
In our previous article Why Your Business Should Adopt Microservices we discussed microservices, what they are, and their necessity. This article is focused on building a small project using Spring Cloud and Eureka Service Discovery.
The Cloud
The cloud is often hyped as the game changer – the magical solution to everything. Cloud computing or the cloud is really changing the way we build software. Moving from centralized monoliths to distributed cloud-native applications. Not only the software but also the hardware is changing. We’re moving from the finite and limited resource to the infinite and on-demand resource. But, new challenges also come with the cloud. We have to think differently. Things are not as static as we are used to. We can’t just design and architect and use the same principles or techniques that we’re used to. The cloud is an elastic and ephemeral thing. Things can grow and shrink, appear, and disappear at any given time. So, we have to consider the cloud as ever-changing and constantly evolving, though we are used to something that is more static. In order to fully utilize the cloud, it requires change. And that’s where Spring Cloud comes into play. Spring cloud helps us build cloud-native applications. It means our application fully utilizes all of the cloud computing paradigms. Spring Cloud itself is not actually a framework. Loosely speaking Spring Cloud is used to describe a number of projects that all fall under the same umbrella.
Spring Cloud
Spring Cloud was released in 2015, and considering that it’s a fairly new offering, Spring Cloud helps us to build some of those common distributed system patterns making it very approachable, easy to consume, so that people could use these patterns without having to be experts on the setup. Spring Cloud is fully open-source software. We constantly see new releases of Spring Boot, and Spring Cloud and the like and we can contribute our own patches and contributions to the open-source project. This is optimized for spring apps, but in many cases, we can use other technology with it, as these expose HTTP endpoints and similar, so it’s definitely made for Spring, and Spring Boot applications, but at the same time it’s not exclusionary. We can run this anywhere, whether you want to run this in Cloud Foundry, Kubernetes, bare metal data centers, it does not matter.
The idea is you could run this in a platform, you could run this in containers, simply Spring applications. You end up generating jars out of this, and it’s easy to deploy it wherever you would like. What’s really exciting is that it includes a lot of NetflixOSS technology. Netflix has some serious experience building scalable applications in the cloud. And in fact, we could probably even argue they have some of the largest scalability problems we could imagine. They built some projects internally to handle these problems and eventually released them as open-source projects. The Spring Cloud project took the Netflix open-source projects and added some Spring and Spring Boot features. What was born out of that was the Spring Cloud Netflix project. Similar to the Spring Cloud project, the Spring Cloud Netflix project is not a project itself. Rather it’s a collection of projects. And for service discovery, we are interested in two of those projects. The Spring Cloud Netflix Eureka Server and The Spring Cloud Netflix Eureka Client.
Much of these were built out of necessity, as what they were doing wasn’t really solved by the platform they were running on at the time, Amazon Web Services. It didn’t have all the things they needed to run at Netflix scale, so they built a number of projects that then rolled into Spring through a collaboration between Spring and Netflix. So many of the Netflix core technologies have made their way into Spring that makes it easy for you to use it. So instead of you reinventing the wheel, we have access to some of the latest and greatest technology.
Here are all of the Spring Cloud Netflix features:
- Service Discovery with Eureka
- Circuit Breaker with Hystrix
- Client-Side Load Balancing with Ribbon
- Server-side and client-side support for externalized configuration
Service Discovery
