

Have you ever wondered how online stores handle massive orders without delays or glitches? The answer lies in clever technology solutions like MuleSoft. This article explores how MuleSoft empowers businesses to streamline their order creation process, ensuring smooth operations and happy customers.
E-commerce is growing every day, and with that growth, businesses are receiving an increasing number of Sales Orders. Navigating these essential processes can sometimes be challenging with such a high volume of orders. This volume is a challenge for many organizations, leading to delays and failed orders. Businesses need the ability to process orders quickly and efficiently.
MuleSoft offers robust solutions to streamline this process, ensuring seamless order processing while optimizing performance and scalability by scaling out the Mulesoft application to run on multiple instances/workers/replicas if demand is higher than expected and to retain availability from a functional standing point.
Increased replicas in Mulesoft have shortcomings. Each replica runs on separate memory space, data from one replica is not reflected to the other, and both replicas are not aware of each other, which can cause duplication and unpredictable behavior in terms of order processing, procurements, drop shipping, supply chain management, etc.
By leveraging advanced techniques such as Time-Based Aggregation, Double Caching, and Clustering, Mulesoft can streamline and promote seamless synchronization between workers/replicas in the same application where, once the order or specific business workflow is processed, can be registered in internal/shared memory and considered in the subsequent jobs/process instances.
The Challenge of High Order Volume
Imagine this: You’re running a thriving online store, and orders are pouring in – fantastic! But with significant volume comes a challenge: efficiently processing all those orders without delays or errors. Traditional methods can struggle under such pressure, leading to frustrated customers and lost sales.
MuleSoft to the Rescue
MuleSoft offers a robust set of tools to tackle this challenge. By leveraging techniques like Time-Based aggregation, Double Caching and CloudHub Clustering, MuleSoft can significantly improve the efficiency and performance of your order processing system.
Implementation
The E-commerce External API operates in a manner where multiple orders can be sent at once, with each batch requiring a unique identifier. To initiate this process, we send a request to create a Job ID, the unique identifier. Then, we aggregate multiple orders into a batch, associating the Job ID with the batch before sending a request to the API. Multiple HTTP POST requests for uploading the aggregated orders are then made using the same Job ID. Upon completion, the Job ID must be committed, rendering it unusable for uploading additional aggregated messages. Once the Job ID is committed, the orders are created in the external system. We will outline a detailed walkthrough of how we can efficiently process high volumes of orders by combining Time-Based Aggregation, Double Caching, and CloudHub Clustering in MuleSoft.
Our solution used API Led Connectivity, an architectural style that connects data to applications through reusable and purposeful API. API Led Connectivity consists of three layers: Experience, Process, and System. We have three applications for each layer:
- iw-exp-api, which is an Experience API
- iw-prc-api, which is a Process API
- iw-sys-api, which is a System API
Experience API
In the Experience API “iw-exp-api” we have the “create-order” flow, which is a starting point in the integration workflow:
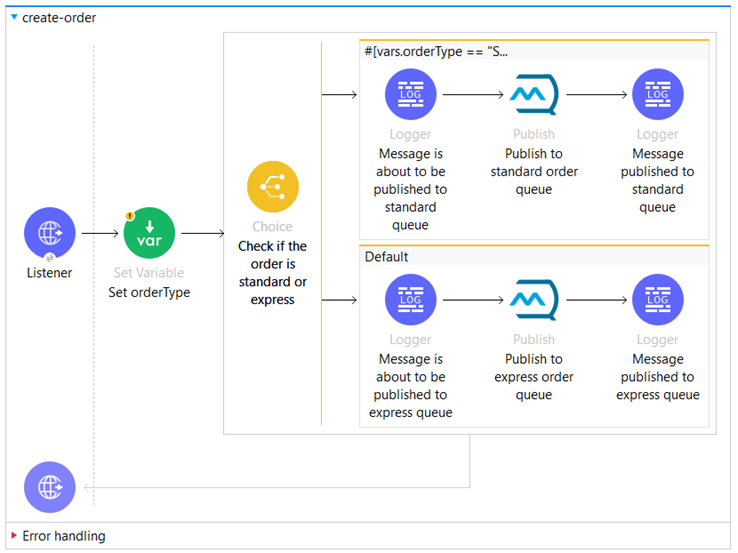
We have an HTTP Listener Component that receives requests to create orders.
Upon receiving an incoming sales order, we extract the type of the order and save it to a variable named “orderType”.

We have two types of orders in the Order Management System:
- Standard Orders:
- These are regular orders placed by customers for products or services.
- Standard orders follow the typical order processing workflow without any special requirements or exceptions.
- Express Orders:
- Express orders are prioritized for faster processing and delivery.
- Customers may choose express shipping options for urgent orders or pay extra for expedited.
