
The machines are getting smarter, and now they can dig through our documents. RAG sits at the intersection of memory and creation—grabbing relevant texts, stuffing them into an AI’s context window, and letting it respond. Simple, right?
But now they’ve bolted on “agents”—function-calling systems that execute code, call APIs, and manipulate data. The fusion happened quietly while most folks weren’t looking.
Let’s see what all the fuss is about…
What is Retrieval Augmented Generation or RAG?
Retrieval augmented generation, or RAG is a trending topic in the context of generative AI. There are constant updates and improvements that get released, sometimes even daily that change how we see and use this technology. For a “newer” topic it is very interesting that it has become one of the most popular approaches today when it comes to building chatbots.
Currently there are many advancements over the standard basic RAG architecture, some of which are advanced RAG systems that can incorporate a human in the flow of the system or even have multiple indexes for data storage. On the other hand, there are also Agentic RAG systems that improve over the AI agents, which have been one of the bigger trends in generative AI the past couple of months.
In this post we will focus on the basic RAG implementation so we can later explain how we can plug in this system inside an AI Agent to create the so-called Agentic RAG architecture.
Basic RAG
Before we jump into what the basic architecture of a RAG system looks like we should briefly mention what RAG is. Retrieval Augmented Generation (RAG) is a way of giving new knowledge to an existing LLM model without having to fine tune the model. To further explain this, we can look at each part of the system separately. These parts are the retrieval, the augmentation and the generation.
As with all ML and AI technologies we need to be careful what kind of data we are giving the model. Even though there are numerous implementations currently that you can use to create your own RAG system, which support uploading all kinds of documents for the knowledge of the model, like Microsoft Word Documents, PowerPoint Presentations, Images, PDFs and so on… it is still very important that this data is well processed and structured.
Firstly, let’s talk about the retrieval part of the system. This data, which consists of documents that we use as the new knowledge for the LLM model has to be stored somewhere. In RAG systems this data is saved in so-called vector databases (indexes) that store each document as a vector inside a single vector space. The retrieval process starts when the user sends in a prompt to the RAG system.
At this point the vector database is queried based on the user prompt and the system returns the top-k documents from the database that have the best similarity score with the user prompt. This score is calculated with mathematical operations, most commonly cosine similarity.
These top-k documents are then given to the LLM as context alongside the user prompt and a system prompt. This system prompt gives instructions on how the model should behave when processing the context and user prompt, but also what kind of result it should give back. This part of the architecture is called augmentation.
Lastly, the model, while following the instructions, generates an answer based on the user prompt and the context gathered from the vector database. This is the generation part.
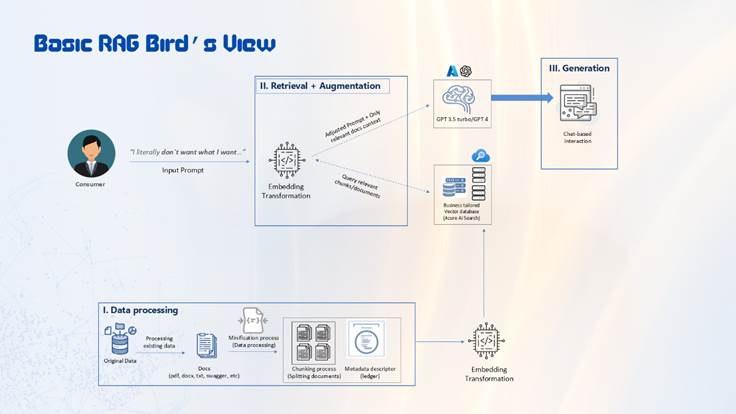
Figure 1: Basic RAG Bird’s View
Agents overview
AI Agents are not that different from your usual chatbots, that in the background have an implementation of some large language model (LLM) like GPT. The main difference being that apart from the usual question – answer interaction, these agents can also execute or call functions. These functions can be any piece of code that is executable, that can be calling an external/internal API, getting and changing information inside a database etc. as long as it can be written in code it can be executed by these agents.
Agentic RAG
Agentic RAG is a combination of an agent and a RAG architecture. The functions that we mentioned with the AI Agents can also incorporate a RAG system, and this can be done alongside other functions that we build that perform other tasks. So instead of having a chatbot that can only answer user questions we can have an agent that can execute actions, one of these actions being document retrieval/RAG. Figure 2 shows the flow of a basic Agentic RAG system.
