

What is workflow management?
These days, the flow of information, data, and documents within a company is enormous. Companies usually use the good old cron jobs (and schedule them in order to start), or vendors have triggering capabilities on their packages already. But then, more data and more documents are coming and eventually, the next step will be to have scripts call other scripts.
That can work for a short period of time.
Workflow is a set of sequences or steps of tasks through which a piece of information passes from initiation to completion. It consists of an orchestrated and repeatable pattern of activity that tells us about the work’s execution and data flow. If the steps are individual and no data flows between them, then it is not a workflow.
Workflow management helps IT to more easily manage complex tasks and workflows, and string together multiple tasks in order to execute a larger process.
How Airflow fits in
Apache Airflow is an open-source workflow management platform. It began in October 2014 at Airbnb, as a solution for managing the company’s increasingly complex workflows. In 2016 it joined the Apache Software Foundation’s incubation program and is still in that stage.
Airflow is written in Python from the ground up. But then again, if English is the language of business, then Python is the language of data.
The main purpose of Airflow is to help data engineers and analysts to unlock the full benefit of workflow management with a framework through which they can automate workloads. Airflow can integrate a variety of different applications and systems, and assemble end-to-end processes that can be managed and monitored from a single location.
While you can get up and running with Airflow in just a few commands, the complete architecture is the following:
- Metadata Database, typically a MySQL or Postgre database that Airflow uses to keep track of task job statuses and other persistent information
- Scheduler, fire up the task instances that are ready to run
- Executor, component that actually executes the tasks
but also:
- DAG folder, read by the scheduler and executor (and any workers the executor has)
- The web server provides an overview of the overall health of various DAGs and helps visualize various components and states of every DAG. The Web Server also allows managing users, roles, and different configurations.
- Worker(s), running the jobs task instances in a distributed fashion.
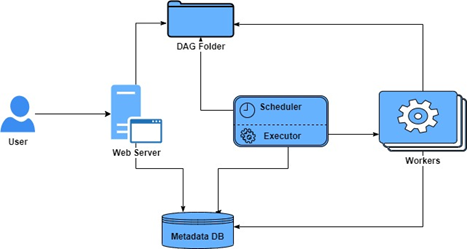
and CLI to test, run, backfill, describe and clear parts of DAGs.
Airflow’s “set it and forget it” approach means that once a DAG is set, the scheduler will automatically schedule it to run according to the specified scheduling interval.
We mentioned “DAG” a few times. So, what is DAG?
Airflow’s core abstraction is the DAG. Every workflow is defined as a collection of tasks with directional dependencies e.g. directed acyclic graph (DAG). A task is the basic unit of execution in Airflow. Each node in the graph is a task, and dependencies are edges among the nodes.
Tasks belong to three categories:
- Operators: they execute some operation
- Sensors: special subclass of operators, they check for the state of a process or a data structure
- TaskFlow: custom python function, which infers the relationships among tasks and takes care of moving inputs and outputs between them.
Workflows in real life can be as simple as two connected nodes, to very complicated, hard-to-visualize workflows.
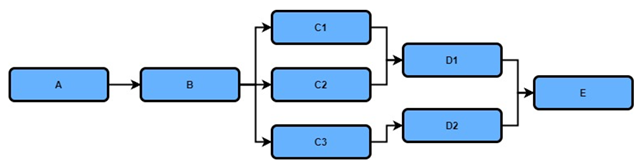
The DAG shows that each step is dependent on several other steps that should be performed first and certain steps can be performed in parallel as they are not interdependent.
Airflow comes fully loaded with ways to interact with commonly used big data systems like Hive, Presto, and Spark (allowing to trigger arbitrary scripts), making it an ideal framework to orchestrate jobs running on any of these engines. Organizations are increasingly adopting Airflow to orchestrate their ETL/ELT jobs.
Let’s see some benefits of using Airflow:
- Automate ready-to-use queries, python code, bash scripts, or jupyter notebook
- Airflow pipelines are configuration-as-code (python code that creates pipeline instances dynamically)
- Fully extendable through the development of its own hooks, operators, plugins, and executors so that it fits a custom use case
- Has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers
- Auto-retry built-in policy
- Easy access to the logs of each of the different tasks run
- Provides a monitoring and managing interface
- Airflow’s API allows the creation of workflows from external sources
- Email alerting when a task fails
Conclusion
Built by numerous data engineers, Airflow can solve a variety of data ingestion, preparation, and consumption problems, integrate data between analytical systems, CRMs, data warehouses, data lakes, and BI tools, and can also orchestrate complex ML workflows.
Although Airflow is not perfect, the community is working on a lot of critical features that are crucial to improving performance and aim to deliver the most seamless experience.