We’ve configured a Choice component to determine the type of the Sales Order:
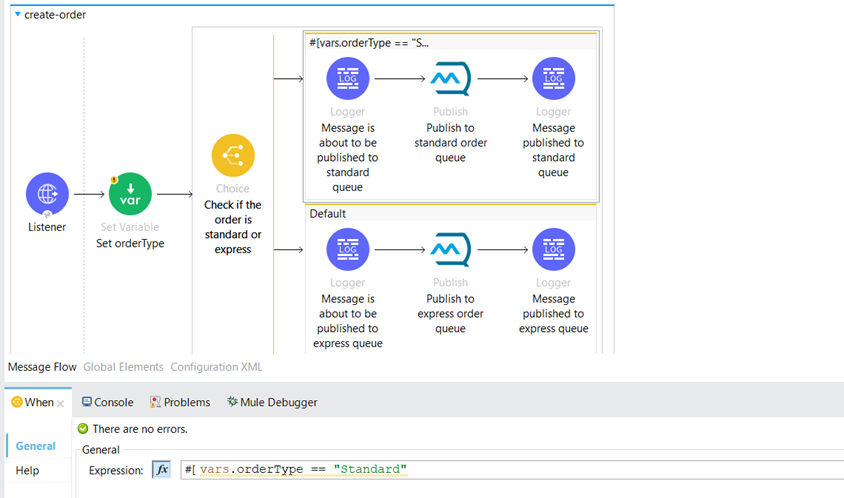
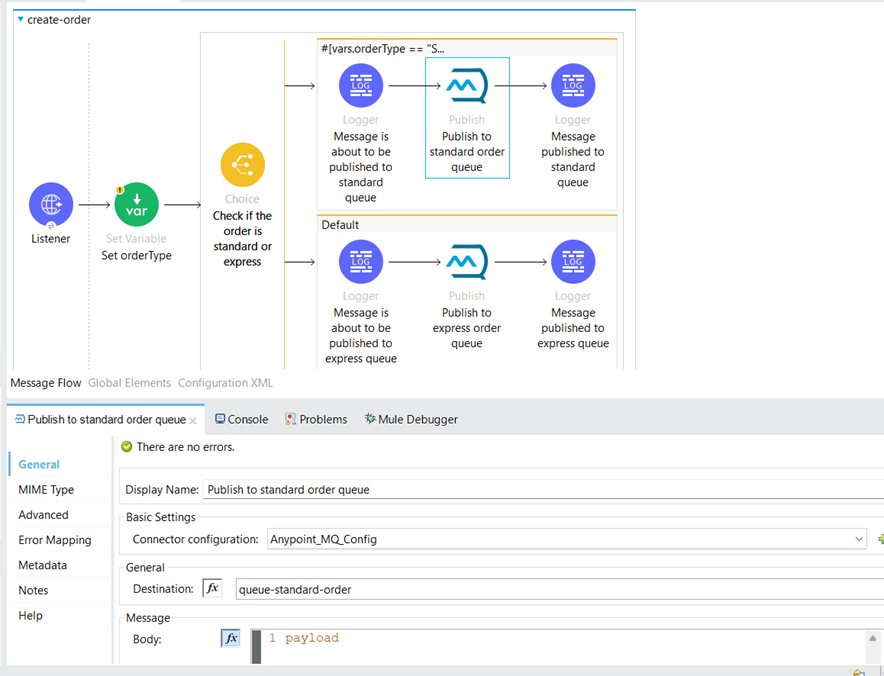
If the Sales Order is a Standard Order, the order payload is published to the “queue-standard-order” queue; if the order is of type “Express,” it is published to the “queue-express-order” queue.
Process API
In the Process layer application “iw-prc-api” we have three xml configuration files:
- global.xml
- inbound.xml
- outbound.xml
We keep the configurations in global.xml.
In inbound.xml we have two inbound flows, one for Standard orders and one for Express orders. Both flows have Anypoint MQ Subscribers, responsible for receiving orders published from the Experience API.
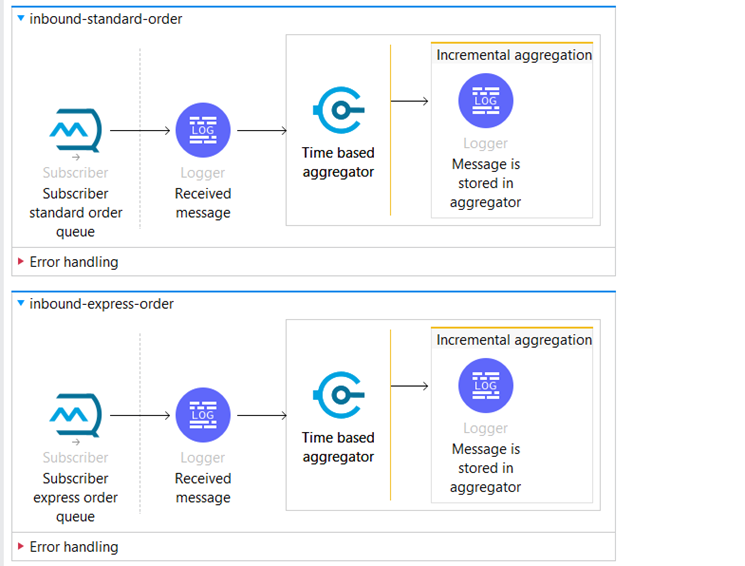
We are going to look at the flow for standard orders.
We’ve set the queue to “queue-standard-order,” which matches the one used for publishing orders in the Experience API.
We are using “Prefetch” as a subscriber type. In this mode, the Subscriber source attempts to keep a local buffer of messages full, making them available to be dispatched to the Mule flow as soon as the app can accept them.
We used Auto acknowledgment with 30 seconds as a timeout. By default, the Subscriber source uses the AUTO acknowledgment mode. With this mode, the messages that the Subscriber source retrieves are acknowledged automatically after message flow processing succeeds. This means that the Subscriber source receives a message, dispatches it to the flow, and waits to see how the message processing finishes. It executes an ACK only when the processing finishes without exceptions.
If the execution of the processing flow finishes with a propagated exception, the message is automatically not acknowledged and is returned to the queue for redelivery.