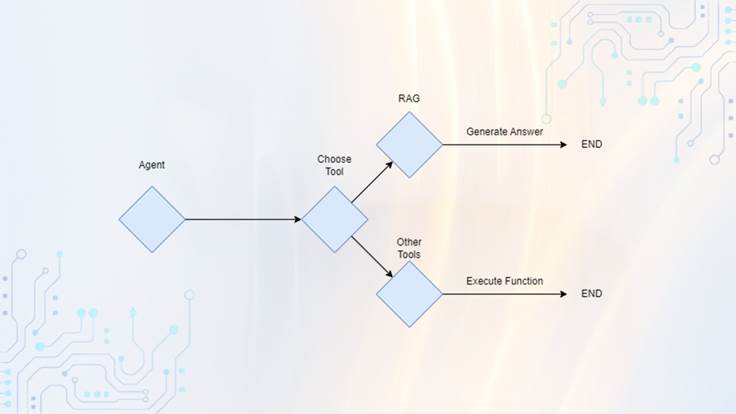
Figure 2: Basic Agentic RAG
Other use cases
Multi index and multi agent solutions with Agentic RAG
A common challenge when creating a simple RAG system is dealing with a large quantity of documents. Documents who don’t necessarily belong to the same topic or theme could have overlapping keywords, resulting in them being similar to one another in vector space. Even with some of the newest embedding models it is very difficult to correctly store lots of documents in a single vector space, and this could result in a poor retrieval outcome.
Another challenge is instructing an LLM, by using the system prompt, that it should be able to handle/process a large number of documents from very different topics, or documents that have multiple different structures.
Giving lots of instructions to an LLM inside the system prompt could result in poor behavior, since it is difficult for models to follow a large number of different instructions simultaneously. One way these challenges can be solved is with a multi-index and/or multi-agent solution.
Multi-index means that instead of having a single vector index store for many documents, we would split/cluster these documents into different indexes based on some kind of similarity that we choose.
After this, instead of retrieving from a single index we would be able to first decide the most relevant index, to the user prompt, and then retrieve from that index. In an agentic system this can be done by using an agent to decide which index is most relevant to the user prompt. We can accomplish this by giving detailed descriptions to each index about the data that they store.
Multi-agent means that we would have multiple agents or LLMs that would perform different tasks at different points in the system. In the case of building a multi-index RAG we can use a different agent for each index, solving the problem of having a very complex and long system prompt that should cover all indexes. This would improve the performance of the retrieval for each index.
An example of such architecture can be seen in Figure 3.
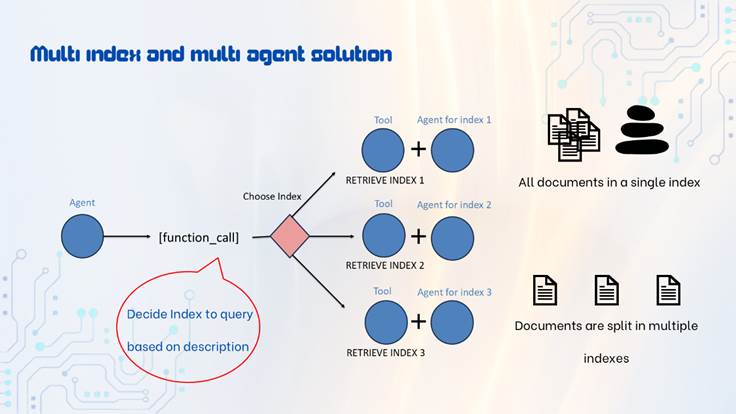
Figure 3: Multi index and multi agent solution
Rewriting prompts with Agentic RAG
Another feature that can be implemented inside an Agentic RAG architecture is the option to rewrite the user prompts if the LLM does not find a suitable answer to the user prompt. We can ask an LLM to formulate a new question/prompt that is based on the previous prompt, while trying to keep the original semantic intent / meaning of the first prompt.
This is a good addition to just the basic RAG implementation and could possibly be useful to avoid any typing errors, or poorly written prompts by the user. After the question is rewritten, it is sent to the agent to try and generate an answer from the new prompt.
Industries that could benefit from Agentic RAG
An Agentic Retrieval-Augmented Generation (RAG) system can benefit several industries:
- Healthcare: Automates research for patient diagnosis and treatment recommendations, helping medical professionals stay updated with the latest findings.
- Legal: Enhances legal research by quickly retrieving relevant case law, making it easier for lawyers to build cases.
- Finance: Supports investment analysis by retrieving up-to-date financial data and trends, assisting in informed decision-making.
- Customer Service: Improves response accuracy and speed by accessing vast sources of information to answer customer inquiries effectively.
- E-commerce: Personalizes product recommendations by retrieving related products, boosting user engagement and sales.
Each of these industries relies heavily on fast, accurate information retrieval, making Agentic RAG an asset in improving efficiency and decision-making.
Furthermore, all of these cases could be enhanced with custom functions that an agent can execute.
Final Thoughts
Agentic RAG marks a quiet revolution in how we interact with information. Beyond just finding relevant documents, these systems collapse the distance between knowledge and action. They don’t simply answer questions—they execute tasks, call functions, and transform how professionals work across industries. What makes this approach valuable isn’t technical elegance but practical impact.
By bridging the gap between retrieval and function, Agentic RAG eliminates the cognitive overhead of context-switching. The result is surprisingly human—like having an assistant who not only finds the exact information you need but takes the logical next steps without being asked.