
Why sentiment analysis?
Did you know that 90% of the data in the world today was created from 2010 onwards? And that we are collectively generating over 29000GB of data every minute, every day?
In this ocean of data, it is difficult to get useful information without finding a proper way to manipulate it. Machine learning made our lives much easier. It is a method for data analyses and it is based on the idea that systems can learn from themselves, identify patterns and make decisions with minimal human intervention.
Sentiment analysis is the process of computationally identifying and categorizing opinions expressed in a textual format in order to determine if the author’s opinion towards a particular topic is positive, negative or neutral. It uses elements of machine learning such as latent semantic analysis, support vector machines, “bag of words” etc.
It can be applied at different levels of scope: document level, sentence level, and sub-sentence level.
Textual data is usually unstructured, and as such the process of analysis is time-consuming and expensive. The importance of sentiment analysis is due to the fact that it makes the process of analyzing scalable and real-time.
The problem
Our blog post is focused on how sentiment analysis is performed on structured and unstructured datasets via real examples. The example with the structured data is created using KNN classifier and the one with unstructured data is created using topic modeling with Latent Dirichlet Allocation (LDA). In the first example, we will try to classify the documents into two categories: sport and cooking. In the second example, we will try to identify the features that the customers discussed.
We will use Python, including the following libraries:
- nltk – used for building programs for statistical natural language processing.
- Scikit-learn – a machine learning library.
Sentiment analysis using KNN classifier
KNN classifier finds k nearest neighbors from training data and votes among them. This classifier decides the label for the new document based on its distance to the instances of the training data. It evaluates the categories of the K nearest neighbors and classifies the new document based on the most common category among its k neighbors. We are using the clustering approach of the nearest neighbors to suggest the nearest documents related to the entered review.
Now, we will use the labeled dataset for analysis. The data belongs to two categories, sports, and cooking:

The user is able to write a new document and it will be classified with one of the already given labels in the train dataset, then sentiment analysis will be performed on that input.
The project starts with importing the nltk library. Then, the data is read from the dataset. Our dataset consists of six reviews and labels separated with a colon. Three of the documents are labeled as sports, and the other three as cooking.
Everything is converted to lowercase as part of the preprocessing step. Using sent_tokenizer the document is separated into different sentences, then they are converted into lists:
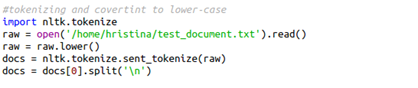
We need to replace the punctuations with an empty string:
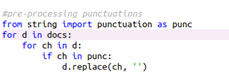
Also, we need to remove the stop words. Stop words are defined as commonly used words such as “the”, “a”, “an”, “in” etc. Again, it is iterated through the documents and all the tokens. And if the token matches the punctuation list, then that word is replaced with an empty string. After this step, the document does not contain punctuation and stop words.
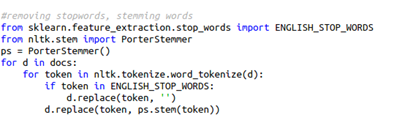
A commonly used approach for text representation is TF-IDF. In TF-IDF, the word that is frequent in all the documents gets negative weight. In the same loop, we will include the process of stemming and each word will be replaced with its stem. Then, it is given functionality in which the users enter a sentence with a review and the model classifies it with one of the given labels.
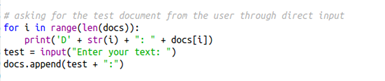
Everything that the user types will be appended into the end of the document list as the last document.
This is how the new document will be part of the analysis.

After these steps, we need to make a preparation for the classifier. So, the input documents are separated from the labels and the unnecessary empty spaces are removed. Then the dataset is vectorized with the help of IF-IDF vectorizer. The process of vectorization is converting a collection of documents into matrix.


The most important part of the process is the training/testing part. The classifier is imported and is trained on the documents that have initially existed in the dataset and is tested on the document that the user entered.

Let’s say that the input is “I like cooking”. We can see that the label is predicted correctly and that is “cooking”.

Next, we are interested in sentiment analysis so we can determine if the documents have a more positive or more negative meaning. For that purpose, the wordnet library is imported. Two reference part is created, for the words good and evil. Then, all the words in the last document are parsed and the similarity between each word and the reference words is being checked. Two scores are created, a positive and a negative score. If the difference between the negative score and positive score is greater than 0.1, then the review is considered as negative and if the difference between the positive and negative score is greater than 0.1, it is considered as a positive review. Any review, positive or negative that has a score less than 0.1 is ignored and considered as a not objective or neutral review.

