
November is dedicated to one of the biggest conferences occurring in the world of data – Data Science Conference Europe 2020. It is considered to be one of the largest Data & AI conferences and the fastest growing Data & AI community in Europe. The conference is a connector for businesses, professionals, and academia all in one place. ⋮IW was part of this amazing event with Cvetanka Eftimoska as a speaker on the topic Data preprocessing for Machine Learning using Python inside of the Data & AI Research track. We decided to ask her more about data management, future trends related to AI and ML, and the conference itself.

Can you tell us more about your experience in disruptive technologies?
I have eight years of professional experience in the software industry. Some of the technologies that I have worked on are Relational databases and SQL, defining ETL processes, and data warehousing. Also, I participate in BI projects by using enterprise interactive data visualization platforms. Lately, I am focused on Machine Learning, Deep Learning, and Artificial Intelligence. One of the primary goals in our data management team is increasing data efficiency, or focusing on how to extract the most important and valuable information that is contained in the data. We work on using machine learning algorithms to improve the process of extracting and analyzing the data.
How does AI improve the technology world and what are the potential areas where AI is most applicable?
AI is not something that will happen in the future, but rather something that is present today. I expect that AI will improve in complexity and availability in the future. AI solutions are already applied in some sectors like finance, health care, data protection, and so on. There are practical examples of how AI improves decision-making. For example, AI can provide recommendations to a user or improve diagnostic pathology in health care.
“AI is one of the fields in which women can achieve tremendous success – the organizations must include women in order to obtain a higher level of maturity in AI.”
As a data analyst, what is your insight on the digital transformation process in general and the need for such transitioning?
Digital transformation involves a large number of processes such as interactions, transactions, technological evolutions, changes, internal and external factors, industries, and so on. This change requires time, particularly a profound change that influences all aspects of a business. With digital transformation, enterprises will have real-time information, greater visibility, and operational insights. Additionally, it makes the information available and that is critical for discovering patterns and understanding why certain techniques are more effective.

Why is data management considered to be the career of the future?
Data management as a process consists of multiple steps such as collecting, storing, organizing, protecting, verifying, and processing. Data processing actually extracts the essential data and reveals business insights. This is the career of the future because of the importance of data insights for any modern business. A proper data management process increases productivity, reduces security risk, minimizes data loss, and improves data quality. Every company today has a lot of data, and with the proper management of data, companies can make decisions based on measurable evidence – the data.
Why do you consider that Data preprocessing for Machine Learning was a hot topic at this conference?
Data preprocessing is a data mining technique that involves transforming raw data into an understandable format. It aims to facilitate the training/testing process by appropriately transforming and scaling the entire dataset. Additionally, preprocessing is a critical step in machine learning and is very important for the accuracy of the model. If you use questionable and dirty data what will be the final result, and can the decision be trusted? That’s why data is preprocessed. The ultimate goal in this step is to get more meaningful data that can be trusted. Also, data is truly considered a resource in today’s world. As per the World Economic Forum, by 2025 we will be generating about 463 exabytes of data globally per day. Can we use that data? The complete data? Of course, we can’t – we must first find out which data is useful, clean that data and prepare it for a machine-learning model. Machines don’t understand free format text, image, or video data as it is so we can’t expect our machine learning model to get trained based on this data. That is why we are preprocessing the data. I discussed the following preprocessing techniques at the conference: Handling missing values, Dealing with outliers, Multicollinearity, Dealing with categorical features, Balancing the dataset, Standardization / Normalization, Shuffle the data, and Split into train and test sets.
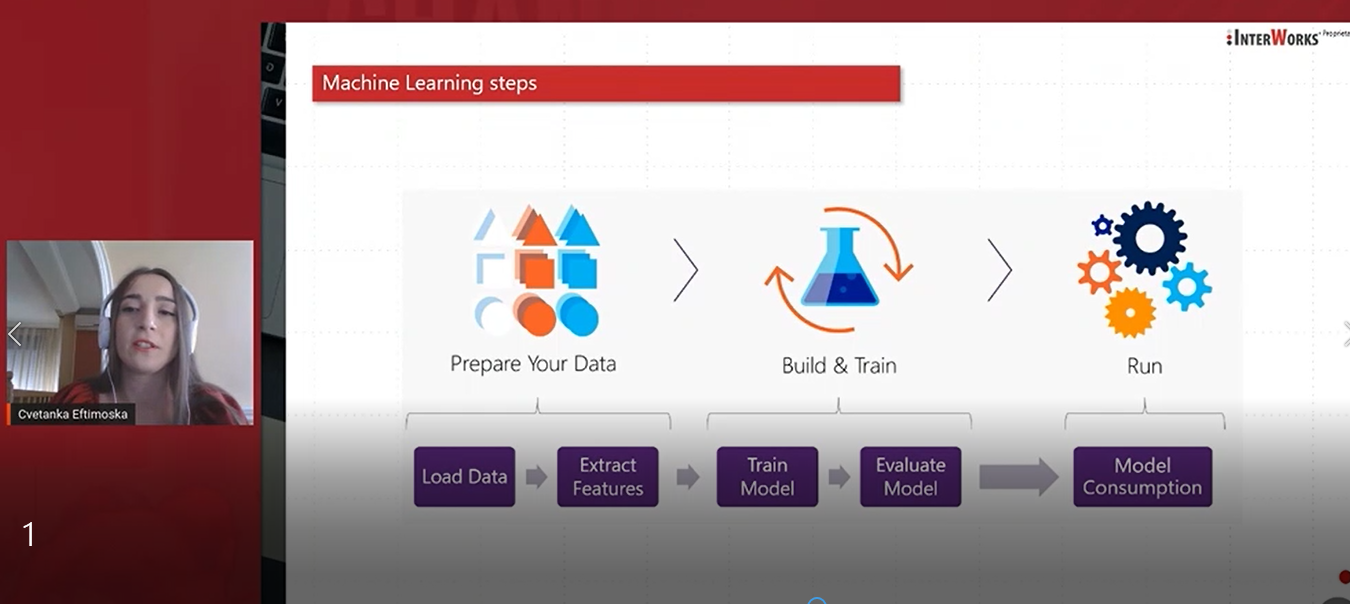
What is one key takeaway from your findings?
Machine learning denotes a step forward in how computers can learn and make predictions. Applying machine learning and analytics more widely lets us respond more quickly to dynamic situations and get greater value from fast-growing troves of data.
Do you think that ML and AI will be the future in the technology industry?
Definitely yes. AI could help optimize and speed up diagnostic procedures in healthcare. For example, an analysis of cancer tissue can be improved with AI recognition. We can’t completely and precisely predict every way in which AI will impact businesses, but we are aware that the influence will be both profound and disruptive.
Was it challenging to speak at such a big conference?
It was a real pleasure to be part of the conference. At the same time, it was an honor to be one of the two speakers from our country at such a massive event. The organization was on a high level, and everything was planned in advance. The conference itself was a great opportunity to exchange ideas, extend our knowledge, and meet new experts in this field.

How did you like the conference overall?
I had the chance to attend tech talks and I can say that there were a lot of things that we can share and learn for sure. Also, we had networking sessions with all the speakers and that was an opportunity to meet people from all around the world. I hope that the next year we can meet in person and attend the live event. There were a lot of amazing speakers as part of the conference and some of the most trending topics in the Data world were discussed. All in all, a great experience I would definitely go over again.