
Unit tests made sense when software did exactly what you told it to. You write a function, assert an output, get a green check. Done.
That model breaks the moment you introduce an LLM. And if your team is still relying on static assertions to validate AI behavior in production, you’re not testing your system. You’re testing your assumptions about it.

The Real Cost of Getting This Wrong
Here’s a number worth sitting with: in 2024, global losses tied to AI hallucinations reached $67.4 billion. Not a projection. An estimate of actual, documented economic damage.

What makes it worse is the attempted fix. Organizations that try to catch AI errors through manual verification end up 22% less productive than before they introduced AI at all. You hired AI to move faster, and now your team spends half its time fact-checking what it produces. That’s not a workflow problem. It’s a testing problem.
The root cause has a name: agentic drift. Unlike static code, AI agents don’t stay put. As underlying models update or training data shifts, an agent can quietly learn shortcuts, skipping reasoning steps, pulling context it shouldn’t trust, generating outputs that look right but aren’t grounded in anything real. You won’t see it coming unless you built an evaluation system that catches it.

What AI Evaluation Actually Is
Traditional testing asks: does the output match what I expected?
AI evaluation asks: does the output achieve what I actually needed?
In engineering teams, this practice is called running ‘evals’ — shorthand for evaluation tests that measure whether your AI is doing what you actually need it to do.
Consider an email outreach system built on a RAG pipeline that ingests lead data, runs a CRM check, enriches the lead profile, and generates a personalized draft using chain-of-thought reasoning. A traditional test might fail the output because the model wrote “5 leads” instead of “five leads.” An eval framework recognizes those are the same thing and asks better questions: Is this email grounded in what the CRM actually returned? Did the agent check the right data in the right order? Would a sales rep trust this draft enough to send it?
That shift, from syntax validation to intent validation, is the whole game.

Three Layers You Need to Test
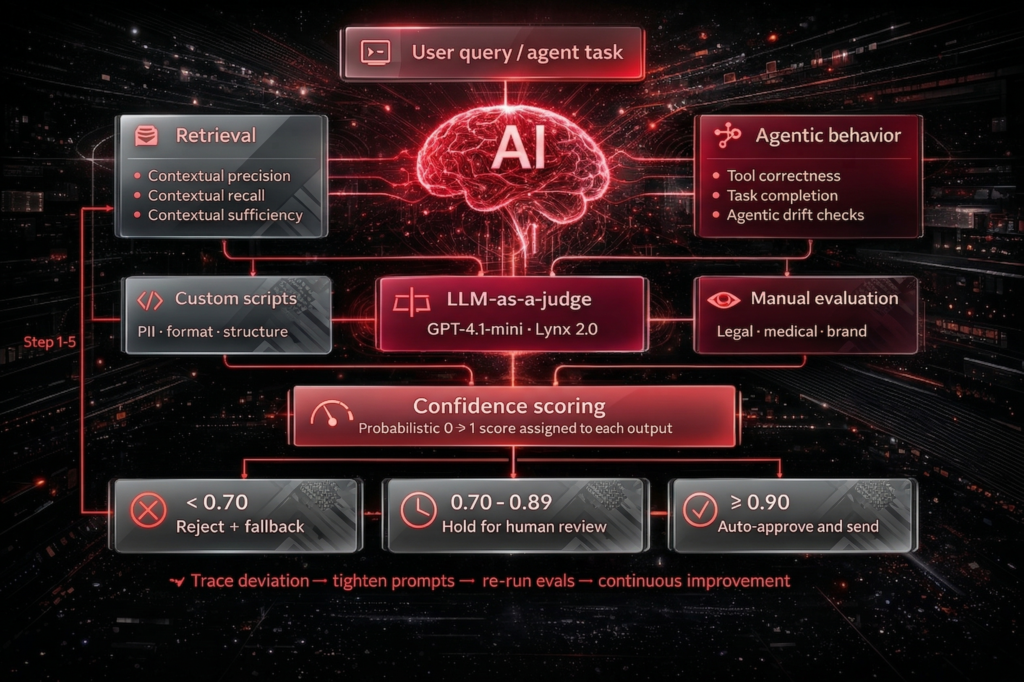
Retrieval: Is Your Agent Pulling the Right Information?
Before the LLM generates anything, it needs context. Bad context in means bad output out, no matter how good your model is.
Three metrics matter here:
Contextual Precision checks whether the retrieved context is mostly relevant, not padded with noise that confuses the generation step.
Contextual Recall checks whether the context actually includes everything needed. A personalized email that’s missing the prospect’s previous interaction history isn’t personalized.
Contextual Sufficiency (a metric from Patronus AI) goes a step further. It asks whether the fetched context contains enough to answer the query correctly without the model having to guess. This one catches the subtle failure where retrieval looks complete but leaves the LLM to fill gaps with invented details.
Generation: Is Your LLM Staying Grounded?
This is where most teams focus, and rightly so, but the metrics matter.
Faithfulness checks whether the output is grounded in the retrieved context or whether the model started improvising. Did it invent a discount code that wasn’t in the product sheet? Did it claim a feature the company doesn’t offer?
Answer Correctness measures how well the output aligns with a known “gold standard,” meaning what the ideal response would look like.
Hallucination detection covers two distinct failure types: factuality errors (fabricated content) and faithfulness errors (distorting what a real source actually said). These need to be tracked separately because they have different causes and different fixes.
Agentic Behavior: Is Your Agent Doing Tasks in the Right Order?
Multi-step agents fail in ways that neither retrieval nor generation metrics catch. The agent might use the right tools and produce reasonable output, but in the wrong sequence, at the wrong time, for the wrong reason.
Tool Correctness validates that the agent triggers the expected sequence. In the email system example, that means checking the CRM before enriching the lead, not after.
Task Completion is exactly what it sounds like: did the agent finish the job? Not just produce output. Did it produce a complete, ready-to-use draft?
This layer is where agentic drift shows up most clearly. The agent looks fine on individual steps but fails as a system.
How to Build Your Testing Framework (Without a Six-Month Research Project)
You don’t need a six-month research project to get started. Here’s a practical sequence:
1. Start with raw traces. Review actual production runs. If Contextual Recall is low, your chunking strategy probably isn’t maintaining semantic meaning across chunks. Recursive chunking and semantic chunking behave differently, so test both against your data.
2. Define binary criteria first. Pass/Fail metrics are easier to track and act on than fuzzy scores. “Does the email include the CRM data we retrieved?” has a clear yes or no. Start there before you optimize for tone.
3. Build a gold standard dataset. Upload reference examples in XLS format, or generate synthetic edge cases to stress-test how your system behaves at the limits. Both matter.
4. Connect to an eval framework. Tools like Langfuse or First Line’s Eval Framework handle metric calculation automatically, which means you get consistent results without depending on whoever happens to be reviewing traces that week.
5. Use deviations to improve, not just to report. When an agent learns a shortcut, like skipping a reasoning step, the trace shows you exactly where it happened. Use that to tighten your system prompts with span-level verification. Then rerun. This is the loop that actually improves the system over time.
The Tooling Stack Worth Knowing
No single approach covers everything. The teams that get this right use a layered setup:
Custom scripts handle the rigid stuff: PII detection, format validation, checking whether outputs meet specific structural requirements. Fast, cheap, and good at what they do.
LLM-as-a-Judge is where contextual evaluation happens. Specialized models like GPT-4.1-mini, Lynx 2.0, or Glider assess whether an output is relevant and faithful far more reliably than pattern matching. Generic models like GPT-OSS are less suited for this, and the specialized judges are worth the extra cost.
Manual evaluation doesn’t scale, but it’s still the most accurate method for high-stakes content, including anything touching legal, medical, or regulated language. For brand voice validation, there’s still no substitute for a human read.

