
Every company has an opportunity to make the most out of the constant flow of information coming in from outside – things like job postings, product launches, market news, research papers, industry reports, and public conversations. Lots of clues in there, if you have time to read it. And then there’s everything you already know inside – projects you’ve done, case studies, certifications, the people who’ve solved this kind of thing before.
And that’s usually where opportunities quietly fall through. There’s a hiring signal that lines up with something your delivery team has solved twice before, but sales never sees it. A competitor posts a job ad that hints at where they’re going, and HR scrolls right past it. A new regulation drops that fits exactly what marketing has been writing about for months, and nobody connects the two. Inside any large organisation, no single person knows everything the company has ever built, delivered, or learned, so the dots stay unconnected. The bigger the organisation gets, the wider the gap becomes.
This is exactly what an AI pipeline is good at. It can search across the full breadth of your internal knowledge, read every relevant public signal the moment it appears, and surface the specific match between the two. It does in seconds what no individual could do at all, and it does it consistently, every time.
We built a reusable AI capability around exactly that idea – a pipeline that takes a public signal, understands what is being asked, retrieves the strongest internal evidence, and produces a grounded draft ready for a human to review. We illustrate it with our LinkedIn outreach product, the first use case we put into production, but the same architecture fits sales, HR, marketing, partnerships, and any other function where external context needs to meet internal knowledge.
The Example: LinkedIn Outreach
Take a posting for a Cloud Infrastructure Lead that lists Kubernetes, Terraform, AWS, and drops a line about “modernizing our legacy on-premises environment.” That single post tells you where the company is in their cloud journey, what they are struggling with, and roughly what kind of help they need. The challenge is that job posts are written for candidates, not for analysis: they mix must-haves with nice-to-haves, use inconsistent terminology, and vary wildly in detail. Simple keyword matching misses most of this nuance, you end up either over-filtering or under-filtering.
So we treated the job post as a problem description, and our internal knowledge base as evidence that we have addressed similar problems before. That framing drove the design.
The System at a Glance
A job post goes in; a personalised, evidence-backed email draft comes out.

Each stage is an independently testable, observable unit, so let’s walk through every single one of them first.
Stage 1: The Relevance Gate
Not every job post is worth pursuing. Before running retrieval and generation, which takes time and compute, we do a quick AI-based relevance check: does this posting fall within the industries and technology domains where we actually have experience? An email written for an opportunity that is not a fit will always feel thin, regardless of how well the rest of the pipeline works. Filtering early means everything downstream is working on real opportunities.
Stage 2: Understanding What the Job Post Really Wants
A job post is just text. To search against it meaningfully, you need structured information. We pass the post through an LLM with carefully managed prompts that extract a set of fields, turning what a recruiter wrote in natural language into something the retrieval system can actually work with.
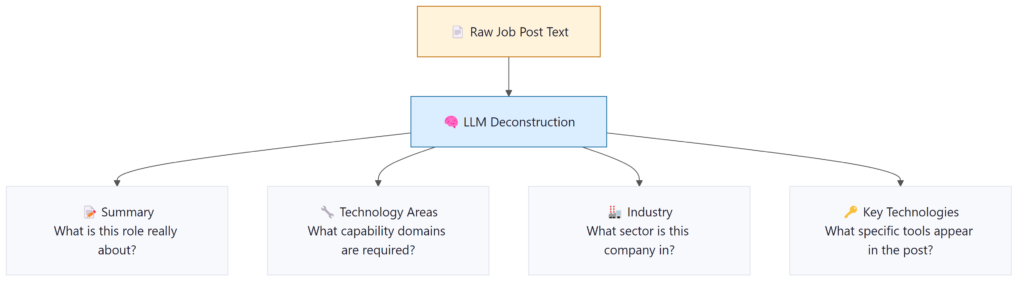
Stage 3: Building the Knowledge Base
Good retrieval depends on good source material. We built ours from three types of internal content:
Case Studies
- Crawled and ingested from our company website
- Tagged with the technologies and industry vertical each project covers
- The most direct proof that we have solved a specific type of problem before
- Carry the highest weight in scoring when there is a strong match
Client Project References
- Structured project data from internal records
- Covers engagements that may not have a public case study
- Adds breadth across projects and technology areas
- Particularly valuable for less common or emerging technology stacks
Certifications
- Synced automatically from our HR system
- Demonstrates team-wide competence, not just project history
- Useful signal when a job post asks for vendor-specific expertise
- Treated as supplemental evidence rather than primary proof
Everything in the knowledge base is stored with structured metadata alongside it, not just the text. Which technologies it covers, what industry it is from, when it was published. This ends up being just as important as the content itself, because retrieval and scoring lean heavily on it to separate genuinely relevant results from ones that are merely similar-sounding.
Stage 4: Finding the Right Evidence
This is where most of the architectural complexity lives, and where most generic AI tools fall short. Semantic search is a good starting point, but it tells you what is conceptually similar, not what is actually useful. A broad cloud infrastructure case study and a very specific Kubernetes migration case study might score almost the same on embedding similarity, but if the job post is about Kubernetes, one of them is a much stronger reference. Similarity alone does not capture that difference.
