
Introduction
Have you ever found it difficult thinking and finding a way to handle remote call exceptions that might take an unknown period of time to recover? These exceptions can occur because of many reasons, such as the service being unavailable, too many requests, slow network connections and so on.
For example, if the service you are triying to reach sends a status code of 429 – “Too many requests”, 503 – “Service Unavailable” etc, the likelihood of making a call right after that response and hoping it would succeed is small.
Let’s say it is a status code of 429. If you try to send a request/s right after it, it would only prolong the problem which is a lose-lose situation. The best thing to do in this situation is to retry calling the service after a while and see if the service is still overloaded with requests/unavailable or is it up and ready to process new requests.
One of the best ways to deal with these issues is to implement the “Circuit Breaker” design pattern.
The Circuit breaker is a design pattern used in modern software development. It is used to detect failures and encapsulates the logic of preventing a failure from constantly recurring, during maintenance, temporary external system failure or unexpected system difficulties.
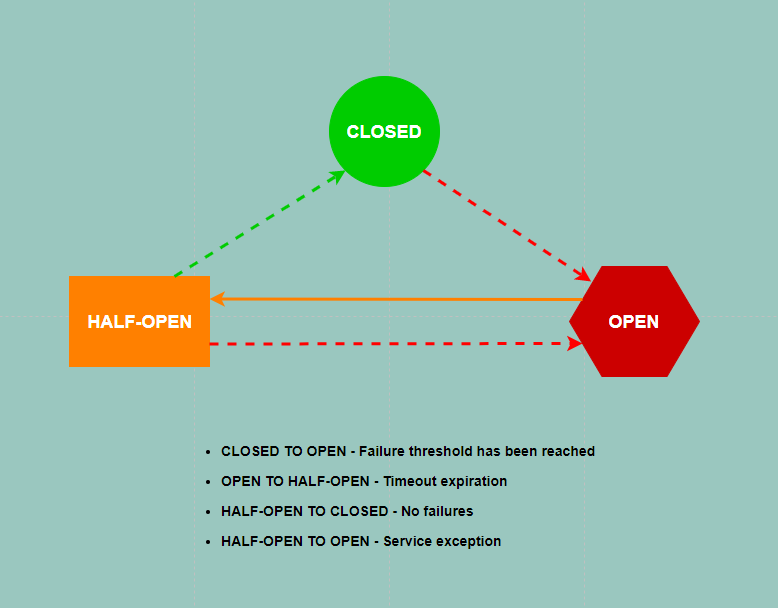
The Circuit Breaker consists of three states:
- CLOSED – The call to the service is executed repeatedly until it reaches the predefined failure threshold or it processes successfully. If this state is active it means that most of the calls made to the service have been successful. When the failure threshold has been reached, the state of the Circuit Breaker will be changed to OPEN.
- OPEN – For an extended period of time no calls will be realized, instead any instance that tries to make a call to the service will get a response consisting of the last error which tripped the Circuit Breaker state from CLOSED to OPEN without actually making a call to the service. After the timeout has expired the Circuit Breaker changes the state to HALF-OPEN.
- HALF-OPEN – This state is basically the same as the CLOSED state except it has one key difference and that is the failure threshold. In this state the failure threshold is set to 1, meaning a call will be made to the service only once. If the call is successful the state of the Circuit Breaker goes back to CLOSED and failure count is reset to 0, otherwise, it goes back to OPEN. Keep in mind that you have to define a terminate condition because it can go on in a loop for a long time without actual results.
Implementation in Tibco BW6 / BWCE
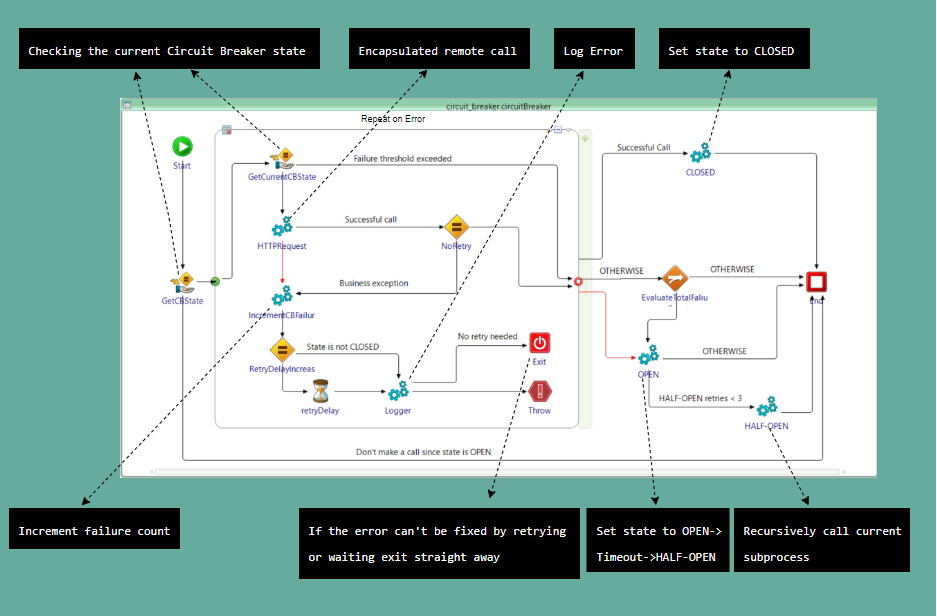
This picture is basically where the magic happens.