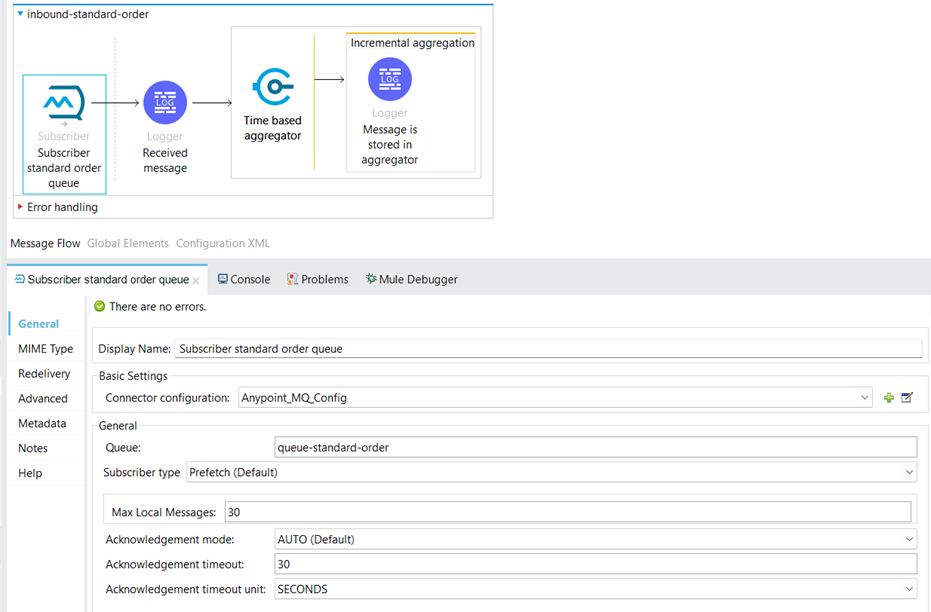
We need to aggregate the messages to send them as a batch to the external client API. We need to use some of MuleSoft aggregators:
· The Size-based aggregator scope enables you to aggregate elements until a predefined number of elements completes the aggregation.
· The Time-Based Aggregator scope enables you to aggregate elements until a specified time limit is reached.
· The Group-based aggregator scope enables you to aggregate elements into groups by group ID.
We used a Time-Based Aggregator. The Time-Based Aggregator can be configured to collect incoming orders over a specified time interval. This allows orders received within the same time window to be grouped into a single batch for processing. By batching orders in this manner, the system can reduce the number of individual requests sent to the API, improving efficiency and reducing overhead.
We set the Time-Based Aggregator to be named “aggregator-standard-order” and set the period to 45 seconds to aggregate the messages.
When the aggregation reaches 45 seconds, an Aggregator listener source receives the aggregated data.
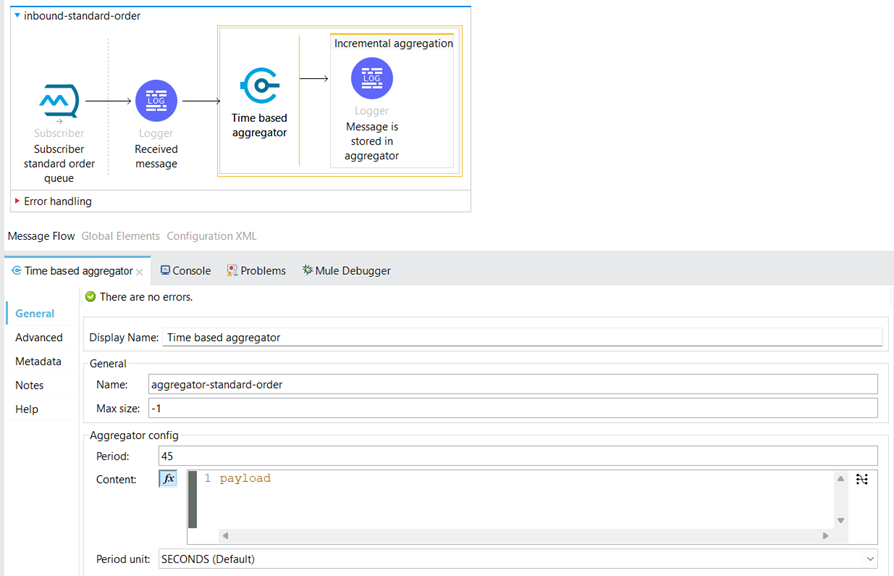
The flow is identical for express orders, emphasizing the simplification of process design for APIs and integrations.
The outbound.xml file contains two separate flows: one for standard orders and another for express orders, showcasing the versatility in building APIs and integrations.
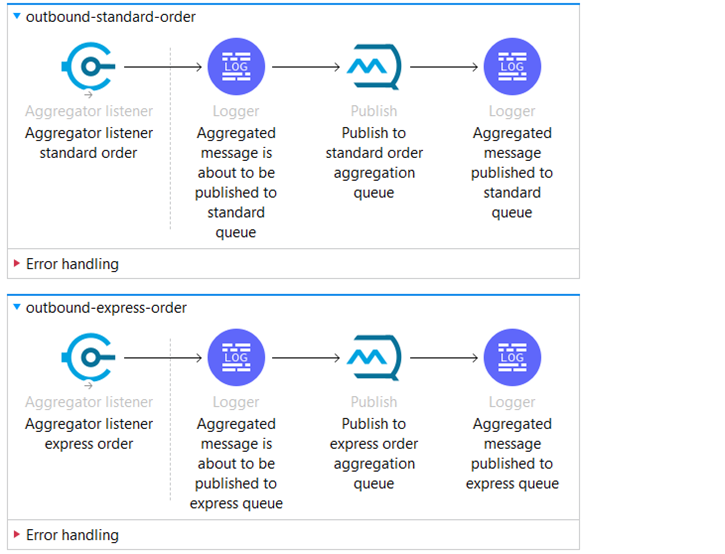
We’ll explain the first one, for standard orders.
The source of the flow is an Aggregator listener Component. This source listens to the previously defined Time-Based Aggregator. Once the aggregator releases its elements, this listener is executed.
The Aggregator listener Component is defined as “aggregator-standard-order,” which is the same name as the aggregator for standard orders in the inbound.xml file. The aggregator and the Aggregator listener must have the same name.
Because the Aggregator listener is a source, it is in a different flow than the aggregator. The listener cannot access the context from the aggregator’s flow and, therefore, cannot access the flow’s variables.
