
Introduction to Change Data Capture (CDC)
In today’s data-driven world, effective data integration and ETL processes are crucial for organizations to make informed decisions. In cloud environments, efficient data integration and ETL processes can greatly improve the performance of your jobs by only reading the source data that has changed since the last time the pipeline was run, instead of always querying the entire dataset. This is where Change Data Capture (CDC) comes into play, a powerful feature in Azure Data Factory (ADF) and Azure Synapse Analytics that provides an efficient and effective way for data integration and ETL processes. Change Data Capture is a software process that identifies and tracks changes to data in a database. By leveraging CDC, businesses can experience a wide range of benefits such as:
- Real-time data synchronization ensuring that all data changes are captured and distributed to downstream systems in near-real-time,
- Reduced data latency by eliminating the need for manual data entry or batch processing,
- Improved data quality and reduced risk of data inconsistencies or errors,
- Efficient data replication across systems, improving efficiency and reducing the risk of data loss, and
- Minimal impact on source systems, minimizing the impact on database performance and reducing the risk of data corruption or loss.
The following blog post will provide you with a comprehensive overview of how to use Change Data Capture with Azure Data Factory, its benefits and how you can take advantage of it.
Change Data Capture Updated Capabilities and Overview in Azure Data Factory
The updated CDC capabilities in ADF allow for real-time change tracking of data in Azure SQL databases triggered by INSERT, UPDATE, or DELETE operations on a table in the source database. ADF then captures the change and writes it to a separate change table in the same database. These changes can then be propagated to other systems using ADF pipelines.
CDC capability is a top-level resource in ADF making its physical position next to pipelines and allowing for easy configuration without the need for data flows or pipelines. Data Flows or Power Query require a pipeline to run, whereas Change Data Capture doesn’t require a pipeline. Simply set the latency and CDC runs continuously in ADF, maintaining checkpoints and watermarks automatically. No trigger setting is required.
Native Change Data Capture in Mapping Data Flows
Native CDC (Change Data Capture) is a technique used in data integration to efficiently identify and track changes in data sources. It is commonly used in data warehousing, real-time data integration, and other data integration scenarios. In Mapping Data Flow, Native CDC is a feature that allows you to capture and process the changes in your data sources in real-time. By using Native CDC in Mapping Data Flow, you can improve the efficiency and speed of your data integration process, as well as reduce the amount of data that needs to be processed, since you are only processing the changes in your data source. Additionally, Native CDC ensures that your data is up-to-date, which is essential for many real-time data integration scenarios.
Native CDC in Mapping Data Flow supports several connectors for change data capture. The supported connectors are:
- Azure SQL Database: You can use Native CDC with Azure SQL Database to capture changes made to your SQL database in real-time. This makes it easier to integrate your SQL database with other data sources, such as data lakes and data warehouses.
- Azure Synapse Analytics (formerly SQL Data Warehouse): You can use Native CDC with Azure Synapse Analytics to capture changes made to your data warehouse in real time. This makes it easier to integrate your data warehouse with other data sources, such as data lakes and databases.
- Azure Cosmos DB: You can use Native CDC with Azure Cosmos DB to capture changes made to your NoSQL database in real time. This makes it easier to integrate your NoSQL database with other data sources, such as data lakes and data warehouses.
- Azure Blob Storage: You can use Native CDC with Azure Blob Storage to capture changes made to your files in real-time. This makes it easier to integrate your files with other data sources, such as data lakes and databases.
Auto Incremental Extraction
Auto Incremental Extraction is a feature in Mapping Data Flow that efficiently extracts new or updated data from your data sources. It is a performance optimization that reduces the amount of data that needs to be processed, which improves the speed and efficiency of your data integration process.
With Auto Incremental Extraction, you can specify a column in your data source that is used to track the changes in your data. When you run your Mapping Data Flow, it will only extract the rows in your data source that have been added or updated since the last time the Mapping Data Flow was run. This means that only new or updated data will be processed, reducing the amount of data that needs to be processed.
