
Introduction
No matter how big or small a company is, all of them spend a certain amount of time processing documents, regardless of their form (printed or scanned). In this regard, we all know that employees in Healthcare companies spend a large part of their working time in writing forms (structured documents) and notes. An efficient way to deal with the high volumes of documents is to automate the process. In our blog post, we are going to explain how we can use an RPA automated process for scanning and data analysis of two Healthcare documents. The documents that are being used for our process are two of the most used Healthcare documents in the USA (The Health Care Proxy and The HIPAA Form).
Automating tasks as mundane as this one, not only saves time by eliminating manual work and searching through documents, but it also reduces errors and improves work quality. If you’re already processing a lot of documents in your company, then you already know that as time passes, the process becomes even more challenging.
Robotic Process Automation (RPA), or software robots helps humans automate highly manual, mundane chores giving them more time for higher-value tasks and business goals. These auxiliaries make our lives more facile and more interesting as we can delegate our routine paperwork to them and concentrate on more productive and efficient work. Using RPA technology, we can facilitate our work by digitizing the art of handwriting and data transfer from one document to another.
The solution is made by using the RPA tool – UiPath. UiPath is a very powerful tool that can solve almost every problem that can be automated. As we mentioned before, this solution processes structured medical documents in PDF format. In UiPath there is a package called Intelligent OCR. The Activities included in this package greatly facilitate the process of processing this type of document and recognizing the text in it. What we did with this robot is create a solution that decreases the load of work that employees in medical institutions have and is connected to the processing and extracting of information from all kinds of documents.
Creating the process
The process is a combination of intelligently getting, reading, and extracting the data from the PDF files to an Excel document.
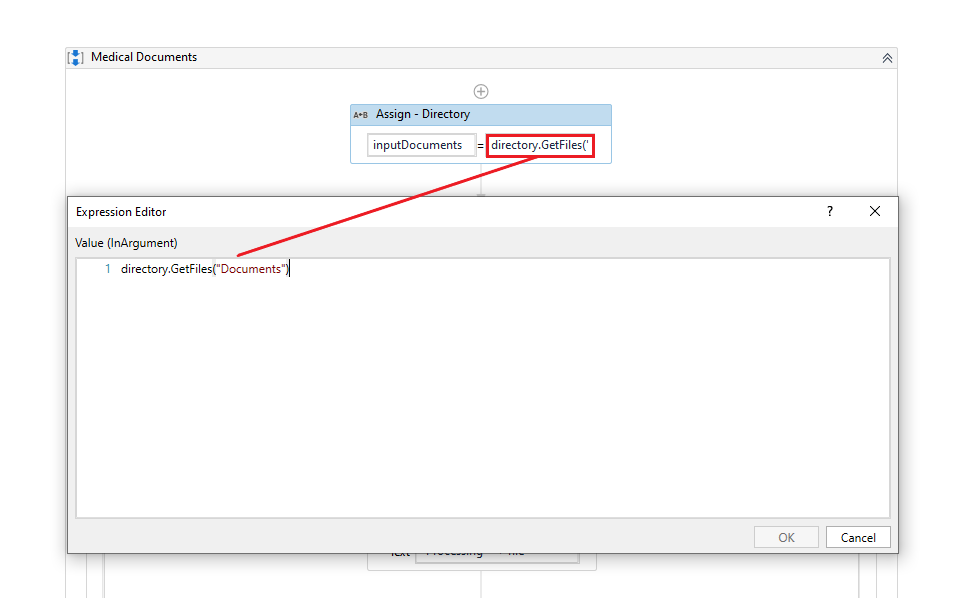
The first step of the process is getting the directory of the PDF files. In the Assign activity, we define a variable that will represent the directory. The directory is taken with an expression (directory.GetFiles(“Documents”)) that is declared to a variable (inputDocuments), Documents is the tile of the folder where the PDF files are located.
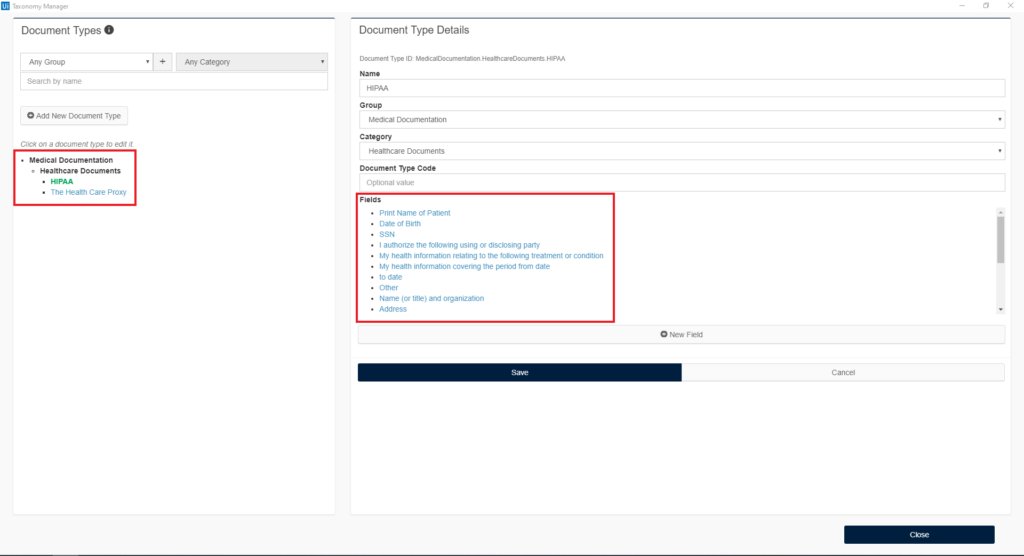
Before we start with everything we need to install the UiPath.IntelligentOCR.Activities package in the Manage Packages section in UiPath studio. After the installation, the Taxonomy Manager icon appears in the top panel of the studio. With the Taxonomy Manager, we can structure or define the data that should be extracted from the document, for example, text fields, checkboxes, and so on. In this project, as I mentioned we are processing two structured medical documents. From this PDF document, we are trying to extract specified text fields.