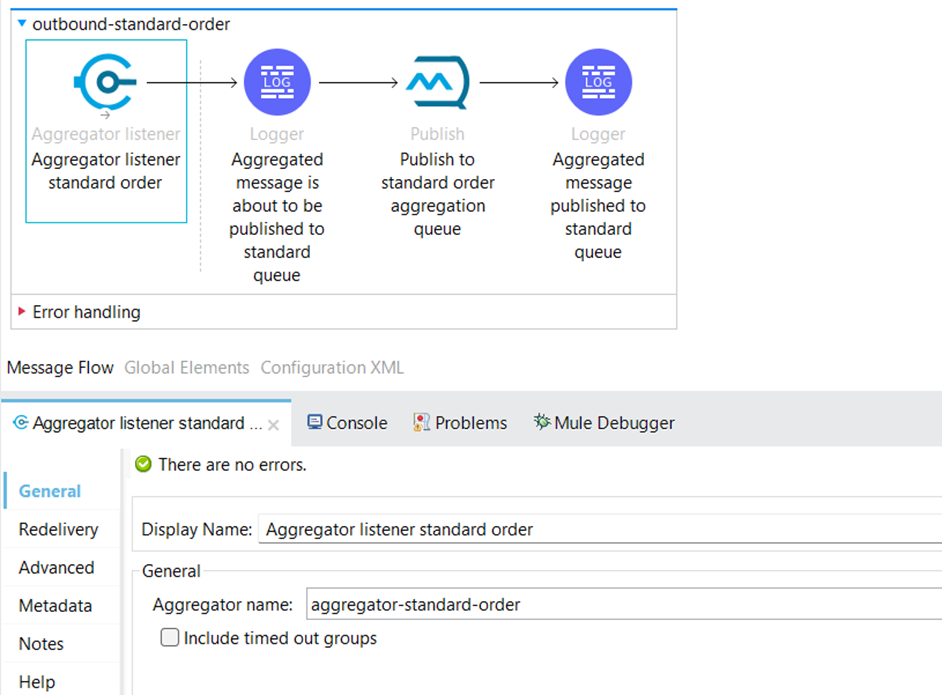
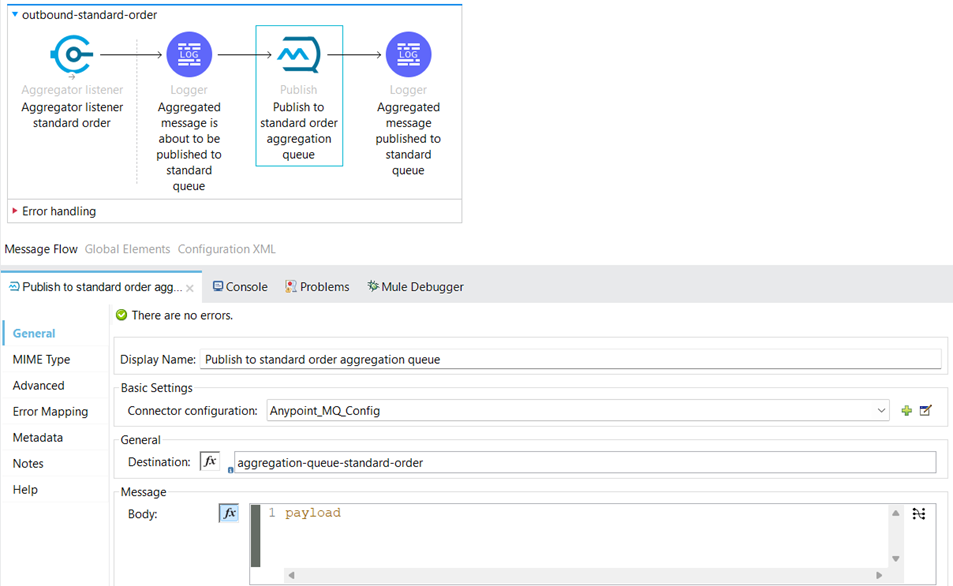
After the aggregator listener source gets the aggregated data, we publish the aggregated orders to another Anypoint MQ queue “aggregation-queue-standard-order”.
The same logic applies for express orders, but the Aggregator, Anypoint MQ queue, and the other components have different names.
System API
Within the System Layer application “iw-sys-api”, we have two flows, each featuring Anypoint MQ Subscribers as sources: one dedicated to Standard orders and the other for Express orders.
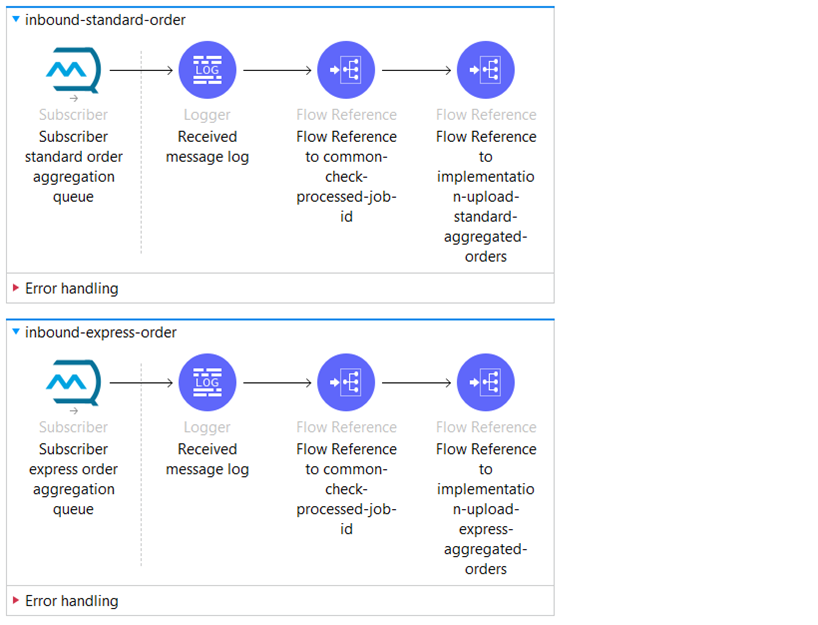
We will focus on the “inbound-standard-order” flow.
