

In this blog post, we will share our firsthand experience with the innovative automated testing solution developed by the dedicated QA team at ⋮IWConnect for a prominent client in the banking sector.
Our new happy client required an enterprise-level solution for data migration, data sync, and testing their newly gathered data. Faced with the challenge of ensuring the accuracy of the transferred data, our QA team embarked on the task of devising an intelligent and fast solution. What followed was the development of a groundbreaking automated file testing methodology, enriching the testing landscape.
To put the impact into perspective, previously it was impossible for our client to manually verify all information regardless of the team size, resulting in invalid data and therefore, faulty decision making. Today, with our automated scripting, this whole process is accomplished in a couple of minutes. This metric underscores the remarkable efficiency gains, the precision and the transformative power our automated testing solution brings to the table.
The File Automation Project
Due to the nature of the client’s system, there was no cloud storage involved, and the requirements were:
- populate the database tables daily from system one on the remote server,
- transform the data into separate CSV files,
- test the files, and finally,
- reexport them to system two, that does the data analysis & reports back.
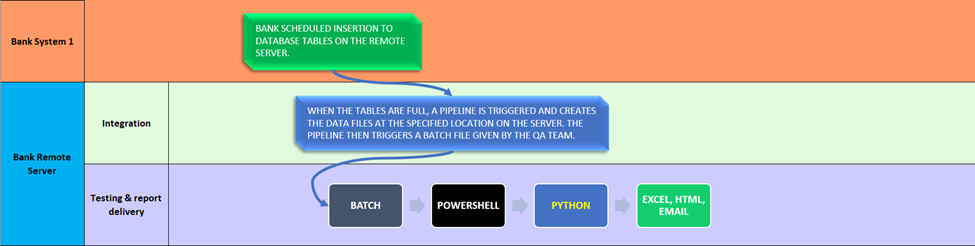
The process in its consecutive phases
In response to these requirements, we managed to automate:
- scheduling the testing time,
- reading multiple files,
- testing the files,
- writing test reports,
- beautifying the test reports, and
- emailing the test reports.
Domain Knowledge
Each of these files represents a different domain, like Customers, Accounts, Transactions, and so on. All of them contain sensitive data that we handle in a safe and sensible manner, which we do with every client we work with. The files have specific structures and rules they must adhere to so that system two does the data analysis and returns correct reports, on which the business makes the right decisions.
After analyzing the project requirements and specifications, we started writing test cases and developing programmable tests to create and automate the data validation process based on our specifications. For this purpose, we chose Python and Pandas library.
Test Automation Steps
Initially, we create a Python script and load the file under test with the following code:
- self.df represents a data frame that contains the file data
- self.file_name contains the name of the file, and
- the delimiter parameter is the value with which the values in the CSV file are separated from each other.

After loading the data, we immediately start programming the tests with testing logic according to the project requirements.