Auto Incremental Extraction is supported for several data sources, including Azure SQL Database, Azure Synapse Analytics (formerly SQL Data Warehouse), and Azure Cosmos DB. You can use it in combination with Native CDC or as a standalone feature, depending on your data integration needs and requirements.
By using Auto Incremental Extraction in Mapping Data Flow, you can improve the performance of your data integration process, reduce the amount of data that needs to be processed, and ensure that your data is up-to-date and accurate.
Here are some best practices for implementing Change Data Capture (CDC):
- Choose the right data source: Choose a data source that supports CDC, such as Azure SQL Database, Azure Synapse Analytics (formerly SQL Data Warehouse), Azure Cosmos DB, or another data source that provides a CDC solution.
- Use a unique identifier: Make sure to include a unique identifier in your data source that can be used to track changes. This is typically a timestamp or a primary key column.
- Store CDC metadata: Store the metadata that is generated by CDC, such as the timestamp of the last change that was processed, in a persistent store. This can help you resume processing from the point where you left off in case of failures or interruptions.
- Use appropriate technology: Use appropriate technology for your CDC implementation, such as Azure Event Grid, Azure Functions, or another solution that provides the features and capabilities you need.
- Implement error handling: Implement error handling and retry logic in your CDC pipeline to ensure that changes are captured and processed even in the event of failures or interruptions.
- Monitor performance: Monitor the performance of your CDC pipeline to ensure that changes are being captured and processed in a timely manner, and to identify any bottlenecks or issues that need to be addressed.
- Consider data privacy: Consider data privacy and security implications when implementing CDC. Make sure to encrypt sensitive data and implement appropriate security measures to protect your data.
Costs of CDC in Azure Data Factory
The cost of CDC in Azure Data Factory is determined by a number of factors, including:
- Data volume: The amount of data being captured, processed, and stored will affect the cost of CDC. The more data you are tracking and capturing changes for, the more resources you will need, and the higher your costs will be.
- Processing power: The type and number of virtual machines you use to run your CDC processes will impact your costs. Larger, more powerful virtual machines will cost more than smaller ones.
- Storage: The amount of storage required to store the captured changes and the data in the target systems will impact the cost of CDC.
- Networking: The cost of networking resources, such as data transfer, will depend on the amount of data being transferred and the frequency of transfer.
- Data processing: Depending on the complexity of the data processing and transformation requirements, the cost of data processing may be significant.
Implementation of CDC in ADF
Let’s go ahead now and dive into a demo of configuring a CDC process fast and easy. You don’t need to design graphs or learn triggers or anything like that.
First step: Open a new CDC mapping flow in ADF where you need to define your source.
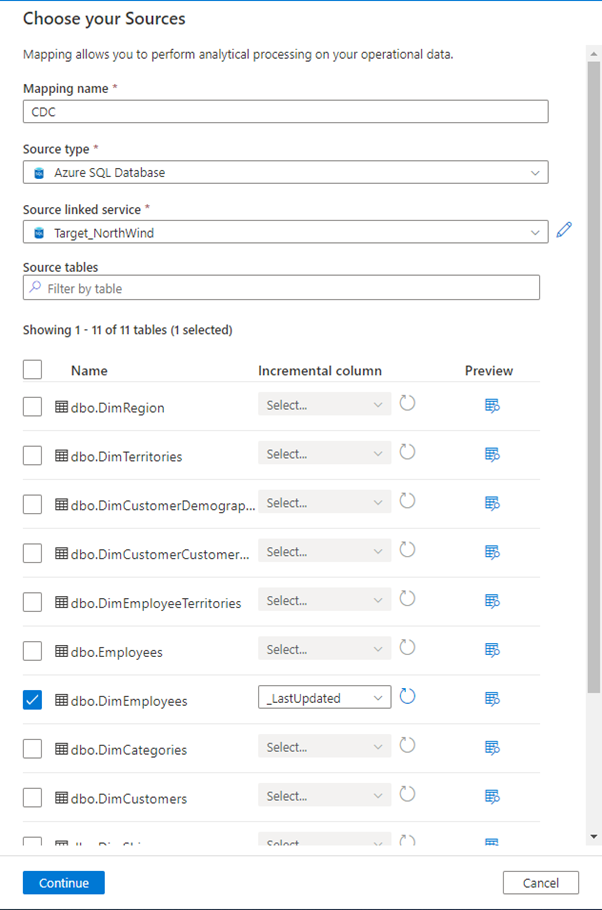
For this demo we are going to use the Azure SQL Database as a Source, but there are several sources you can choose from to implement CDC such as DelimitedText File, Parquet, Avro etc.