An Anypoint MQ subscriber will receive aggregated orders of the standard type from the queue “aggregation-queue-standard-order.” Then, we have two flow references that will route to separate subflows.
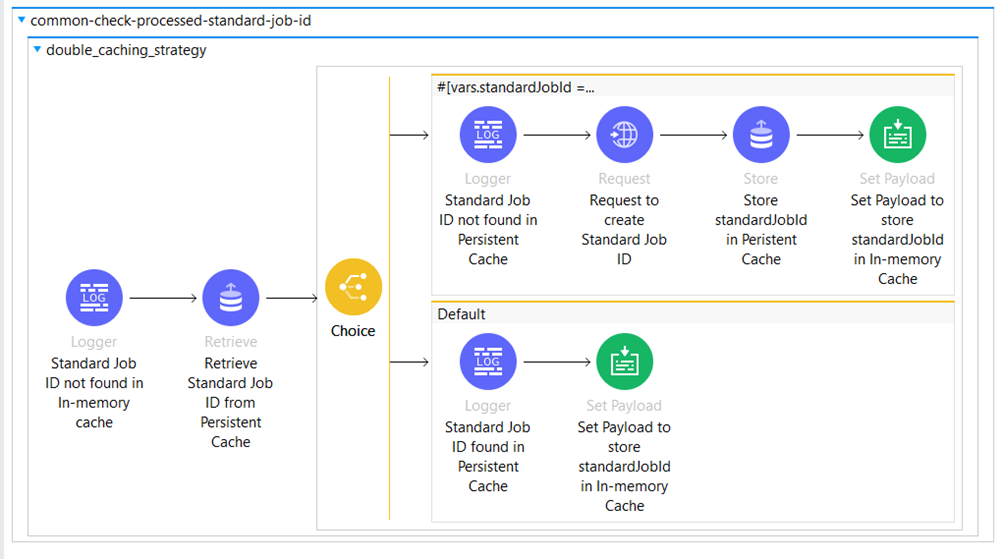
The first one will route to the common-check-processed-standard-job-id, where we have implemented a Double Caching Strategy. We use the Double Caching strategy to create a Job ID, which will be used to upload the aggregated orders to the external API.
As explained below, this approach is an attempt to avoid crossing OS v2’s API limits as much as possible.
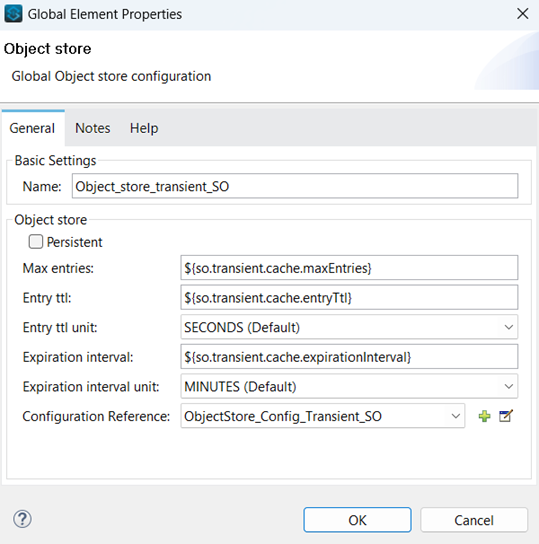
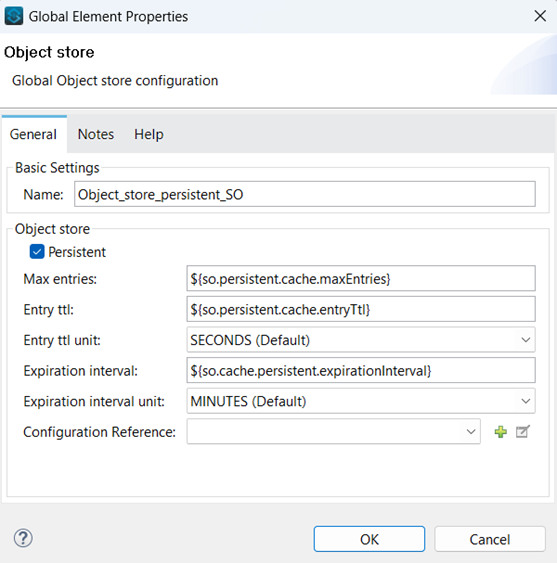
This approach uses a two-level cache – in memory (transient) cache and persistent OS v2 cache.
- The entry is first looked up into the in-memory cache.
- If the key is found in the in memory, it is returned; else the key is looked up in the persistent OS v2 cache.
- If the key is found in the persistent OSv2, the response is cached in inMemoryCache and returned to the client.
The API call is made if the Key is not found in the persistent OS v2. The response is then cached in both inMemory and persistent OS v2 cache, returned to the client.
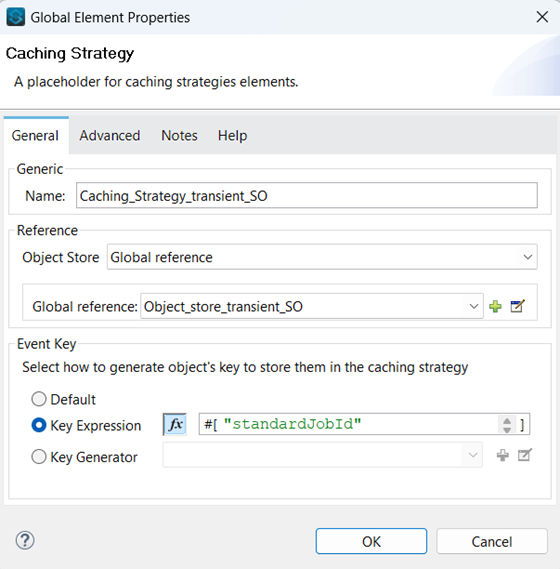
Below is the Double Caching strategy configuration, set in the global.xml configuration file.
