
In my previous article on Context Engineering, I explored the foundational practices for building enterprise-grade AI applications. But engineering a robust AI solution is just one part of the entire development lifecycle process.
AI applications are non-deterministic and as such they produce different outputs for identical inputs. Traditional monitoring does not answer whether the solution is generating accurate, cost-effective, or compliant responses. Additionally, there are many Why, What and How questions behind every AI response:
- Why did the model generate that specific answer to this prompt?
- What did each step in the complex agent flow produce as intermediate data?
- How is information passed between retrieval, reasoning, and generation steps?
- How many loops did the system execute? How many LLM calls occurred?
- Which models handled which tasks?
- What was the actual performance and latency?
- How did we arrive at this final output?
- And critically, How much did it cost?
This article examines how dedicated observability practices address these visibility gaps, transforming what would otherwise remain black-box AI experiments into transparent, measurable, and continuously improving enterprise assets. Without it, optimization becomes guesswork and ROI remains impossible to demonstrate.
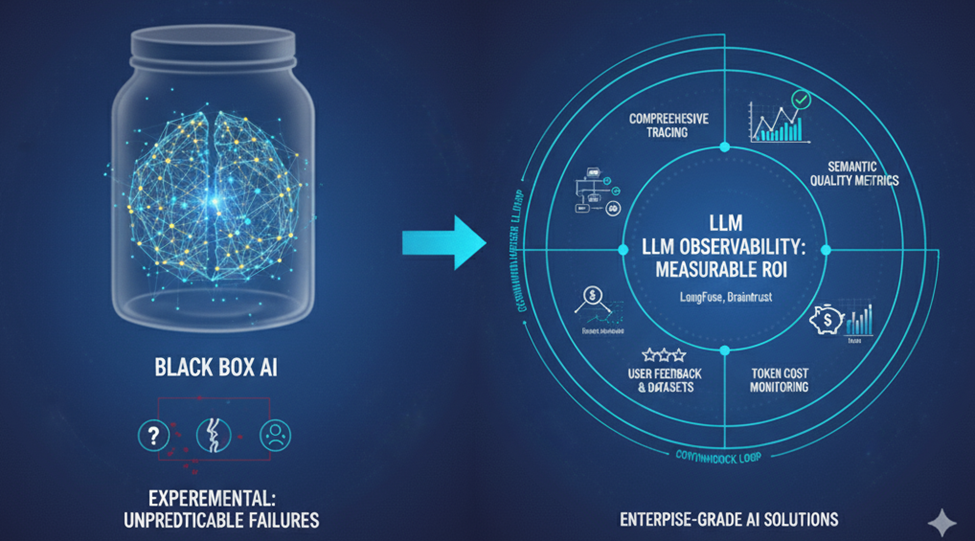
TL;DR: Why LLM Observability Matters Now
LLM observability transforms AI from experimental initiatives into measurable enterprise assets by providing visibility into non-deterministic systems that can fail silently. Unlike traditional monitoring that tracks infrastructure health, LLM observability captures the complete context of every AI interaction.
Key capabilities include:
- Comprehensive tracing of multi-agent workflows, from prompt to final response
- Semantic quality metrics that evaluate accuracy and relevance
- Token cost monitoring across users, models, and use cases
- User feedback integration that builds annotated test datasets
Missing observability system from the start, organizations face predictable failures. Research indicates that 95% of AI projects fail due to operational gaps rather than technical limitations. Quality degradation remains invisible until it surfaces through customer complaints, while unexpected cost overruns occur when token usage spikes without warning.
Bottom line: Enterprise-grade AI solutions require integrated observability platforms (like LangFuse or Braintrust) that create continuous feedback loops, enabling teams to demonstrate sustained ROI through measurable performance metrics and iterative refinement.
Application Lifecycle Differences
Traditional software (development) follows a more predictable path. Development teams write code, QAs test against expected outputs, deploy to production, and monitor for errors and performance bottlenecks. When something breaks, the system throws an exception, logs capture the stack trace, and teams can pinpoint and fix the issue.
AI applications operate fundamentally differently. An LLM can confidently deliver incorrect information with a perfect 200 OK response, showing no errors while quietly degrading user trust. Agents can initiate multiple LLM calls, trying to improve themselves, but without success while significantly increasing costs. Users can try LLM jailbreak, or input and output can contain hate speech with 200 OK attached to it. This can violate business policies without triggering a single alert.
The probabilistic nature of AI systems introduces complexity that traditional monitoring simply cannot address. Development and QA teams need visibility into not just whether the system is running, but whether it’s delivering accurate, cost-effective, and compliant results to users.