We are going to pick the DimEmployees table and as you can see, we also have to select an Incremental column which requires identification of the changes that we are going to make.
In the next step, we need to define the Target where to put the data.
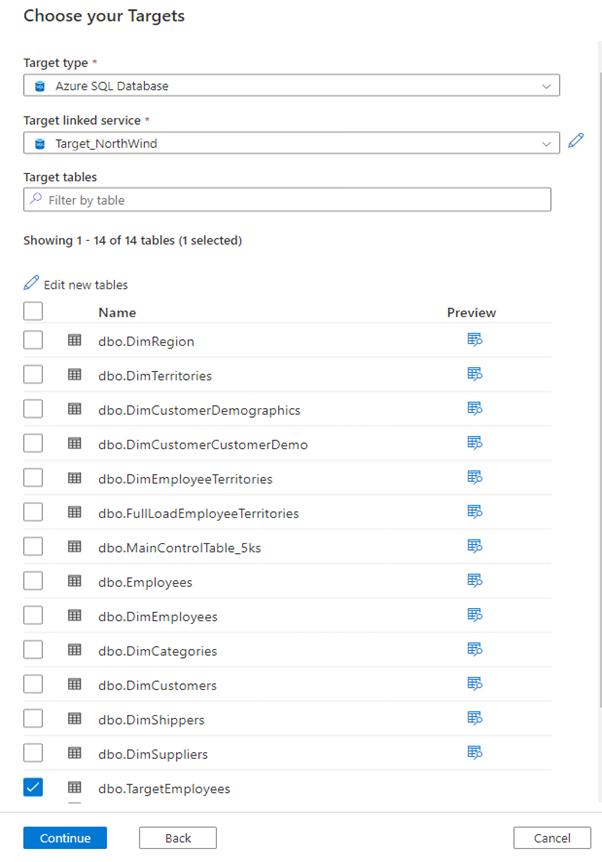
In our case we choose again SQL Database as Target type and we will load the data in the same database, but we will create a new table TargetEmployees. You can do that by clicking on Edit new tables button and then you specify the schema name and table name.
When you finish this process then you will be dropped into primary screen for your CDC resource and you can see the source table which is DimEmployees and the target we defined as TargetEmployees. You can have multiple sources and targets, so you can click on the edit button and add a new ones.
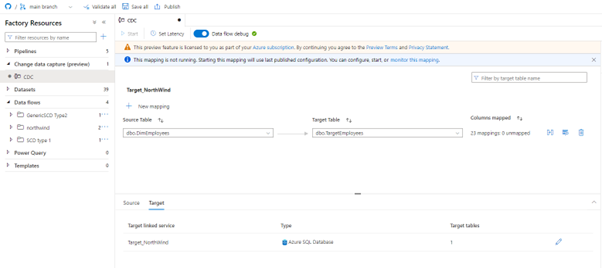
But for this demo we will just map one to one, so we are going to map the DimEmployees data to a TargetEmployees. You can notice that the columns are already mapped, because we have a heuristic that provides fuzzy matching on the columns, but you can define the mappings yourself.