Caching strategy that references Object Store config:
The Object Store Config referenced by the Caching Strategy:
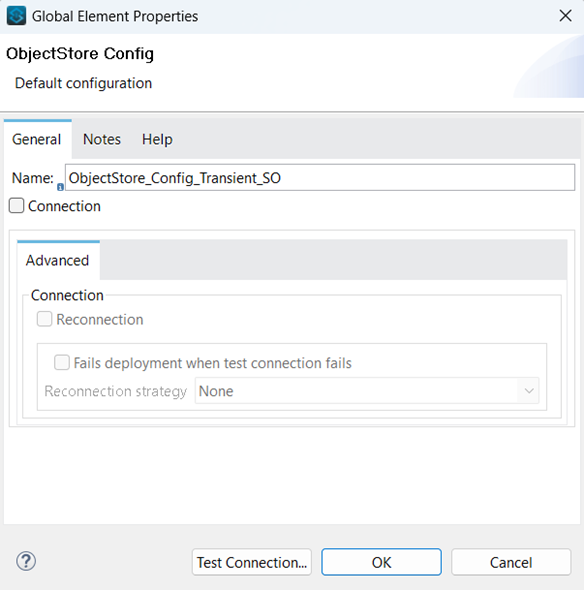
Object Store with previously defined OS Config set as Configuration reference:
Persistent Object Store Configuration:
Advantages of Double Caching Strategy
- The use of inMemory cache as the first-level cache,
- offsets the IO overhead required to retrieve cached in persistent OS v2 cache, and hence faster
- offsets the throughput concerns due to the rate-limiting applied on OS v2 (10 TPS, Free Tier/ 100 TPS, Premium SKU Add On)
- The use of persistent OS v2 as the second-level cache,
- helps share cache across multiple workers in the fabric
- enables us to store a lesser number of keys in cached or have reduced TTL for the cacheKey, to get more throughput out of the same worker size
Within the flow reference component, which refers to the Double Caching flow, we store the Job ID as a target variable.
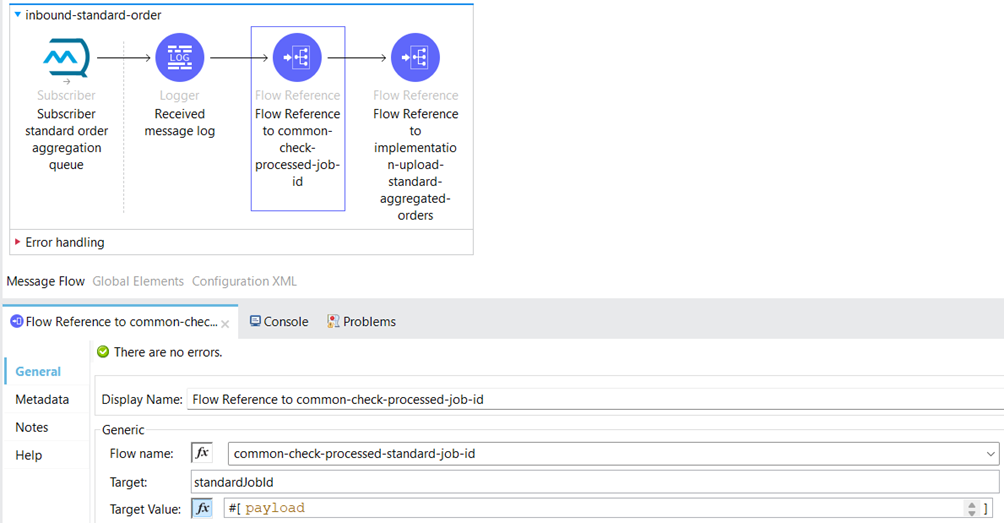
Below, we’ve organized flows specifically for uploading the aggregated orders. We’ve segregated them into separate flows: one for standard aggregated orders and another for express aggregated orders, as the external API handles these order types through different endpoints.
