

Automation enables you to be more effective and efficient and also enables you to spend more of your time adding value doing more effective things. By automating the routine of your regular job, you free up time to focus on things you would like to fix, improve, or upgrade in your environment. Automation is a force multiplier. Moreover, as machines are performing tasks, they complete them faster than a human would, further increasing capacity and service quality.

All of the above is quite hard to achieve, especially if you are trying to integrate more than two systems. That’s the reason why we are using SnapLogic as a sophisticated software tool, for which you can read more in this blog post. SnapLogic can handle integration of really big number of systems, applications, data and etc. and at the same time all of those processes can be automated just by using SnapLogic Tasks. This article will demonstrate how easy, powerful and efficient can be the automation process using SnapLogic.
To understand the main advantages of SnapLogic tasks we will go through two scenarios. First we will see how to automate SL process by executing its URL, and then we will go through more complex scenario using scheduled tasks. For this scenarios we have created one DB with table DailyLog, which will be used as Daily log of all processes and we have also developed two simple SnapLogic projects. The main goal here is to automatically execute the Main_Process pipeline and see all of the advantages of automation using SnapLogic.
Case 1: Call the Main process using Triggered Task
In this scenario we will use three SL processes and two more pipelines for writing log in DailyLog table. All in all, the project have 5 pipelines:
- Main_Process – (to start Main Process, Process 2 must be executed successfully)
- Process_2 – (to start Process 2, Process 1 must be executed successfully)
- Process_1 – (This may be triggered or scheduled process)
- Log Start
- Log Stop
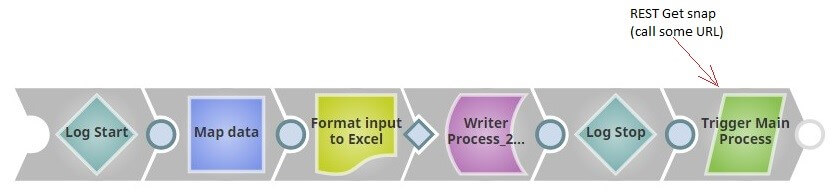
The main goal here is to automatically start Main_Process pipeline after successfully executing of processes 1 and 2.
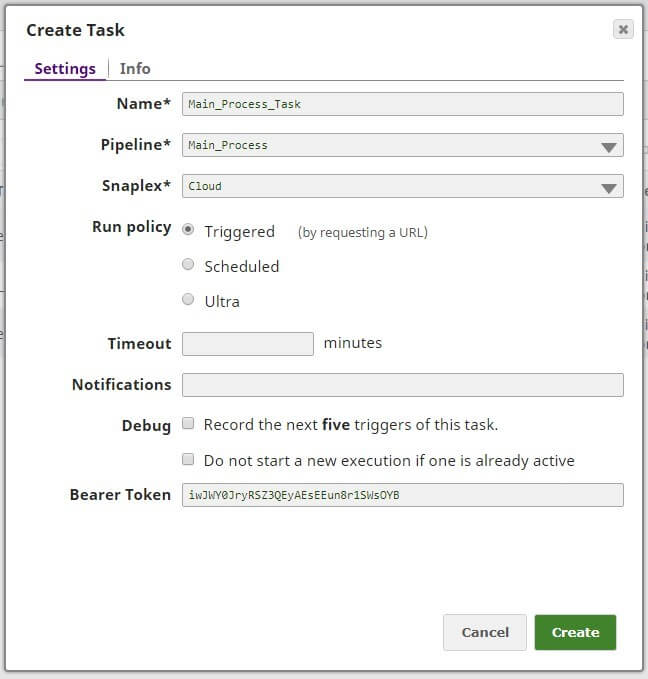
To facilitate automation in this scenario, we are using scheduled task on the Process_1 just to start the process (this also may be a triggered task) and Triggered tasks on the Process_2 and Main_Process. We can create tasks by clicking on create task icon from the Designer tab or going to Manager tab, subtab Task and clicking on + icon. Pretty easy and intuitive.
After automatically starting Process_1 we can see in the dashboard and DailyLog MySQL table that all other processes are executed successfully. From the SnapLogic Dashboard we can notice which processes are scheduled/triggered and we can also see that all of the three processes are Completed with no failures.