So we built a multi-stage retrieval pipeline that layers several signals on top of each other.
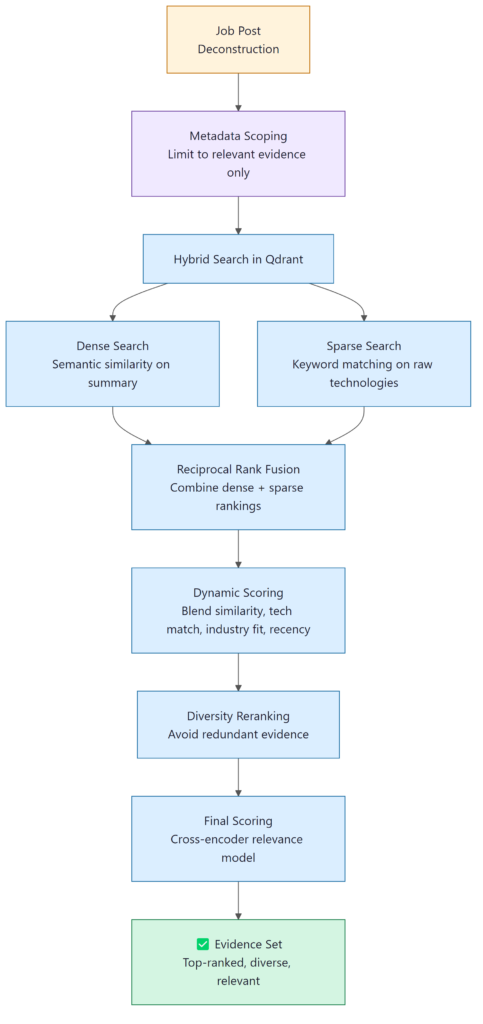
Before any search runs, we narrow the candidate pool using metadata from the deconstruction step. Within that scoped pool, the Qdrant vector database runs a dense semantic search on the job summary alongside a sparse keyword search on the raw technology terms, and merges the rankings. The merged results are re-scored using a blend of semantic similarity, primary technology match, industry alignment, and recency. A diversity step then prevents five near-identical case studies from dominating the result set, so the final evidence covers the requirements from different angles.
Why all these stages?
Each one catches something the others miss. Keyword search picks up specific tool names that semantic search glosses over. Dynamic scoring adds context that raw similarity ignores. Diversity reranking stops the same project from dominating. None of them is enough on its own, the value is in running them together.
Stage 5: Generating the Email
By the time we get here, the interesting work is done. Generation is deliberately the simplest part of the pipeline, the model’s job is to write a clear, professional email around the evidence, not to invent anything.
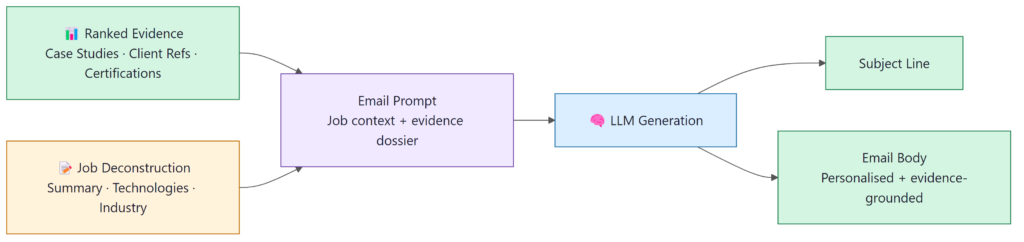
What comes out is an email grounded in something real: actual projects, specific technologies, verifiable outcomes. The sales team reviewing it can see exactly what evidence each point is drawing from, which makes the review fast and gives them confidence in what they are sending.
Grounding over generation
We deliberately constrain the LLM to draw only on the retrieved evidence. The value of the message is in its specificity, and specificity requires grounding in real facts. A model left to generate freely produces fluent but unverifiable claims – exactly the kind of message that gets ignored.
The Automated Pipeline
Every morning, the system pulls the previous day’s job posts from our CRM, runs them through the pipeline, and queues up email drafts for the sales team.