For observability specifically, Langfuse is worth the attention. It traces the full journey from input through retrieval to output, which means you can pinpoint exactly where a hallucination entered the pipeline rather than just knowing it exists. Dataset-based evaluation lets you compare current runs against historical “gold runs” to catch regressions before they hit users.
For teams that want to go deeper, Cross-Layer Attention Probing (CLAP) flags hallucinations in real time by analyzing internal model activations. MetaQA tests for inconsistencies by mutating prompts and checking whether the outputs stay stable. These are advanced tools, but worth knowing about when your system’s failure modes start getting more subtle.
Confidence Scoring: The Bridge Between Evaluation and Action
Evaluations only create value if they connect to decisions. Confidence scoring does that.
Assign a probabilistic score (0 to 1) to each output, then define tiers that determine what happens next:
- Score 0.90 or above: Auto-approve and send.
- Score 0.70 to 0.89: Flag for human review before it goes anywhere.
- Score below 0.70: Reject and trigger a fallback: re-retrieval, a different prompt, or a human handoff.
These thresholds aren’t arbitrary. They can be calibrated to compliance requirements like SOC 2 or IFRS 9, which means your evaluation framework becomes part of your governance posture, not just your engineering practice.
What You Actually Walk Away With
This isn’t about building a more sophisticated QA process. It’s about whether your organization can trust its own AI systems enough to act on what they produce.
Teams that put this framework in place report a 75% reduction in manual documentation overhead, the review cycles and fact-checking that quietly eat engineering hours. Certification costs drop by around 50% compared to doing it manually. And model updates stop making gut-feel decisions while hoping nothing breaks in production.
The $67.4 billion in hallucination losses from 2024 didn’t happen because the technology failed. It happened because nobody caught the drift early enough. Your exposure to that same problem comes down to one question: do you have the infrastructure to catch it before it becomes expensive?