Of course, there can be failures of the Main pipeline which we can easily read from the log table and also from the SnapLogic Dashboard.

If some of the pipelines fail, there will be no values for end_date and process_success columns in the log table and the entire execution will stop (depending on the pipelines design).

The main advantages of using SnapLogic Triggered Tasks like the above mentioned are:
- External URL for the task
- You can choose between using Bearer Token or no
- You can pass parameters
Case 2: Call the Main process using Scheduled Task and Check Pipeline.
A triggered task is easy to implement if your project is dependent only from other SL processes or processes which can be executed by their URL.
Using SnapLogic as an integration tool you will probably develop pipelines to integrate two or more systems. Almost all of the best practice examples are following the model of writing daily log for all executed processes.
In this case we will use the same MySQL log table and the same pipelines and we will suppose that Process_1 and Process_2 are independent and they are result of two different systems. Our main goal is executing our SL Main_Process only when the above processes are successfully executed.
To facilitate this, we will create one Check pipeline. This pipeline will be scheduled using scheduled task, and will check for completion of the above two processes and only then using Pipeline Execute snap Main_Process will be started. This pipeline will also check if Main process is already executed. We should execute Main process only one time per day.
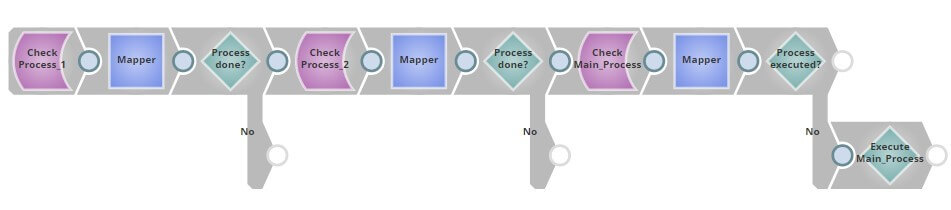
This pipeline will be scheduled using Cron functionality of SL Scheduled Task to check every minute from 12 PM to 5PM every single day. You can also add blackout dates, end date of task, time zone etc.
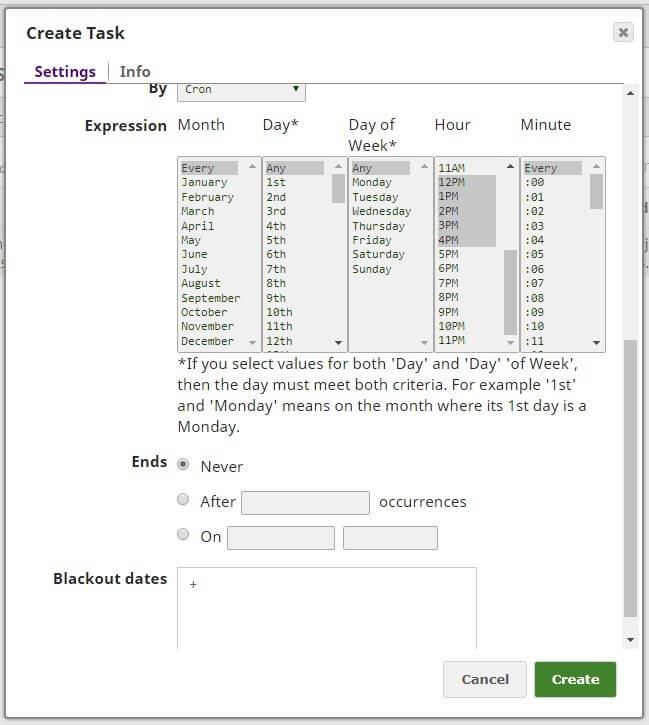
SnapLogic dashboard will give you information when the execution of the pipeline occurred, and we can see there was only one execution of the main process and this means satisfying execution requirements.


Opposite of this successful execution, for example if the process 2 wasn’t executed today or the flag or end_date columns are null our Main SL process will never be executed by the task scheduled for today.
Conclusion
A dollar earned efficiently is worth 10 dollars.
Simply put, do more with less effort. Automating SnapLogic processes means that the company can take on a greater task volume. Therefore, the capacity to support more clients is possible, and this article should exactly show the power of SnapLogic to handle lot of processes by the ease of Tasks feature for automation.