
Businesses are sitting on a treasure trove of data, yet unlocking its full potential can be a challenge and requires the right approach. That’s where dbt (Data Build Tool) comes in—an indispensable solution for transforming and managing complex datasets within Data Lakehouse Architectures, offering a powerful combination of scalability, flexibility, and governance that streamline both data lakes and data warehouses.
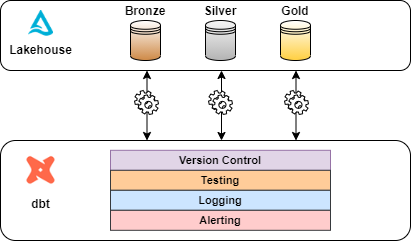
Here’s how dbt is reshaping the landscape for building scalable, robust data lakehouses:
1. SQL-Based Transformation
dbt leverages SQL, a widely adopted language, to streamline data transformations, significantly lowering the technical barriers for building and maintaining data pipelines. By doing so, it enables our teams to efficiently convert raw data from a data lake into structured, analytics-ready formats for the lakehouse. This provides a familiar interface for analytics engineers, data scientists, and analysts alike. Once the data engineering team integrates raw data into platforms like Databricks, Snowflake, Redshift, Synapse, or BigQuery, dbt becomes the go-to tool for building reliable, scalable, and testable data models, enhancing collaboration and agility all data teams.
2. Modularity and Scalability
dbt promotes a modular approach to data modeling, breaking complex transformations into smaller, manageable SQL files. This ensures scalability as data grows without compromising performance. By enabling the creation of reusable data models (Macros and Packages), dbt fosters consistency across projects and teams, reducing duplication of effort and improving collaboration across the organization. It’s an ideal fit for handling large, diverse datasets typical of data lakes.
3. Data Governance
In a data lakehouse environment, dbt’s semantic layer ensures consistent data transformations, centralizing business logic to reduce errors and inconsistencies across teams. It enhances data governance by maintaining data accuracy and alignment with company goals. dbt’s Directed Acyclic Graph (DAG) provides a visual map of data models and their relationships, offering insights into data flows and potential performance bottlenecks. The tool also excels in automatic documentation generation, tracing data lineage from raw inputs to outputs, fostering transparency and trust. dbt Cloud ensures documentation is always up-to-date following each successful job run.
4. Version Control and Testing
dbt integrates seamlessly with Git for version control, allowing teams to track every change to their models. This is especially beneficial in a data lakehouse architecture, where multiple teams collaborate on various data models, ensuring transparency and easy auditing or reverting of changes. Additionally, as data pipelines grow in complexity, monitoring and optimizing their performance becomes crucial. dbt supports data testing at every stage of the transformation process, ensuring high data quality. Users can choose between generic, out-of-the-box tests for broad application across models, or customized tests tailored to specific data models, enabling reliable and efficient data management.
5. Automation and CI/CD Pipelines
dbt can be integrated into CI/CD pipelines, enabling automated deployments and continuous monitoring of data transformations. This is critical in data lakehouse environments where data pipelines need to be continuously updated as new data comes into the lake, ensuring real-time insights and efficient operations.
6. Cost Efficiency
With dbt, you can optimize data transformations without extensive engineering overhead, reducing operational costs. Its lightweight structure and ease of use make it a cost-effective solution for data lakehouse environments, which often deal with large volumes of data but need streamlined and cost-efficient processing.
If you’re looking to optimize your data architecture and unlock the full potential of your data, feel free to connect! Let’s discuss how tools like dbt can transform the way we manage and utilize data.