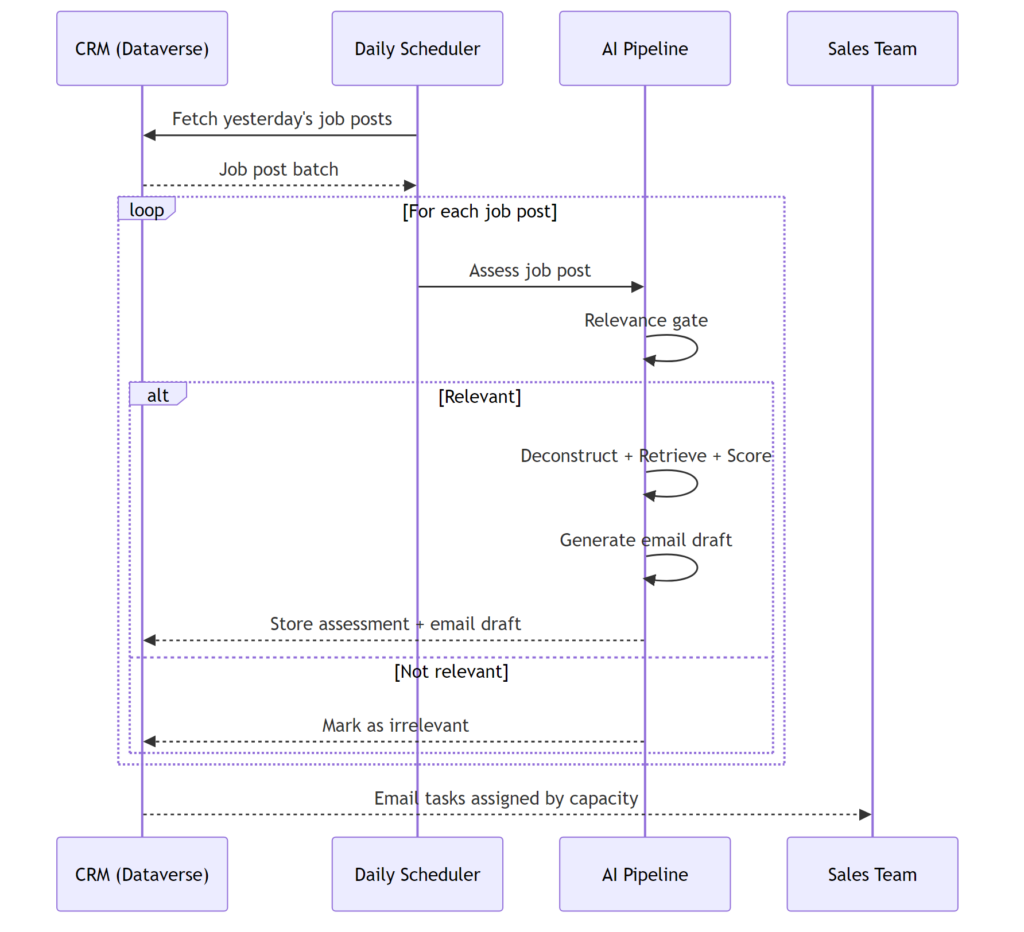
Email tasks are distributed across team members based on current capacity, so the work spreads evenly rather than piling into one inbox. By the time the team sits down in the morning, the batch is done – relevant opportunities flagged, irrelevant ones filtered out, drafts ready to review and send.
What We Learned
Building this system taught us things that apply well beyond this specific use case. A few that stand out:
Structure is more valuable than fluency
The most impactful investment was not in the generation step, it was in how we structure and interpret the input, and how we organise the supporting knowledge. Turning unstructured data into clear, consistent representations, and maintaining a well-tagged, well-understood knowledge base, does most of the heavy lifting. The LLM’s role is then relatively simple: express that structure clearly, not invent it.
Retrieval quality determines output quality
The generation step cannot compensate for poor retrieval. If the underlying information is only loosely relevant, incomplete, or redundant, the final output will reflect that, regardless of how fluent it sounds. We spent more time refining retrieval, filtering, and scoring than any other part of the system, and that investment had the biggest impact on overall quality.
Human review still matters, at every level
The system produces drafts, not finished emails. Every one gets reviewed by a person before it goes out, and that is intentional. The sender should understand what they are signing off on. Automation does the research; people still own the relationship.
But this principle runs deeper than the final output. When you change a prompt, adjust a scoring weight, or modify retrieval logic, automated metrics will tell you whether aggregate scores improved or dropped, and that matters. But it does not tell you the full story. Actually reading through individual results, what did the system pull, does this evidence set make sense for this particular job post, does the email feel right, gives you a kind of understanding that a dashboard score simply cannot.
The same goes for knowing your data. Spending time reading actual job posts, case studies, and generated emails, not skimming, but paying attention, surfaces problems that evals miss. You start to recognise where the data is patchy, where the model is confidently wrong, and where the pipeline is doing something quietly clever that you did not plan for. That familiarity is hard to quantify, but it is what makes you good at improving the system when something goes wrong. Metrics are a tool, not a substitute for knowing what you built.
Closing Thoughts
What started as a narrow problem, reducing the time it takes to write one cold email, turned into a broader exercise in building reliable, observable, evidence-driven AI applications. The architecture we built is not novel in any single component; hybrid retrieval, multi-stage reranking, and prompt management are all well-understood techniques. What matters is how they are assembled, and whether the system behaves predictably in production.
The pattern itself, read the outside, anchor it in the inside, hand a grounded draft to a human, turns out to apply far beyond outreach. Anywhere an organisation has rich internal knowledge that nobody can fully recall on demand, and a steady stream of external signals worth reacting to, the same architecture fits. What changes between use cases is the source, the evidence, and the artefact at the end; the principles do not.
If you are building systems that connect enterprise data signals to sales or business development workflows, we would be glad to compare notes. The hard problems in this space are worth talking about.