Test for the table column ‘TRANSACTION_DATE’
The tests are reliant and fast, even when the files under test are Gigabytes size big – with millions of rows.
We validate:
- File names,
- Column names,
- Column values with/out quoted strings,
- Total row count (i.e. to connect to a database and compare the results),
- Allowed number of decimal places present for table columns like ‘Account balance’ or ‘Transaction Amount’,
- Date(time) format validations,
- Enum values (limited list of values allowed to be in a column),
- Empty or null values,
- Multiple column value comparisons (if A equals B, then C… conditions).
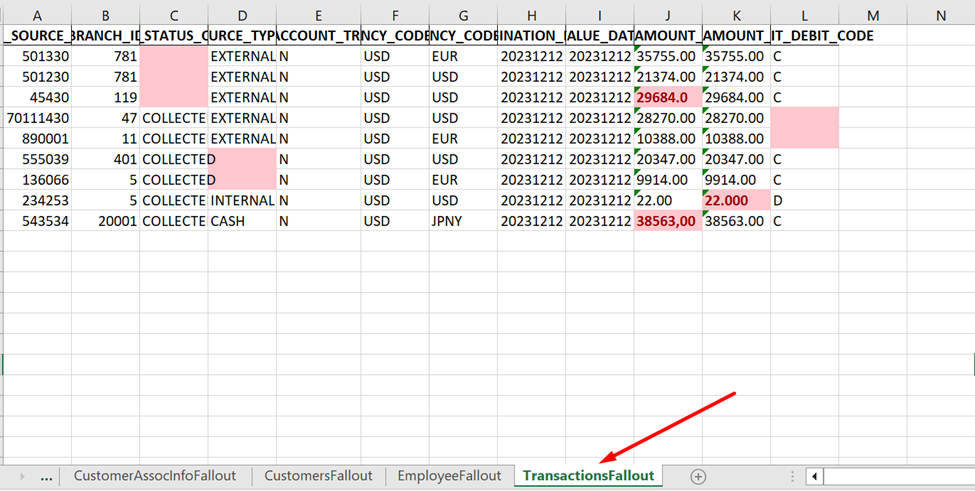
The next step is gathering the test results in one and present it in a nice visually appealing manner for the client to review. We chose Excel spreadsheet as the export file format to structure the data in, and visually mark the invalid data cells with a color of choice, for ease of use for the report recipients. The spreadsheet contains records (rows) with invalid data found during the testing.
In the last step, the detected invalid data is processed, written, and beautified with our method into an Excel spreadsheet.

Test Report
We automated creating and populating the spreadsheet in the following manner:
- One sheet per CSV file with its respective columns, and the incorrect data is printed underneath the columns in that same sheet,
- If a row has multiple incorrect values, no duplicate rows are printed in the sheet. Each row’s incorrect cell value is correctly marked with a red color and a cell background color,
- A separate sheet containing the data validation rules for each file is added so that the recipients of the report (the client’s employees) will not need to look them up every time the report comes in, they will save time by simply switching to that sheet.
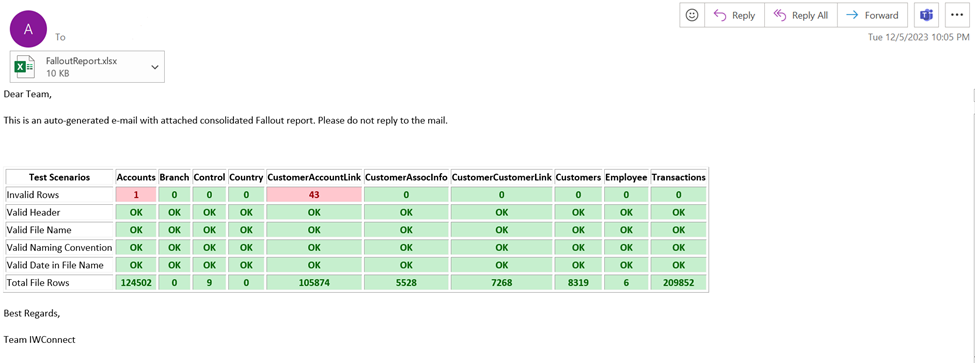
The second half of the report is an HTML table as a detailed report pertaining to the files’ names, naming convention, total rows per file, files’ headers, and dates in the files’ names. The cells with the data present in the HTML table that has broken the specification rules is accurately marked with special formatting (font, background color, emphasized text etc.).
Finally, we automated the report delivery too, writing the HTML error report inside the email and automatically attach the Excel test results. After this email is created, we send it to a list of recipients using the client’s email service API. Through this API we send the test reports every day without human intervention in an auto-generated email. Each email is marked for which date it has been sent in its subject.
Conclusion
Summarizing our presentation, we conclude the automated testing solution is a definite benefit for our banking client. The transition from days of manual verification to mere minutes with our solution exemplifies the efficiency gains achieved.
Beyond raising our client to a higher level of competency, this innovation sets a new industry standard in QA. It highlights the transformative potential of technology in revolutionizing traditional practices, particularly in critical sectors like banking.