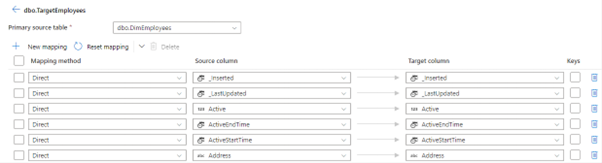
We can see that this mapping is direct which means that whatever is in the columns in source will go into target columns. You can also pick some transformations from the mapping method drop down list such as Trim, Upper, Lower, Derived Column…
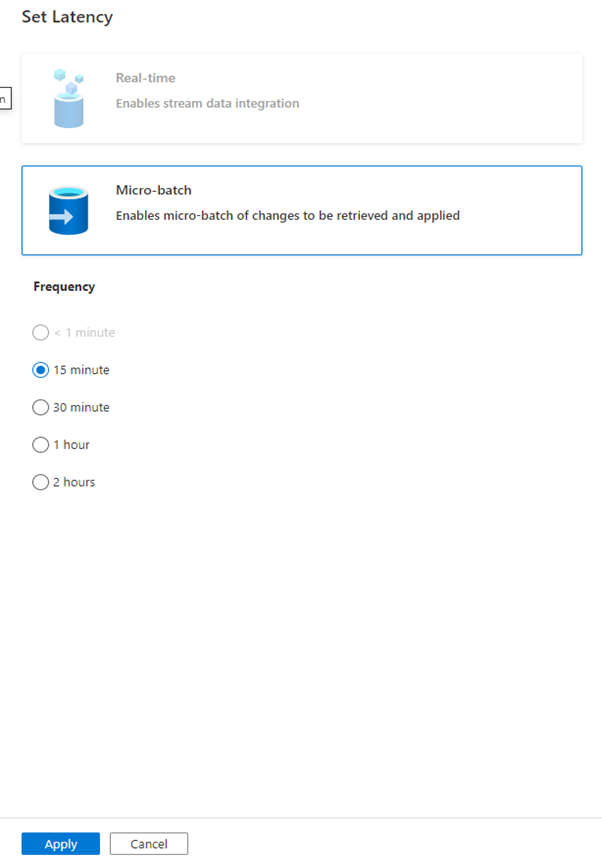
We are almost done, all we have to do is to set our latency. The frequencies available to you as of today are 15 minutes to 2 hours. But as you can see there is less than one minute which is coming very soon and we will be able to track CDC in real time which means CDC process will be continuously running and looking for changes on your sources. As for now we pick up the 15 minutes option.
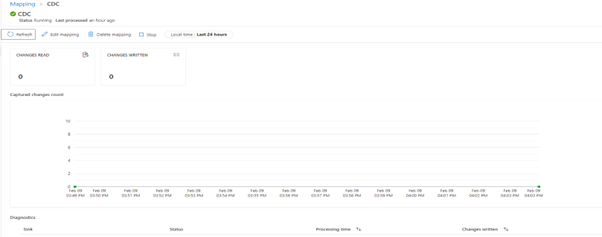
Finally, we publish this and to start this CDC process, we need to click the Start button in the left upper corner. Once it’s running you’ll see that you can monitor the mapping, that’s a new section in monitoring for CDC mappings and that you will be billed for four cores of general purpose data flow. Go to the monitoring tab and you’ll see the Change Data Capture field. There you can see all your CDC processes that are active and running. Every 15-minute occurrence is represented by a green dot. Clicking on the dot allows you to view any changes that may have occurred.
Conclusion
To sum up, Change Data Capture (CDC) is a powerful feature in Azure Data Factory and Azure Synapse Analytics that allows efficient data integration and ETL processes by only reading source data that has changed since the last time the pipeline was run. This can be done through the CDC capabilities in ADF and the Native CDC in Mapping Data Flows, which support several data sources including Azure SQL Database, Azure Synapse Analytics, Azure Cosmos DB, and Azure Blob Storage. Additionally, Auto Incremental Extraction is a feature in Mapping Data Flow that can improve the performance and efficiency of the data integration process by only processing new or updated data. When implementing CDC, it is important to choose the right data source, include a unique identifier, store CDC metadata, and have a clear understanding of your data integration needs and requirements.