- The ideal scenario is when the state is CLOSED and the call is successful. However, the state is not always CLOSED which is why the state of the CB is constantly checked in order to minimize making remote calls which we know for sure are going to fail.
- We determine if the remote call is bound to fail by the nature of the failure. The failure threshold is the key to how many remote calls we make. What I want to say by that is that each time a remote call is made and it fails for whatever reason, the failure threshold is incremented up until the point it reaches that threshold. This is accomplished by using a shared variable, which means each instance of this subprocess checks and/or changes the same failure threshold state.
- After an unsuccessful remote call, there is a timeout that is longer with each failure until the failure threshold is reached.
- In the case of the failure threshold being reached, the state of the CB is set to OPEN and after a certain timeout, it switches to HALF-OPEN.
- When the state is HALF-OPEN it is important to note that the failure threshold limit is 1 and if it fails it goes back to OPEN state.
- Any unsuccessful remote call is being logged so we can keep track of the messages that failed, the reason, timestamp, CB state, failure count, etc.
Performance testing
In order to test the performance of the CB, I was processing messages left on an EMS queue and also made myself a service stub.
- The service has a maximum quota of 200 calls per minute.
- The quota limit is being replenished every single minute.
- After the quota for the remote calls in the current minute has been used up, the service throws a throttling exception. As far as the behavior of the remote service is concerned, I predefined it by myself.
- In 12 minutes you can use up to a maximum of 2400 quota.
The current test had 2395 messages published on a JMS queue.
- Started processing the messages at 15:30:01
- All messages were successfully processed at 15:41:50
- Service calls that exceeded the quota limit at some point: 48
- Closed state failures each time the quota limit is exceeded before it enters into Open state:
8. * The reason there are 8 or lower every single time is because the maximum threads are configured to 8. *
All 2395 calls from the maximum allowed quota were used up within 12 minutes with only 48 calls exceeding exceptions in achieving so.
All 48 instances that failed simply weren’t confirmed through the JMS which means they were never lost in the process. If that wasn’t the case, we could always add another subprocess for all failed messages to be logged in some way. For example, they could be written in a file, inserted into a database, etc.
Here is a graph representation of the results above:
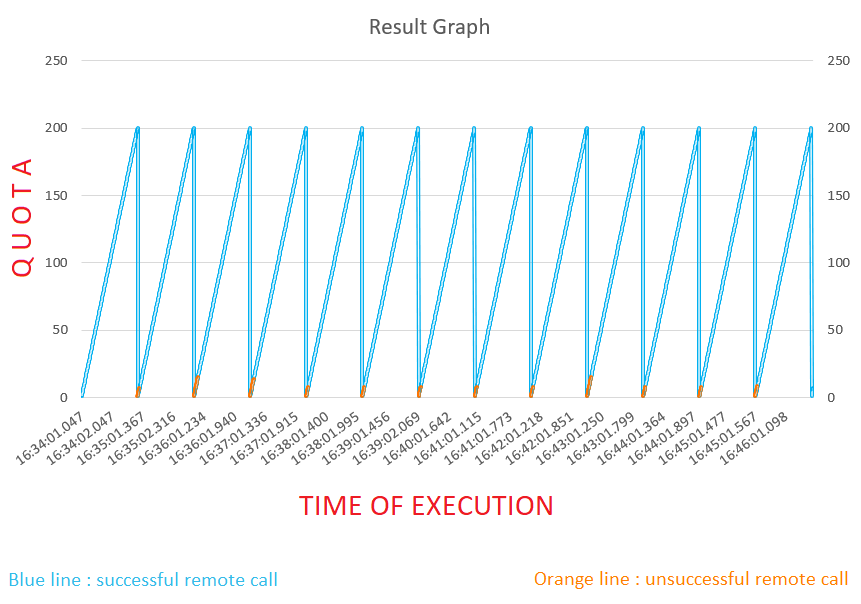
As we can see, the blue line is rising up until the point it reaches 200 quotas. After that, there is a linear fall of the blue line and a small rise of the orange line. In that period there are a few unsuccessful calls being made before the CB determines it should change the state and not allow calls to be made.
Conclusion
The Circuit Breaker pattern can very easily slow down an application, not only regarding the performance, but it can also affect the processes that are dependent on some other time-restraining processes. That is why you should always think carefully before you implement it.
However, if you do decide to implement it you will basically have a modified retry mechanism which is really good at dealing with exceptions that can be dealt with just by waiting for a certain period of time depending on the situation and exception. It is also good at detecting when the application should stop sending requests if the service call exception is not likely to be fixed just by retrying right after a failed request.