Navigating the complexities of data transformation is a recurring aspect of working with Mule 4, a popular integration platform used in modern business technology stacks. An aspect that often requires attention is the handling of unexpected, encoded characters. While some may encounter such characters rarely, others may grapple with them frequently, depending on the specific sources of data they work with. So, understanding how to overcome and manage these odd characters is an important skill for anyone using Mule 4.
You may need to change these unexpected, encoded characters or replace them entirely based on what your program can accept.
Whether these characters exist in your input by default or arrive unexpectedly, understanding how to reference them, and when to require specific methods to deal with them, is integral to maintaining seamless workflows. In the following sections, we will delve deeper into the strategies and techniques to deal with these situations.
Extract HTML Content (HTML tag stripping/HTML entity decoding) In MuleSoft with help of Java.
Overview
In MuleSoft, sometimes we receive HTML documents in a string format containing tags and encoded HTML special characters, and we want to extract only the content of the HTML document.
Problem
In MuleSoft, there is not a native solution to extract only the content of the HTML string, but thankfully, MuleSoft is fully integrated with Java, and we can use this feature to solve this kind of issue.
Solution
JSOUP is a Java library for working with HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CSS selectors.
Step 1.
First, we need to import JSOUP dependency in the POM.xml file in our MuleSoft Application.
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version> </dependency>
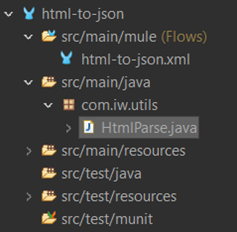
Step 2.
In this example, we are creating a Java class where the logic will be implemented under the package “com.iw.utils” in the directory “src/main/java”.
Step 3.
After that, we need to populate the newly created Java class with one method provided by JSOUP, which receives the html string and returns the content of the html after tag stripping/ entity decoding:
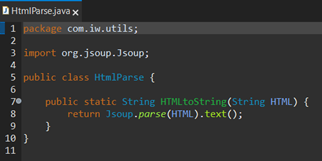
Step 4.
In our application, in the Transform Message where the conversion is needed, we are importing the Java class, invoking the HTMLtoString method that we created from our custom class HtmlParse, and providing the HTML document that we want to convert.
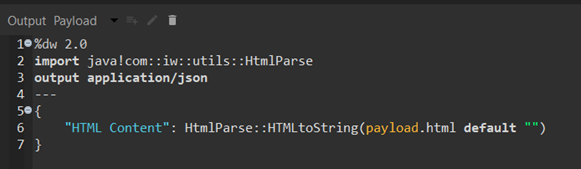
Step 5.
Input that the Transform Message will receive. As we can see, there are HTML-encoded elements and HTML tags like “<p>” and “'”.

Step 6.
The HTML tag stripped/entity decoded content is in the output, and as we can see in the In the picture below, it is as we expected.

Escaping encoded characters from XML in MuleSoft
Overview
In MuleSoft, sometimes we receive SOAP service XML responses containing encoded characters.
Problem
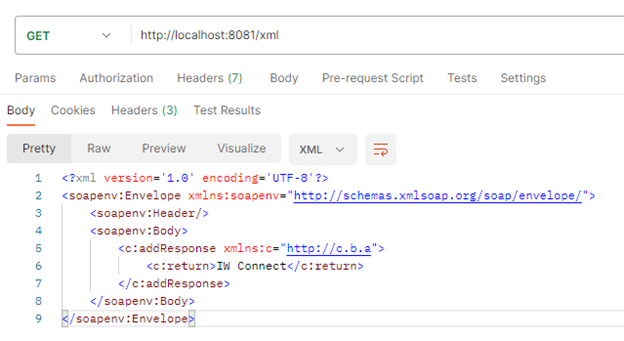
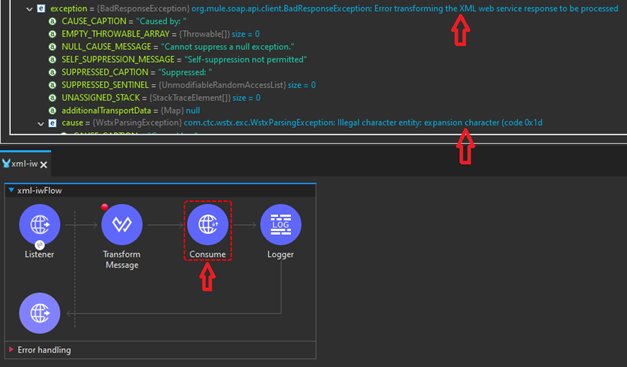
In MuleSoft, there is a connector named Consume from the Web Service Consume module that is used to communicate with SOAP services specifically. The Consume connector has a limitation in that we are receiving XML responses containing encoded characters (example: ) and the connector itself is trying to parse the response in XML format, the Mule engine is throwing an error due to the encoded characters. As a workaround for this kind of issue, we are using an implementation consisting of the Request Connector from the HTTP Module.
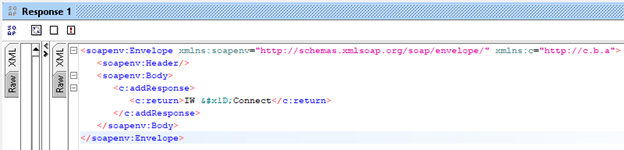
The SOAP service response as shown above and the error that is produced using the Consume connector below when accessing the SOAP response above.
Solution
Step 1.
Instead of using the Consume connector, we are setting the HTTP Request connector, and before receiving the desired XML values from the response, make sure that XML content is serialized (raw string), which you can do by setting the HTTP Request component MIME Type to text/plain.
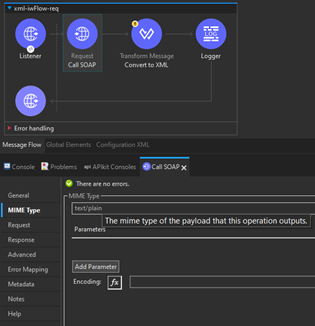
Step 2.
After getting the response in text/plain format, we are setting the Transform Message component with the following DataWeave expression so we can convert the text/plain formatted XML content into XML format while escaping the potential invalid character or characters:
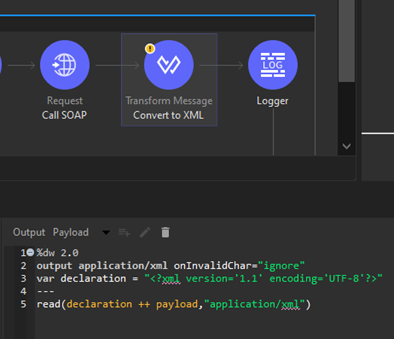
We are prepending the XML declaration with the 1.1 version before parsing the message and setting the additional property onInvalidChar with the value of ignore to escape all unsupported encoded characters during processing of the XML message. After the conversion, we will have an XML-formatted SOAP response where, when the SOAP Consume component was used, an error was raised. The output of the solution can be seen below: