is provided with Azure Security Center and allows security health monitoring for both cloud and on-premises workloads, security threat blocking through access and app controls, adjustable security policies for maintaining regulatory and standards compliance, security vulnerability discovery tools and patches, and advanced threat detection through security alerts and analytics.
As we can see there are many security issues that should be resolved for most of the resources.
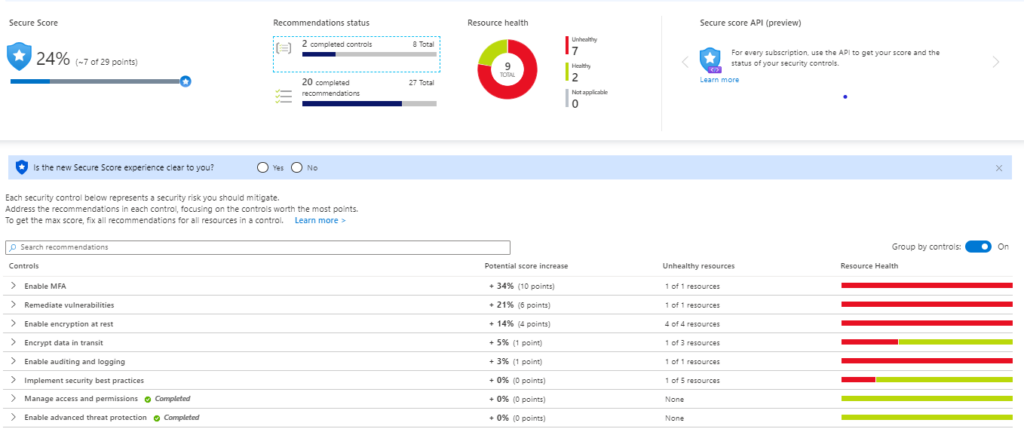
By remediating all vulnerability issues, the overall security is increased and will be at max once Multi-Factor Authentication (MFA) is enabled.
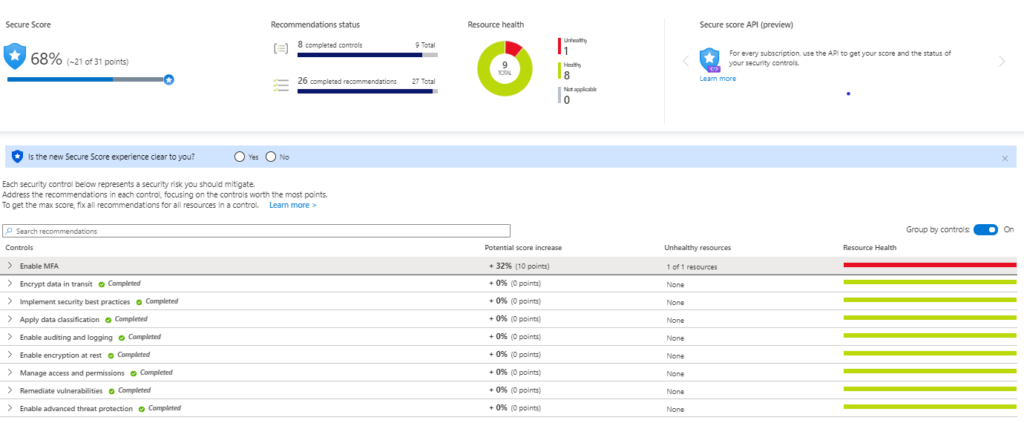
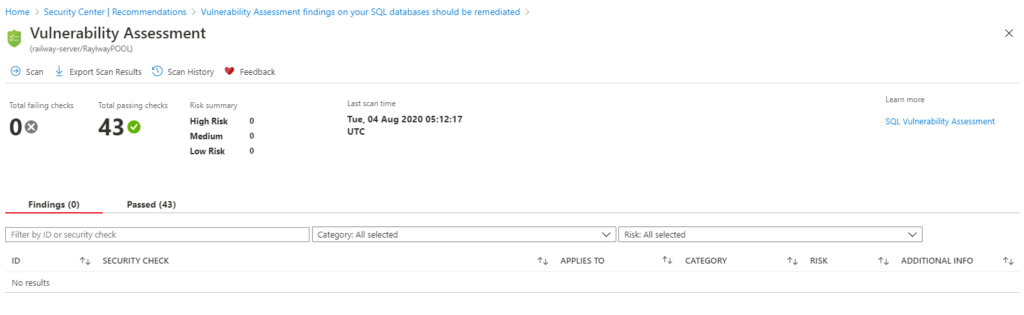
Conclusion
By building the data warehouse in the Azure cloud we obtained a lower-cost solution with the ability to scale and compute storage. We developed a high-performance boost using automatic loading of the Azure Synapse Analytics, the access to the data and query performance was accelerated with built-in intelligent caching by using Azure Cache for Redis.
The slowly changing dimension (SCD) of type 2 is used for managing current and historical data in the data warehouse which is optimally solving one of the most essential aspects in handling dimensional data integrity.
The data is 99.9% available and it also has regulatory compliance built-in, hence overall increased security using built-in tools tightly coupled with Azure Active Directory (AAD) to provide authorization and data-level security, encryption of data in motion and at rest, enabled IP restrictions, auditing, and threat detection.