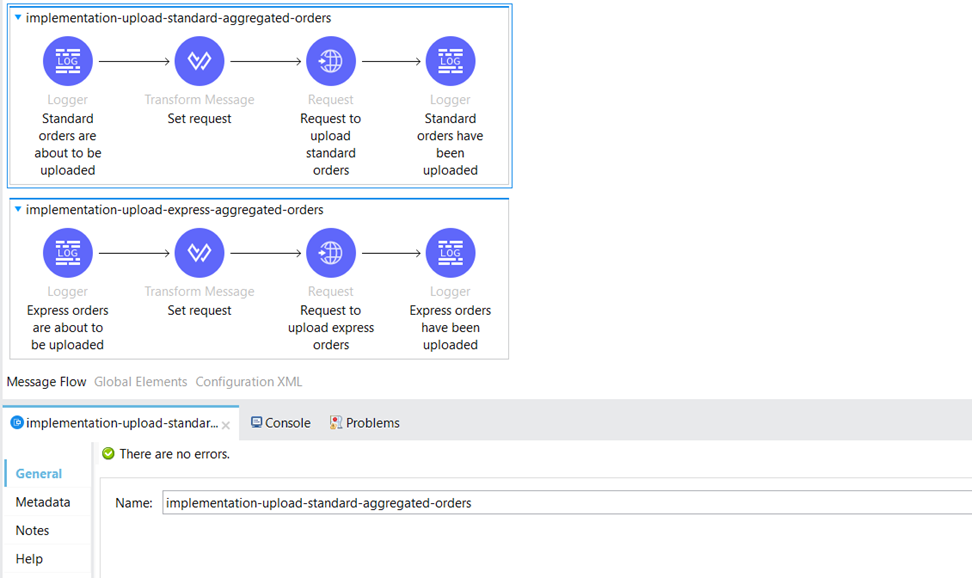
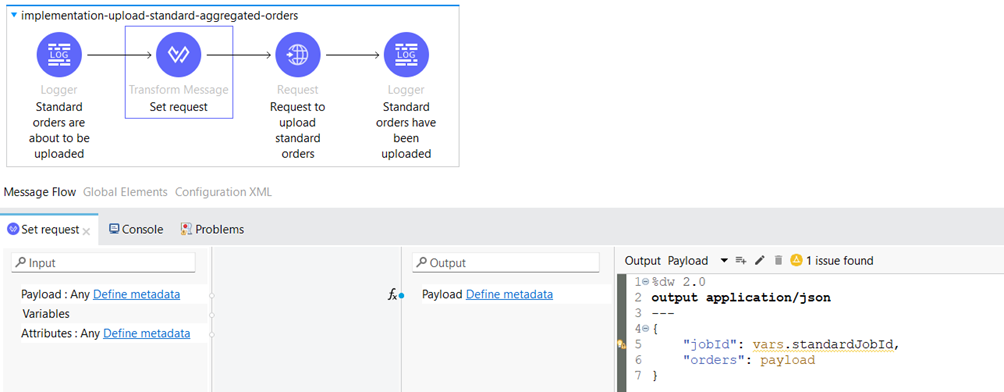
We configure the request payload in the Transform Message Component before sending the request to the client API.
Multiple HTTP POST requests can be made with aggregated messages using the same job ID.
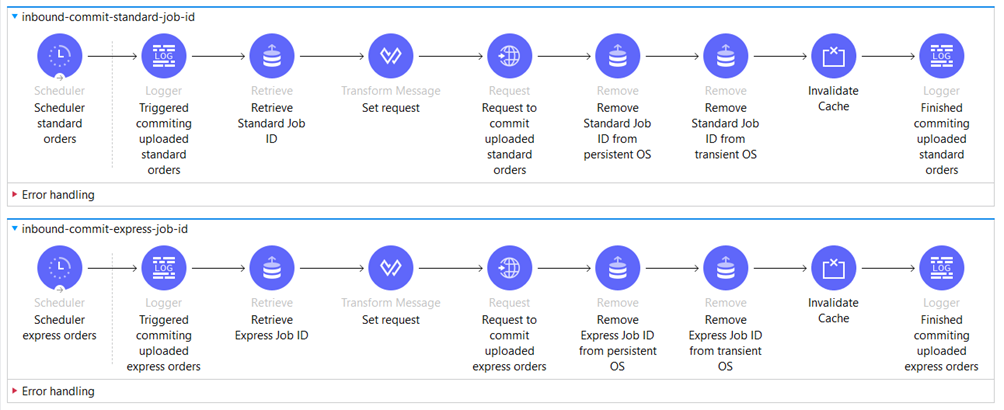
Once completed the Job ID must be committed so the orders can be visible in the external system for further processing.
We have separate logic for that purpose. Schedulers trigger two flows, each defined with different periods for standard and express orders.
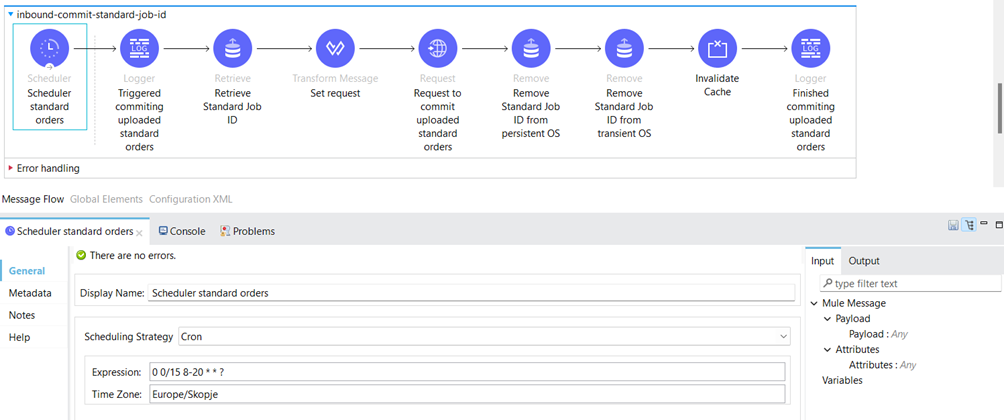
The Scheduler component is a Mule event source that triggers the execution of a flow based on a time-based condition. The Scheduler sets a scheduling strategy at a fixed frequency or an interval based on a cron expression.
We’ve utilized cron expressions for both flows. For standard orders, the scheduler is set to trigger every 15 minutes between 8 am and 8 pm daily.
To commit the Job ID to the external system, we must first retrieve it from the Object Store. For that purpose, we use the “Retrieve” Component which retrieves the value of given Object Store key. The key is “standardJobId”.
Following that, we configure the request to the external API for committing the Job ID.