We’re moving away from building these single large applications to breaking them up into smaller and smaller pieces called services. And each of those pieces can then be deployed and scaled on their own, and together, as a whole, they form the overall application. And here lies the problem. How does one service know where another service is at? Its host and its port, so that it can call it and use it? For starters, we could simply configure all of our services to know the location and the port of other services that it calls. And, depending on our needs this can go a long way. But after a while, we’ll learn that there are some problems with this approach. For example, what if we had two instances of a particular service? And if we used configuration every time we added or removed a new instance of any particular service we’d have to update that configuration. And well in our example we have only two instances. Imagine if you had hundreds of instances. The configuration management alone would be unsustainable. Our simple configuration starts to break down even further as we move to a cloud environment. In a cloud environment, you have instances of services that can come and go in response to demand for instance. So, for example, our service starts with two instances and consider maybe we have this huge influx of traffic to our website, and a process kicks off and starts two more instances to handle all of that demand. If we’re using simple configuration all of the callers of Service B such as Service A, would not even know about the two new instances that were added in response to that demand.
As far as they’re concerned, their configuration says that there are only two instances that they know about. Another thing to consider is that application services will eventually fail, regardless of the situation, whether it’s a software problem or a hardware problem. If we’re using simple configuration our services are going to continue to try to send traffic to those failed instances. For example, here we have Service B being called by Service A, and it has 2 instances. And if one of those instances fails, Service A is not gonna know the better and it’s going to continue to send traffic to that failed instance. We need something that is more dynamic. The simple approach is just far too static for our needs in the cloud. That’s where service discovery comes into play. Service discovery typically provides the following types of functionality:
– A way for a service to register itself
– A way for a service to deregister itself
– A way for a client to find other services
– A way to check the health of a service and remove unhealthy instances
Key Components in Service Discovery
It’s helpful to understand the key components involved in service discovery and how they interact with each other. At a minimum, there are 3 components involved in service discovery. There’s the Discovery Server, the Application Service, and the Application Client. The first thing that happens is the application service starts up, and when it starts up it calls up to the Discovery Server and it registers itself. It tells the Discovery Server its location, port, and a service identifier that others can use to find it. Then at some point later a client needs to call that application service, but it doesn’t know the location and the port of the service so it needs to ask the Discovery Server. It sends out a request to the Discovery Server and sends along with the service identifier, and the Discovery Server knows based on that service identifier which service you’re asking for so it responds back with the location and the port of that service. From there, things proceed as normal and the client can request the service and its location and the service can respond back with some data.
The Discovery Server
The Discovery Server is an actively managed registry of service locations. It is responsible for others to find services and for services to register and deregister themselves. Typically you can run one or more instances of the Discovery Server as it’s the key component to locate the other services. And if you can’t locate the other services then you can’t call the other services. It is an important piece of the architecture.
Creating a Discovery Server is really easy with Spring and Spring Cloud. In fact, it’s almost ridiculously easy. In the pom.xml of our maven project we add:

In our application.properties we also define:

Then in our main application class, we define just one annotation @EnableEurekaServer and that’s it.

Once we start this instance up we have a running instance of a Discovery Server.
The Payment Service
Next on our list is the Payment Service. The Payment Service is a microservice application that contains an HTTP client that will be used to call other microservices, in our case the Product Service.
The Payment Service is a user of the discovery client. It’s going to use that client to call out to the Discovery Server and register and deregister itself. Just like we did for the Discovery Server, in the pom.xml we define:
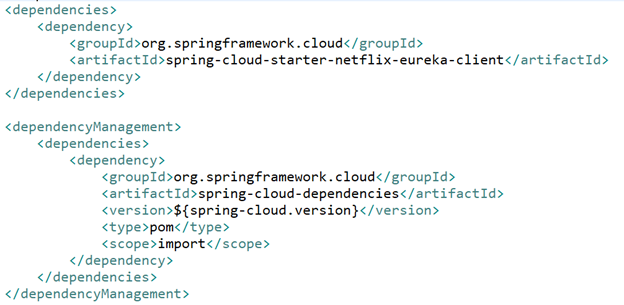
In our application.properties we define:

In the main application class we just add one annotation @EnableDiscoveryClient:
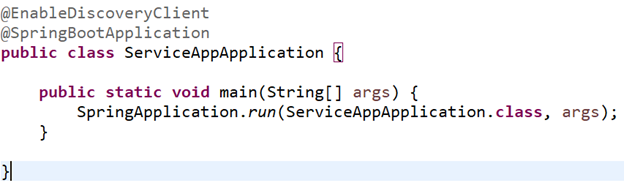
and what this does is it makes our Payment Service register itself with the Discovery Server and then other services can find it.
The Product Service
Up next is Product Microservice. In our case, the Payment Service will be the piece that would call out to another Product Service to implement/call some piece of functionality in its service. In this case, the Payment Service is the issuer of requests and it depends on the Product Services. And similar to the Payment Service, the Product Service is also a user of the Discovery Server. The steps involved to create the Product Service are quite similar to the steps involved to set up a service. We add in our pom.xml file:
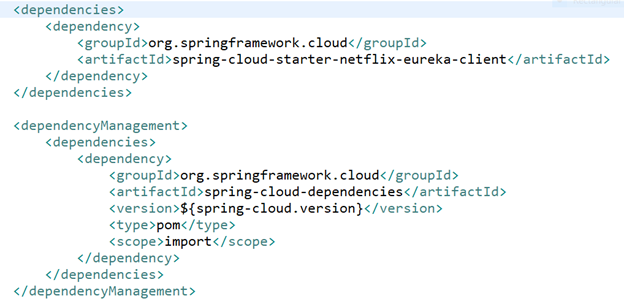
The difference between an application client and an application service comes in the configuration. We have the same 2 properties we use in the application service:

And since we’re a client we are not interested in registering with the Discovery Server because we do not need anybody to discover us. We’re just interested in discovering others. So we set the third value to false. Just like we did with the application service we add the @EnableDiscoveryClient annotation to the main class in our application client.

And then to actually discover services we have two different options. We can inject the EurekaClient or the DiscoveryClient. The EurekaClient has a method getNextServerFromEureka(), this will pick the next instance in a round-robin fashion, from the Discovery Server. Once we get a reference to InstanceInfo we can call getHomePageUrl(), and that would give us the base URL that we can use with our RestTemplate to call the service.
The next option is to use the Spring DicoveryClient and it has a method getAllInstances() which returns all instances for a given service id. Once we have a list of instances you can get one of those instances, get the URI and turn it into a string so that would be our base URL for our RestTemplate.
In our case we used EurekaClient, and a basic example of the PaymentController would look like the following:

Lastly our ProductController:

Starting The Components
After finishing the configurations for the three components, we can start the projects.
First, we need to start the Discovery Server, then the Payment Service and we also need to start two instances of the Product Service. We can either start the applications via command line or by making Run Configurations in our IDE in our case we used Eclipse.
In case you want to start the application from a command line the order goes like this:
- package the projects so you get the jar files in the /target folder
- run the Discovery Server: java -jar discovery-server.jar
- run the Payment Service: java -jar payment-service.jar –service.instance.name=payment-service-1
- run two instance of the Product Service: java -jar product-service.jar –server.port=8081 –service.instance.name=product-service-1 and again java -jar service.jar –server.port=8082 –service.instance.name=product-service-service-2
Once our applications are started we should see in the console output of our Discovery Server similar output depending on the configuration:
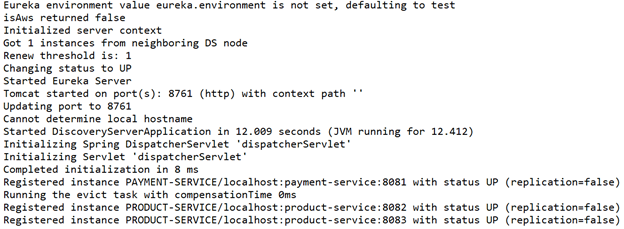
We can now hit the client endpoint “http://localhost:8083/” and should see our services:
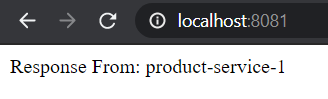
If we hit it multiple times we should also see our second service:
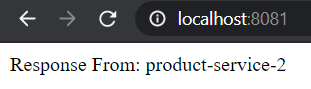
The project can be found on this github repository: https://github.com/popovski/interworks-blog-service-discovery
Conclusion
We clearly touched only the surface of Spring Cloud. Since Spring Cloud is considerably vast and we could not possibly clear the core concepts in this article it’s a good starting point for upcoming articles where we’re going to take a look at Spring Cloud Config. For more information, you can also refer to the official documentation of Spring Cloud https://spring.io/projects/spring-cloud.