
The latest development of the COVID-19 pandemic led to maximized online consumption and it proved that an advanced e-commerce platform is “a must” for businesses to survive. Although online shopping itself, serves the same purpose as classic shopping, it has a completely different user experience. One aspect which is really important in the shopping activity is the process of finding out what will the user purchase next. Or, will the customers buy more from their targeted product? In the offline world, products are placed in different sections and users can have their senses aroused (visual, smell, even sounds will attract them) to buy more products. But when shopping online, they can only see a limited list of products on the screen, and the online platform can only “guess” what they would like next.
By using technology, customer satisfaction can be significantly improved as there are ways to measure what the client wants and ultimately increase sales. This doesn’t mean offering random products but with precisely data-driven selected products for every unique customer.
In this blog post, our focus is on using an engine that can be leveraged to guess what the customers would want, i.e. we are going to describe the RECOMMENDER ENGINE, powered by graph databases.
The recommender engine that you will use will make the difference between a good, solid, and outstanding e-commerce platform.
Every single multibillion e-commerce enterprise, such as Amazon, Walmart, or E-bay uses a different type of approach in order to provide real-time recommendations to their users. The engine could be engineered based on different approaches, some of which are:
- content-based: where we compare item descriptions and categories, then we create similarity based on a different characteristic,
- collaborative filtering: when users’ past behavior is used to determine the behavior for the future.
- session-based: when the recommender is built based on the session data, such as clicks and the user’s behavior in the actual session.
- context-aware: when the actual context is considered (location, time, company, who is the user with, etc.)
- hybrid recommendation systems use a combination of different approaches for a better result.
In any case, the goal is to provide a real-time shortlist of products that the user could be interested in, based on Machine Learning algorithms or other techniques.
In the last few years, novel graph database technologies have emerged as the most effective solution for powerful real-time recommendation engines. The graph technology outperforms traditional relational databases (RDBMS) and other NoSQL data stores in terms of speed and complexity. Graph databases are more than a thousand times faster versus SQL solutions and require 10–50 times less amount of coding, according to the early adopters.
The technology giants were using their own graph database solutions that were not available for wide usage.
As part of our e-commerce implementation with Commerce Tools, we have built our recommendation engine based on graph databases. The solution works both for products and users and uses a machine-learning algorithm.
For the initialization, we take historical order data to populate the graph database with customers and products. The first step is to create a relation between them if an order happens. Then, we calculate the similarity link between products based on purchase history.
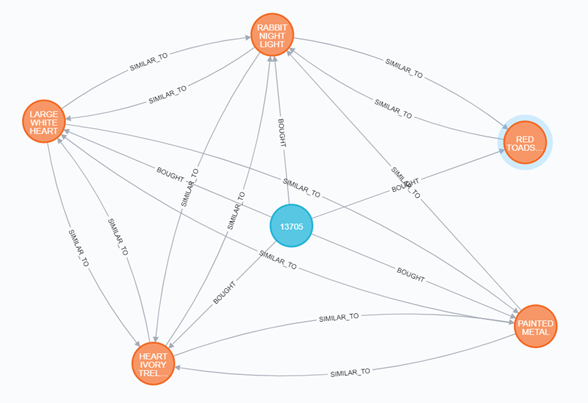
User 13705 bought five products, they all have similar links between each other with different weights.
The similarity matrix calculates the value of similarity after comparing each node and its historical order. Once we have the similarity values stored, our recommendation engine is ready to accept requests and calculate most products. In the data set we used for training we had 5000 products and 3000 users, the algorithm for similarity created over 3 million relations between the products based on the order history.
Our e-commerce platform in real-time sends requests for a specific user and specific product through the API. The engine gets the ID from the product and the user and calculates the top N recommended new products in a few milliseconds. This performance cannot be imagined to be conducted if we use RDBS instead of a graph database.
The communication between the e-commerce platform and the recommender engine is provided by the REST endpoint.
Implementations
This recommending process is implemented with various use case scenarios:
- personalized recommendations for each unique customer after the user’s login to the platform
- when the customer opens some product details page, the system recommends other products, based on the product history order
- when a product is added to the shopping cart (similar to the previous one)
- after the checkout
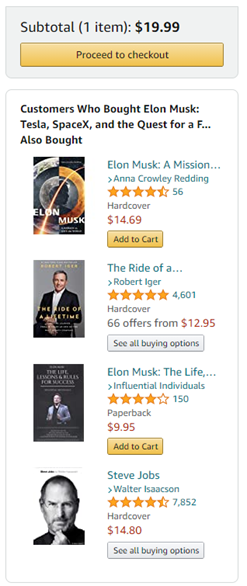
An example from amazon.com is when a product is added to the shopping cart.
- For commercial purposes, we can also add promoted products in combination with the recommended products. This should be a carefully crafted business decision, because, we can irritate the customer and have negative effects.
Measuring results
In order to be reliable that the recommender reached its goal and appliance, we can provide a few approaches to measure the results.
- Depending on the business model where we implement the RE we can count the clicks on the recommended products.
- We can count the time spent by a user if we are using the recommender on a streaming music or video platform.
- We can sum up the ratings provided by the users on our recommended items if the business is in movies/books or is some kind of platform where users can read online stats, or watch movies.

Business benefits of using the solution
The benefits of using the graph database recommendation engine are various. On the customer side, it brings more satisfaction while shopping, many times they return to the page only to check the recommended products, which influences customer retention. Different usage of the engine will bring a personalized list of recommended products, which also helps the customer with the discovery of new products.
On the business side, it affects the revenue as a crucial benefit, along with even more significant data that comes out from the usage of the system. Once we analyze the data you can turn the recommending engine cycle once more to your business interest.
Conclusion
Our recommender is a box-independent service and is easy to implement on existing solutions. The solution is scalable and quickly returns results. The recommender can be implemented on different e-commerce tools such as Commerce Tools, WooCommerce, Magento, 3DotsCommerce, or any other e-commerce platform. It increases sales, and customer satisfaction, and provides feedback on what your customers really want and how they behave.
The usage of this recommendation engine can go beyond e-commerce implementation. Different use cases where we have users and content have more or less the same problems. Based on past history we are calculating the best fit for the unique user, it can be streaming media, social media content, listings for booking, and many more.
If you want to see how the Recommendation Engine works, feel free to contact us.