So, our review is labeled as “cooking” and the opinion is not shown since it is considered as neutral. But if we change our input into “I love to cook”. Again, it is labeled as “cooking”, but this time it gives positive evaluation with strength 1.38, which is a quite positive score.

The third part of the program suggests the most similar document. After the user enters the review, it is labeled, evaluated as positive or negative and in the end, it is suggested the closest document related to the entered review and the distance measured with the NearestNeighbors classifier.

This is very useful when we give a review for a movie, book, hotel, etc. because the model can give similar suggestions to our preferences.
Sentiment analysis using topic modeling
Topic modeling is a clustering technique for discovering the abstract topic that occurs in a collection of documents. Topic models are used as dimensionality reduction techniques. Normally, in a text, there are thousands of words and if we provide our model with all of them, the model will not perform very well. So, we need to reduce the words to a more meaningful number without losing the important features.
Latent Dirichlet Allocation (LDA) is a statistical model that generates the topic based on the word frequency from a set of documents. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions. LDA imagines a fixed set of topics. Each topic represents a set of words. LDA maps all the documents to the topics so that the words in each document are mostly captured by those imaginary topics.
Here we will use unlabeled data. The dataset that we are using contains hotel reviews and we are doing some assessing/evaluating of the data. This way we can identify the features that people have discussed for the particular hotel and what they liked or disliked about them. We are processing the data sets and identify 5 key subject areas that are most frequently discussed in their reviews. Then, we are going to perform sentiment analysis and see how people have rated those aspects. We are using a sample dataset from the UCI repository.
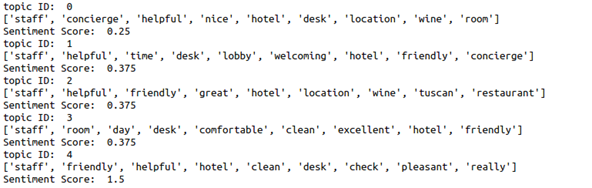
After running the code, we get 5 topics. Each topic is represented by the 10 most relevant words and based on it gives the sentiment score that is given by the users.
Again, the project starts with importing nltk library and reading the data from the second data source. (show the dataset) .

The data source consists of hotel reviews from the visitors.

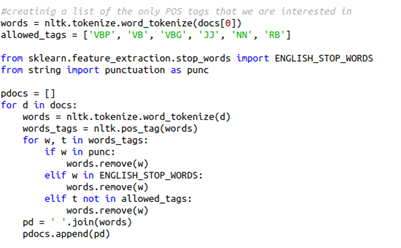
The dataset is preprocessed and the stop words are also removed. Then all the documents in the list are iterated and the text is tokenized in words. These words are passed through the nltk pos_tag function which will give the words along with their tags. Again, the words are iterated and punctuation, stop words and words without tags are removed. All the remaining words are combined with a string that is appended to the pdocs (preprocessed documents).
Next, the input is structured with count vectorizer and the pdocs are passed through it. The structured input is stored as matrix_X.

The features are stored in a variable “features” since the topic model will return the id-s of these words, and they are reversed again into actual words. The number of topics is set to five and the model is trained.

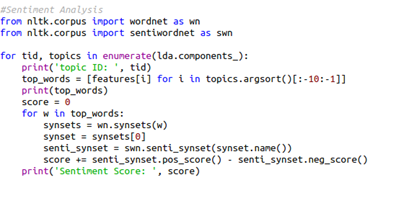
In the final step, sentiment analysis is performed. The analysis is performed with Sentiwordnet and getting the synsets (a group of synonyms) is done with Wordnet.
All the words are gathered from lda.components and we are interested in the top ten most common words for each topic. There is a total of five topics.
All the topics are printed and sentiment analysis is performed on each of the topics. Each word in the topic is processed and we get synset of the words using Wordnet. The name function is called on the first word and is passed on to the senti_sys function. The first of the list is used and it is called the name function on it and it is passed to senti_synset function of the Sentiwordnet to give us the senti_synset. Then, the functions pos_score and neg_score are applied and if their difference is a positive value, the score of the word is positive, otherwise, it is negative. All the scores of all the words that belong to the topic are collected and the total score for the topic is calculated.
This project will perform sentiment analysis for documents and the score is accumulated of all the words in the document. The output has five topics and each topic consists of 10 words and its sentiment score.
Conclusion
The crucial component for a product’s success is the customer’s opinion and with the use of sentiment analysis, we can easily evaluate it. That’s why sentiment analysis is enormously important in any field in the industry. Additionally, it offers options for exploring public opinions on social media, reviews for products and services, articles and so on.
If you are interested in sentiment analysis and want to discuss it, do not hesitate to contact us.