
Intelligently index your data, optimize retrieval processes, and boost efficiency with Azure AI (Cognitive) Search Service

We’ve reached the data-centric construct of the system, the Azure AI Search, previously known as Azure Cognitive Search. By definition, it is a fully managed search-as-a-service solution provided by Microsoft Azure. It allows building rich, powerful search experiences over large volumes of content, whether that content is structured or unstructured.
As an enterprise-ready search and retrieval system, it offers a comprehensive set of advanced search technologies built for high-performance applications at any scale. This makes the service a perfect choice for designing retrieval systems when building RAG-based applications on Azure, with native LLM integrations between Azure OpenAI Service and Azure Machine Learning.
Scope of Work
I started the series by showcasing the implementation of real-time speech recognition, translation, and data storage using a chain of Azure AI Services. I then proceeded by extending the chain and introducing an intelligent document processing pipeline based on Azure OpenAI and Azure Document Intelligence with Azure Functions.
These two parts of the cloud-native solution resulted in separate dedicated blob storage containers on Azure, which will be our starting point for utilizing the Azure AI Search Service. We can consider these storage containers as designated central locations for preserving the data we will need for intelligent search and the chat-based interaction in perspective.
Why using Azure AI Search?
As explicitly stated in the Microsoft documentation, this service can be used in both traditional and GenAI scenarios, and common use cases include knowledge base insights (catalog or document search), information discovery (data exploration), Retrieval Augmented Generation (RAG), and automation. I want to use it as a solid foundation for building the storing and retrieval mechanism needed for powering the Agentic RAG scenario that will be presented as a wrap-up of the series.
The Azure AI Search provides a wide array of features and functionalities for search and query scenarios, particularly for intelligent search processes where different configurations and enhancements can be added to make the pipeline very performant and accurate. In simple terms, I will present the two core functionalities related to the Indexing and Querying operations.
Indexing
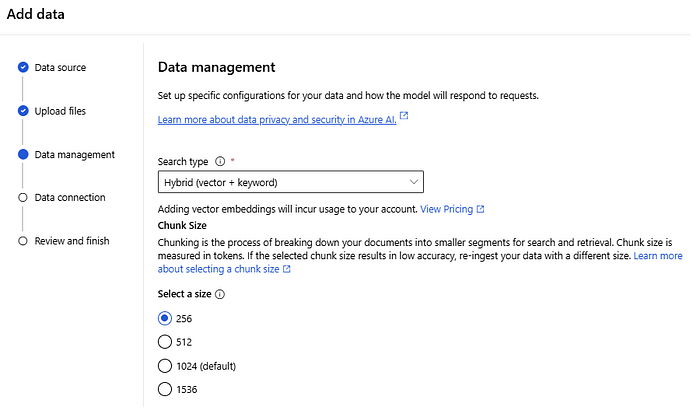
Indexing is the intake process that loads or ingests content into the search service and makes it searchable. This is done by processing the text into tokens and storing them in inverted indexes, while inbound vectors are stored in vector indexes.
The indexing is based on JSON file formats. It’s worth mentioning that there is a super powerful option here, and that`s the Skillets feature which can enhance the flow by automatically adding and applying Optical Character Recognition (OCR), document analysis and structure understanding, translation, etc. Even more exciting is the ability to perform data chunking and vectorization during the indexing process.
Querying
On the other hand, the querying mechanism comes into play once the searchable content is ready by providing the capabilities of query constructs for a broad range of scenarios, from free-form text search, to highly specified query patterns, to vector search. Generally, there are few types of query types: Full Text Search (represented by inverted indexes of tokenized terms.), Vector Search (represented by vector indexes of generated embeddings), Hybrid Search( combination of full text search and vector search in a single query request), and Plain text and alphanumeric content which is a raw content, extracted verbatim from source documents, supporting filters and pattern matching queries like geo-spatial search, fuzzy search, and fielded search.
Use case
I will use the Azure AI Search for creating an index consist of both blob storage containers containing the data from the real-time communication and intelligent document extraction. It will be the data that I will use in the operational process for introducing external knowledge to the RAG based solution that will be designed to work in agentic manner. So, basically, I will use the default natively provided configuration for the Indexes, Indexers and Data Sources on Azure AI Search. Let`s briefly explore what each of them will bring to the system.
