

What is SnapLogic?
SnapLogic is a unified iPaaS (Integration Platform as a Service) that provides a number of connectors to a variety of data sources, applications, and APIs, by delivering maximum performance and productivity. As a SnapLogic partner, ⋮IWConnect has successfully completed many integration projects in the data warehousing field and API processing.
What is ETL?
ETL (Extract Transform Load) is a process of data loading from the source system into the data warehouse. It usually also encompasses cleaning as a separate step. The Extract step covers the data extraction from the source system in order to prepare it for further processing. The cleaning phase deals with identifying and removing data errors and inconsistencies in order to improve data quality. The transform step applies a set of rules to transform the data from the source to the target. During the load step, the extracted and transformed data is imported into a target database or data warehouse.
Pipeline design considerations
Here are some design patterns we usually use during the pipeline design process:
- Introspect source metadata as columns, data types, and primary and foreign keys in order to design efficient data flow pipelines.
- Use SnapLogic options to efficiently map and transform data from the source to the target.
- Simple atomic pipelines. Devise the solution to be at the absolute minimal complexity level that will efficiently solve the problem.
Always parametrize attributes that are likely to change, at a pipeline level. This is particularly important during integration or even simple data transfers. Object names should be parametrized, in order to provide centralized control and the ability to make changes to source and target objects quickly and efficiently. This comes in handy when there is a project that houses a couple of tens of pipelines. It will be a difficult process to go at each and every one of them and change one or two objects’ names in two or more snaps. SnapLogic gives us the ability to do this even in complex SQL queries, and there is a security concern for the Snaps that use fields of parameters – they can be subjected to SQL injection.
Maximize pipeline reusability. This is very important advice for the development of pipelines that implement ETL for a data warehouse. The creation of common pipelines that can be reused throughout the code helps in minimizing the development effort by avoiding unnecessary redundant work and also minimizes the probability of error.
Parallelize the execution across multiple execution nodes.
Example: Use Case
The demonstration is through an example of how to extract a substantial amount of data from operational databases and load it in a warehouse staging area.
Let’s assume that a transfer is needed for 330 days’ worth of data, taking into account that there are a couple of hundred thousand records per day in the staging area. In a more complicated flow, the data is situated in two tables residing in two different schemas on the same database (an actual real-world problem).
A good approach here will be a design that offers reusability of the pipelines independent of source and target object names (Figure 1):
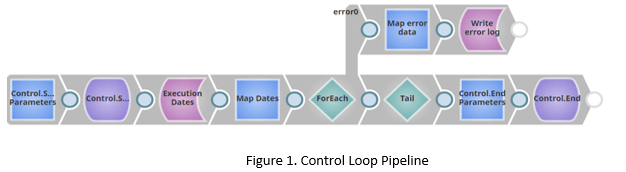
The Control Loop pipeline is comprised of several building blocks i.e. snaps:
- Start Parameters constructs mappings and passes parameters to the nested pipelines: Control.Start and Control.End, which creates control records for tracking the execution history of the pipeline.
- Execution Dates snap gives us the actual dates for which we are going to call an additional pipeline called a Worker pipeline (Figure 2).
- Each snap is the one that is calling the Worker pipeline (Figure 2) for each input date.
- Tail snap ensures that the mapper and subsequently the Control.End will be called only once, no matter how many dates will be processed on the ForEach snap input. Lastly, the Error output of the ForEach snap logs the error details in case of an error for an executing instance of the ForEach snap.
Next, we’re going to examine the Worker pipeline (Figure 2):
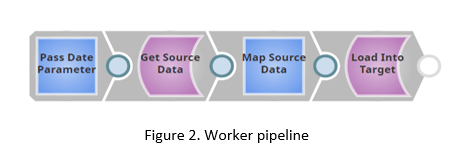
The Worker pipeline is a fairly simple pipeline that reads the parameters passed from the Control Loop i.e. the ForEach snap of the Control pipeline (Figure 1).
Component description:
Get Source Data, queries the data from the database, based on the data received from the mapper which in turn receives the data from the ForEach snap from the Control. The results are written in the Warehouse staging area with the Load Into Target snap that ensures transaction consistency in writing the data by performing Redshift Bulk Load operation.
The benefit comes from the fact that this approach is reusable and you can easily change the object names and regulate the number of instances that the Control pipeline is executing through the ForEach snap.
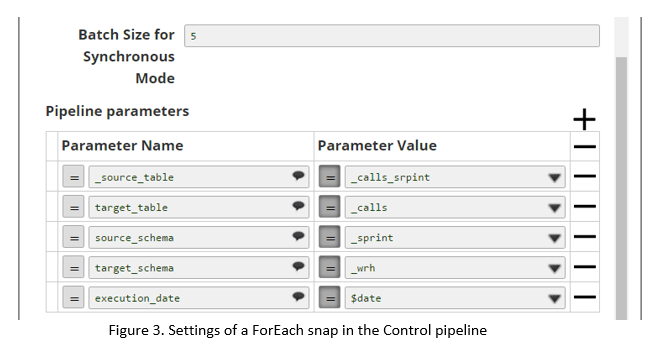
The execution of the presented solution would be by creating simple one-snap caller pipelines, that will execute the control pipeline and pass appropriate parameters to the ForEach snap in a Control pipeline (Figure 1) for both source and target tables. The limitation of the executing instances is enabled by changing the Batch Size for Synchronous mode as depicted in Figure 3:
However, you will not always be provided with datasets or data sources that you can split and load incrementally just by a date field. Sometimes, you will find yourself having to go with a static approach, and in most cases, you can use what SnapLogic provides to piece together a solution that will be easy on the source and on the executing environment in terms of processing vast quantities of data.
The approach here will be the same as the example provided with one difference: instead of passing an execution date for the selection of records, limit numbers will be sent for selection and an offset that will execute Worker instances as it sees fit (Figure 3).
Conclusion
As part of our integration projects, we deal with a lot of challenges, and we solve those challenges using our extensive experience and best practices and SnapLogic’s capabilities. The approach described above aims to demonstrate how easy and time-saving it is when the vast plethora of tools that SnapLogic offers are used, either for warehouse maintenance or real-time system integration. By making sure reusability and abstraction are taken into consideration during the development process, we deliver solutions in the shortest time possible that are easy to maintain and build on further down the path of development.