

Introduction
Data is king in the dynamic business world, and NoSQL databases, like Azure Cosmos DB from Microsoft, have become essential tools for managing this valuable resource. However, the key to unlocking the total business value of Azure Cosmos DB lies in proper data modeling. In this blog post, we will explore why data modeling is crucial in Cosmos DB, how to achieve it and how it translates into tangible benefits for businesses.
Data modeling involves structuring and organizing data within a database to meet specific application requirements. Improper data modeling can lead to several challenges and problems that may impact the system’s performance, scalability, and maintainability. Some common issues that arise when data is not correctly modeled are:
- Inefficient Query Performance – Inadequate data modeling may result in inefficient queries, leading to slow performance. It can impact the responsiveness of applications significantly as data volumes increase.
- Limited Scalability – Ineffective partitioning strategies can limit the system’s ability to scale horizontally as datasets grow and user load increases.
- Difficulty in Data Retrieval – Improperly modeled data may lead to challenges in retrieving the desired information. Developers may face problems constructing queries or aggregating data, affecting application functionality.
- Maintenance and Data Consistency Challenges – Poorly modeled data may contribute to inconsistencies and discrepancies in the database. Only accurate or complete information can lead to correct results and maintain the system’s reliability.
Techniques for modeling Azure Cosmos DB for NoSQL API
Modeling techniques that should be applied when using Cosmos DB databases differ from traditional relational databases due to NoSQL data stores’ flexible and schema-less nature.
The following are techniques used to model data in a manner that will result in a fully managed, high-performance database.
Identifying access patterns for the application
When designing a data model for a NoSQL database, the goal is to minimize data operations by understanding the relationships and access patterns. It involves understanding how the application interacts with the data, determining how properties of entities are grouped, and organizing their storage within documents in containers within Azure Cosmos DB for NoSQL databases.
For example, in a news website, some of the features could be:
- Creating/Editing an author
- Retrieving an author
- Creating/Editing an article
- Retrieving an article
- Creating comment
- Listing comments for articles
- Liking an article
Embedding Data
This method involves nesting related information in a denormalized structure, facilitating data retrieval, and reducing the need for complex joins. This approach has advantages in scenarios where frequent access patterns demand quick and responsive queries, retrieving the data in minimal requests.
In the example below, awards and social media are embedded as items in a list rather than kept in separate containers, and multiple calls were made to get all information for the author profile.
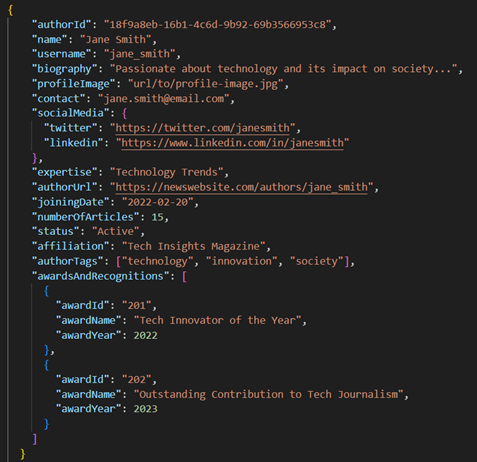
When should this modeling approach be used?
- Read or updated together (1:1 relationship);
- Data is bounded (1:few relationship);
- Data that only change occasionally.
Referencing Data in the Database
When modeling data in Azure Cosmos DB and considering referencing, choose this strategy for scenarios involving one-to-many relationships, frequent updates to related data, and variable access patterns. Referencing is beneficial for minimizing redundancy, improving query performance, and maintaining a more normalized data structure, especially when there’s a logical separation of concerns among entities.

When should it be used?
- Read or updated independently;
- Related data changes frequently;
- 1:Many relationship;
- Data is unbounded;
- Many: Many relationships.
Choosing the right partition key and ensuring equal data distribution to avoid hot partitions
Cosmos DB uses partitioning to scale individually distributed collections. Choosing the right partition key in CosmosDB for NoSQL API is critical for broadcasting data and workload evenly across all partitions.
When choosing a partitioning key, the following should be considered:
- Cardinality – Choose a partition key with a high number of distinct values. Higher cardinality allows for better distribution of data and requests across logical partitions.
- Access Pattern – The partition key should align with the access patterns of your application. If most of your operations are reads and writes of a single item, choose a partition key that spreads these operations across multiple partitions.
- Query and Transaction Volume – The partition key should be a property commonly used in queries. This way, most queries can be directed at a single logical partition, minimizing cross-partition queries that consume more request units (RUs). Also, all items that are part of the same transaction need to have the same partition key.
- Storage Capacity – Each logical partition has a storage limit. Therefore, the partition key should distribute data evenly to avoid hitting the storage limit on a single partition.
- Write and Read Throughput – The partition key should distribute writes and reads evenly across all partitions to avoid creating “hot” partitions that receive more traffic than others.
- Growth Over Time – Consider how your data might grow and evolve. The partition key should be chosen so that it continues to ensure even data distribution and high performance even as the volume of data increases.
Conclusion
In summary, proper data modeling in Azure Cosmos DB is fundamental to overcoming query performance, scalability, data retrieval, and maintenance challenges. It ensures that the database is structured to align with the application’s requirements, optimizing its overall performance and adaptability to changing business needs.