(LLM) Observability as the Ultimate Monitoring Strategy
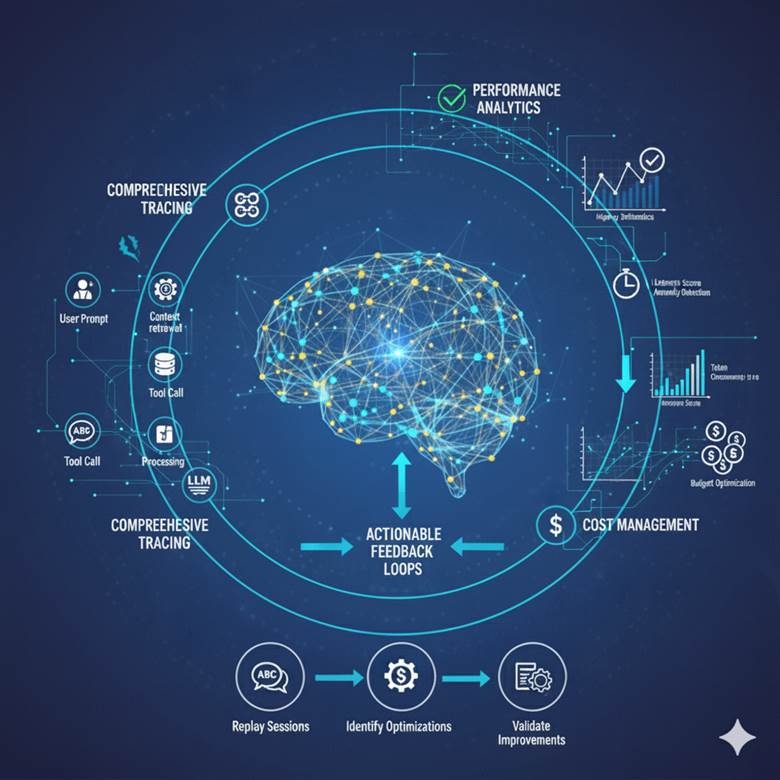
Observability extends beyond traditional monitoring by capturing the complete context of every AI interaction. While monitoring answers “is something broken,” observability enables teams to ask “why did this happen” and “how can we improve it”. LLM observability addresses challenges unique to generative AI systems. Traditional observability focuses on technical metrics like CPU usage, memory consumption, and API latency indicators that confirm infrastructure health but reveal nothing about output quality. On the other hand, modern LLM Observability platforms track these three critical dimensions:
- Comprehensive Tracing: Captures every step of the AI workflow, from the user prompt through context retrieval, tool calls, model processing, to final response generation.
- Performance Analytics: Identifies latency bottlenecks, attaches a response quality score, and detects anomalies in model behavior.
- Cost Management: Monitors token consumption across users, models, and use cases to prevent budget overruns and optimize resource allocation.
LLM systems require semantic monitoring that developers and QA can use to evaluate whether responses are accurate, relevant, and aligned with business requirements (as part of AI Evals discipline). Additionally, a good observability platform track prompt variation, model reasoning paths, retrieval quality from vector databases, and the semantic correctness of generated content. Token costs represent another critical metric absent from traditional monitoring, as LLM API providers charge per token with costs varying dramatically across models and prompt strategies.
The observability lifecycle also differs. Traditional monitoring activates post-deployment, while LLM observability spans the entire development cycle, from initial experimentation through QA testing into production. A consistent visibility across environments is required to validate improvements before they reach users and establish quality baselines that guide automated evaluation.
Integrating User Feedback and Building Iterative Testing Datasets
User feedback transforms observability from passive monitoring into active quality improvement. Effective platforms enable explicit feedback mechanisms like ratings, likes, comments from actual users. With it, we can calculate metrics such as response acceptance and task completion rate.
The strategic value emerges when evaluation responsible teams link feedback to specific traces, annotate it properly, and use it to build targeted test datasets. A negative rating on a particular response becomes more than a data point. It’s a labeled example that reveals failure patterns and guides prompt and/or context optimization. Organizations can identify responses that consistently receive poor feedback, analyze the prompts and retrieved context that produced them, and systematically address root causes.
Annotation workflows allow evaluators (subject matter experts) to review flagged interactions, classify failure types, and create golden datasets for the next testing cycle, a process mentioned before, “AI Evaluations”. This continuous enrichment of test data ensures that as applications evolve, quality benchmarks reflect real-world usage patterns.
The Cost of Neglecting AI Apps LLM Observability
Organizations deploying AI Solutions and Agents without robust observability face predictable failure. Recent news about research made, indicates that 95% of AI projects fail, with the majority of failures stemming from organizational and operational gaps rather than only technical problems and limitations. Without visibility into AI App or Agent behavior, failures remain invisible until they escalate into business disruptions, customer complaints, reputational damage, or worse => security incidents. By the time these issues surface through customer complaints or incident reports, the damage is done.
Cost management failures present another common pitfall. Organizations experience unexpected bills when token usage spikes without warning, or when inefficient prompt strategies consume excessive tokens without delivering proportional value. Teams lacking cost observability cannot identify which users, features, or use cases drive expenses, making optimization impossible.
Better Approach to Enterprise AI Quality
The AI landscape is rapidly evolving, with the community learning from challenges to develop essential solutions like LLM Observability platforms (e.g. LangSmith, LangFuse, Arize, Braintrust, etc.). Systematic observability shouldn’t be a fix for problems, it should be integrated into every AI solution we deliver from the start. Our disciplined approach ensures sustained value by:
- Comprehensive Tracing: Tracking multi-agent workflows and validating accuracy, relevance, and compliance through continuous quality evaluation before and after deployment.
- User Feedback Loops: Transforming production interactions into actionable improvement signals and building annotated datasets that drive iterative refinement.
- Cost Monitoring: Providing detailed visibility into token consumption patterns to help clients understand AI economics and make intelligent optimization decisions.
This methodology answers the core executive question: “How do we know this investment will deliver sustained value?” by transforming AI from an experiment into a reliable enterprise capability through measurable quality and continuous optimization. Quality assurance and observability should be a first-class concern, not as technical late addition. Demonstrating ROI requires more than showcasing impressive demos, it demands evidence of consistent performance, cost efficiency, and continuous improvement over time.
We at IWConnect have been working and delivering AI solutions for a while, and we are sure that without this proper setup, every AI project is at risk. Exchange your “I think” with “I know” where it fails by having comprehensive tracing with LLM Observability setup and platform.