Azure AI Search Configuration
Data source
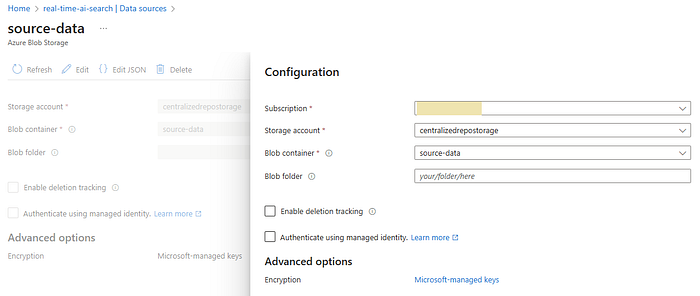
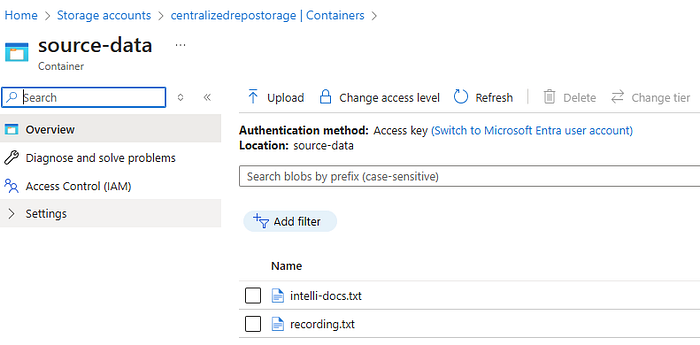
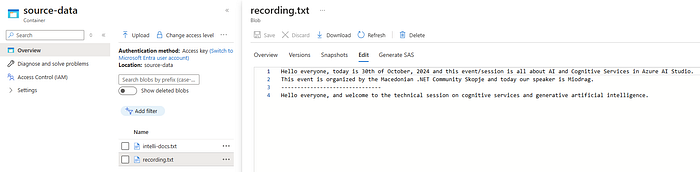
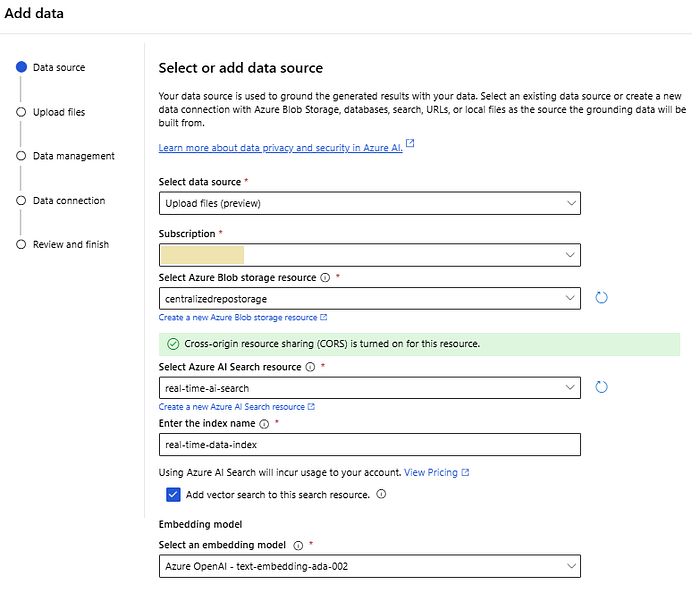
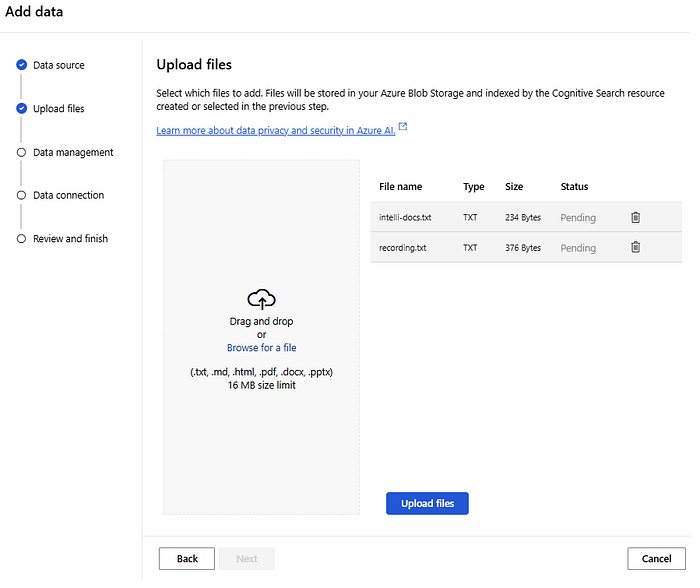
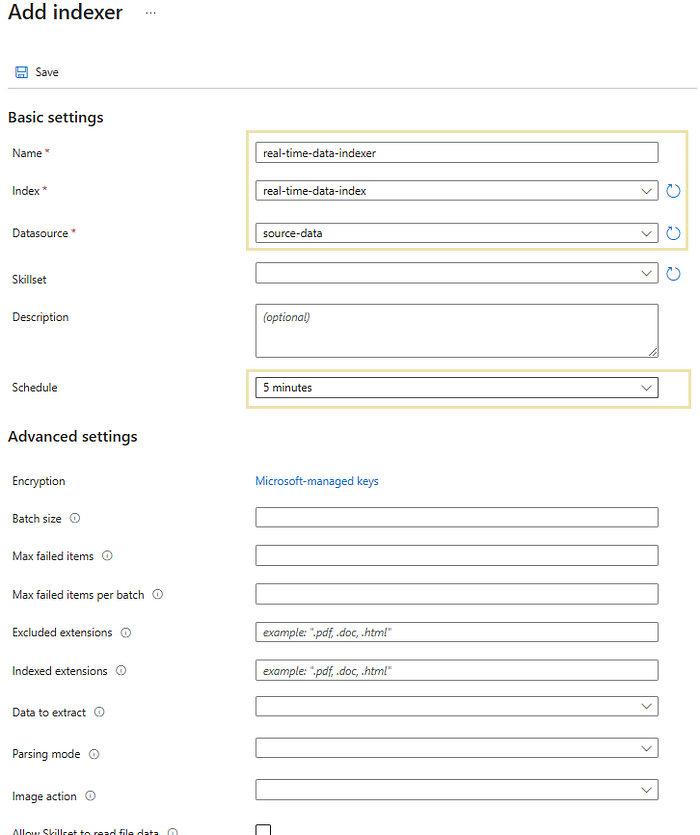
The data source is the location and structure of the data that will be indexed for search. It defines the external data source from which Azure AI Search pulls content to create and update a search index. These sources can include databases, storage accounts, and other services from which searchable content is extracted and processed. Datasource instances can be created from different sources, such as Azure Blob Storage, Azure Cosmos DB, Azure SQL Database, and more. Since I stored the data in a storage account, let’s create a new datasource from the existing ‘source-data’ blob storage containers. Here, I’ve preserved the real-time recordings (recording.txt) and the summarization of the extracted document information (intelli-docs.txt).


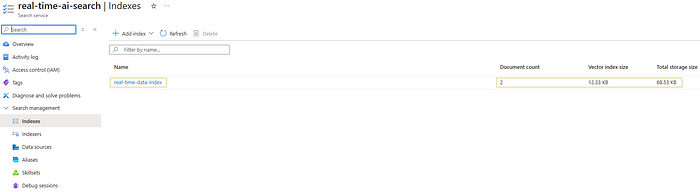
Index
Azure AI Search indexes represent the searchable content available to the search engine for indexing, full-text search, vector search, hybrid search, and filtered queries. They are defined by a schema and can be created using the Azure portal, SDK, .NET, and other supported SDKs available in the documentation page.
I will create the index through the Azure portal, specifically by using the Azure OpenAI Service and Chat Playground available as part of the Azure OpenAI Studio. This is something I have already covered and showcased as part of the previous series related to the Azure OpenAI Studio itself, in the article “Azure OpenAI Studio — Chat Playground with GPT-3.5-turbo & GPT-4 Models in a Nutshell”.
Indexer
Indexers generally represent a tool that extracts textual data from cloud sources and populates a search index using field-to-field mappings. This enables the search service to automatically pull data at predefined intervals, allowing them to run on demand or on a recurring schedule based on specific requirements. In our case, I will configure it to trigger ‘every 5 minutes’. Indexers can also handle skillset execution and AI enrichment, such as OCR for images, text chunking, and text translation.
This configuration will ensure that our index data is always up-to-date with the latest data processing from the real-time communication and document intelligence processes.
What We Have and Where We Are Headed
And that’s basically it. Now we have a system capable of automatically and asynchronously recognizing and translating speech, while also adept at document processing, extracting, and reasoning over data from different types of documents.
The data is stored in a centralized blob storage location, which serves as a solid foundation for creating a vector index. I also configured an indexer instance so that the system can check for new data in the data source and incrementally and automatically update the created index. Therefore, we are ready to wrap it up by using a RAG-based agent (assistant).
Besides the data we have so far, this agent will also be able to introduce and integrate third-party implementations to bring even more external knowledge to the system. The end goal is to establish a chat-based interaction module for intelligent search and reasoning over data.