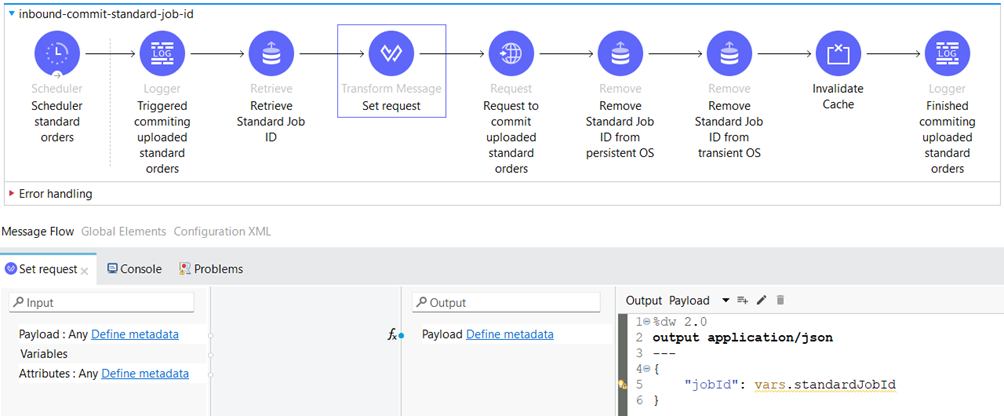
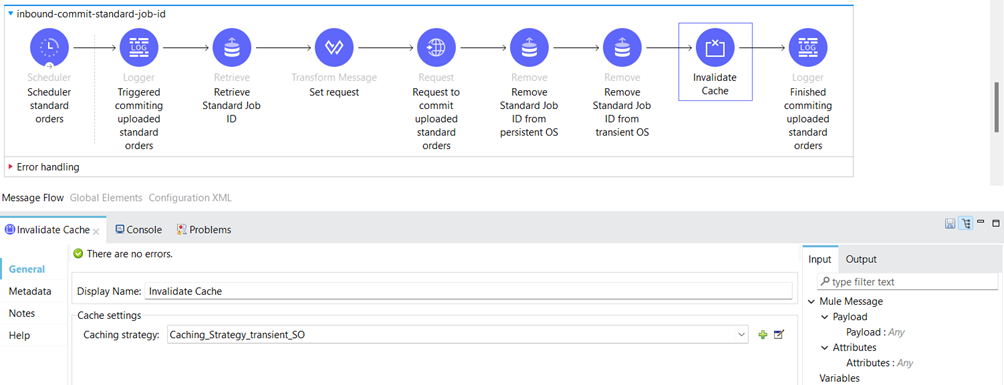
After committing the Job ID, we need to remove it from the Object Store and invalidate the cache.
Since the volume of orders is high, utilizing CloudHub Clustering to manage this volume provides several advantages.
Clustering provides scalability, workload distribution, and added reliability to applications on CloudHub 2.0. This functionality is powered by CloudHub’s scalable load-balancing service and replica scale-out.
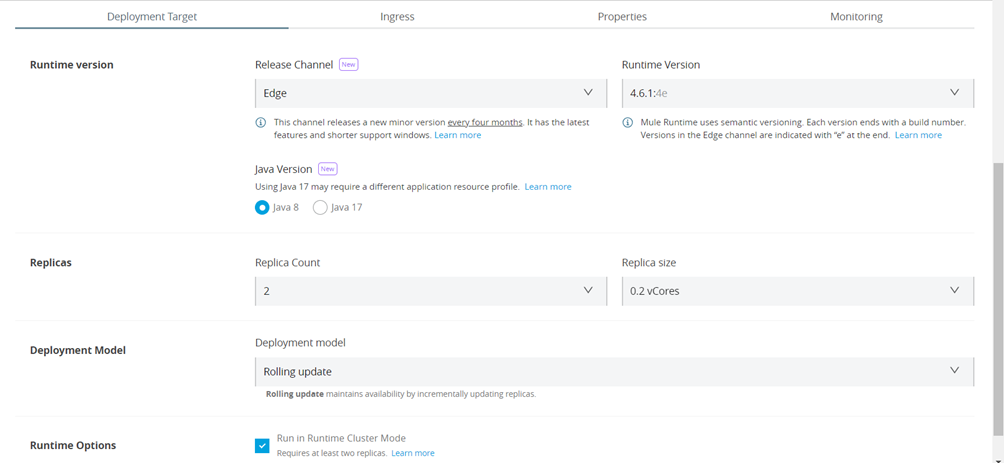
For CloudHub Clustering to be set, the application must be deployed on at least two replicas.
The Clustering can be set on Runtime Manager.
We have set the application with 2 replicas and 0.2 vCores and we have checked the “Run in Runtime Cluster Mode” checkbox, which means that the Clusteting is on.
CloudHub clustering evenly distributes incoming orders across multiple worker nodes, preventing any single node from becoming overwhelmed. This ensures timely order processing and reduces delays.
By distributing orders across multiple nodes, CloudHub Clustering maximizes resource utilization. Each node efficiently utilizes its resources, improving throughput and minimizing response times for order processing.
CloudHub Clustering sets up a high availability system, guaranteeing continuous operation even if hardware fails. This reduces downtime and maintains steady service.
Conclusion
The Time-Based Aggregator simplifies order aggregation by grouping orders into batches based on time intervals. By batching orders based on a time interval and optimizing request frequency, the Time-Based Aggregator helps improve the efficiency and performance of the order processing workflow.
By implementing the Double Caching Strategy with MuleSoft, we effectively mitigate throughput concerns arising from rate-limiting constraints on OSv2 (e.g., 10 TPS for Free Tier and 100 TPS for Premium SKU Add-On). This optimization ensures the application can operate within these limitations while maintaining optimal performance and throughput.
CloudHub Clustering offers a reliable setup for efficiently handling large order volumes. It helps distribute workloads, improves fault tolerance, allows for scalability, optimizes resource utilization, and maintains system availability, enabling businesses to create robust and scalable order processing systems.
In today’s competitive e-commerce landscape, efficient order processing is crucial for success. MuleSoft provides a robust toolkit to streamline this process, ensuring a smooth and scalable solution for businesses of all sizes.