In the Taxonomy Manager first, we need to define Groups and Categories for easier handling of the documents that will be processed. After that, we are adding a new document and the text fields that we want to get data from.
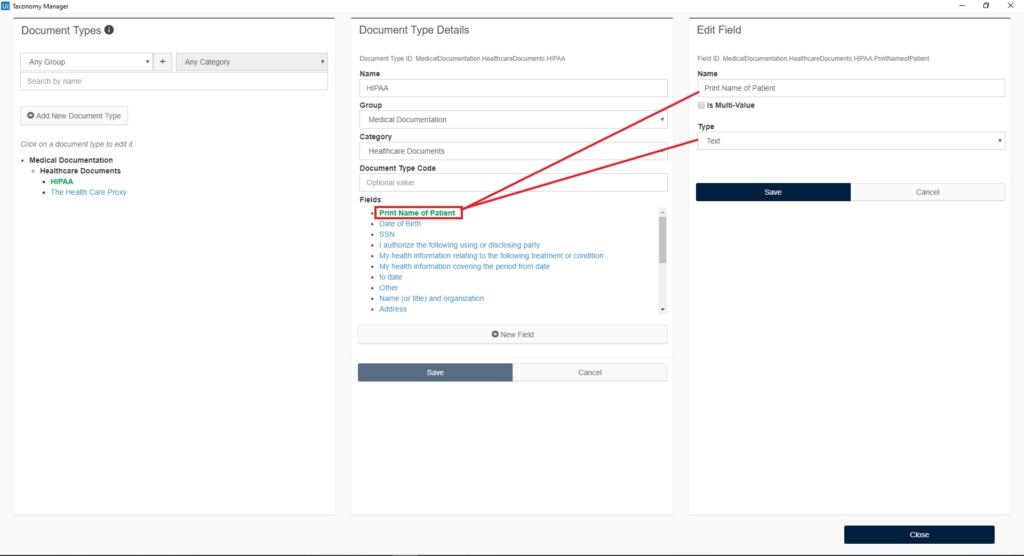
We write the name of every field, along with the type of data value that we extract, for example, text, date, numbers, etc.
After we have finished with the Taxonomy Manager, a Load Taxonomy activity is added and in this activity, a variable for loading the taxonomy of the documents is assigned.
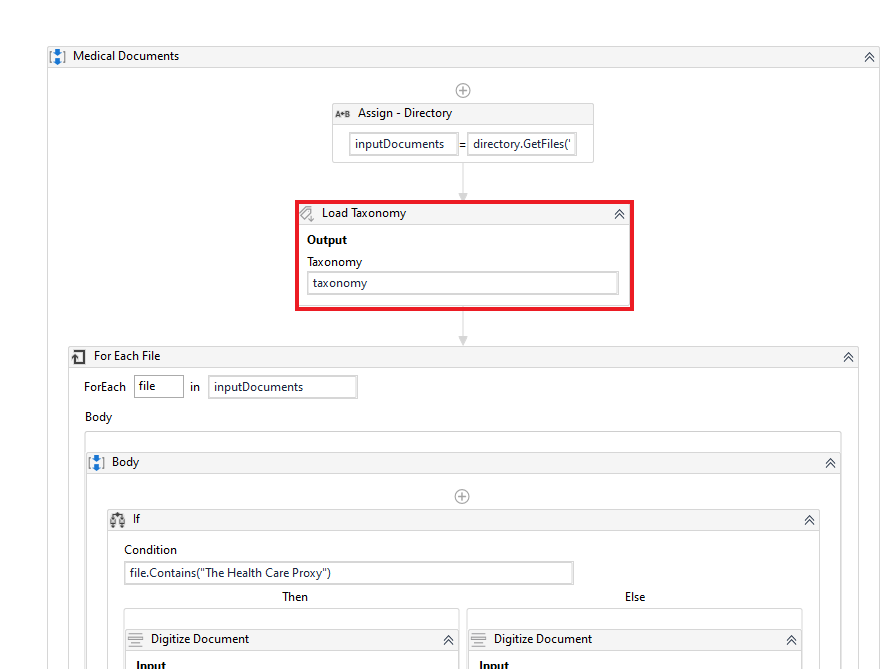
With the For Each activity, the robot continues iterating through every file that is present in the specified folder. The next step is the Digitize Document activity. To make the files readable by the machine, we need to convert it into a digital format and this is done with this activity. We extract a Document Object Model(DOM) and text document and we store them in their corresponding variable types. In this project, we use two different engines for Intelligent OCR, the Microsoft OCR, and the OmniPage OCR. Two different engines were used because they gave different results for both files.
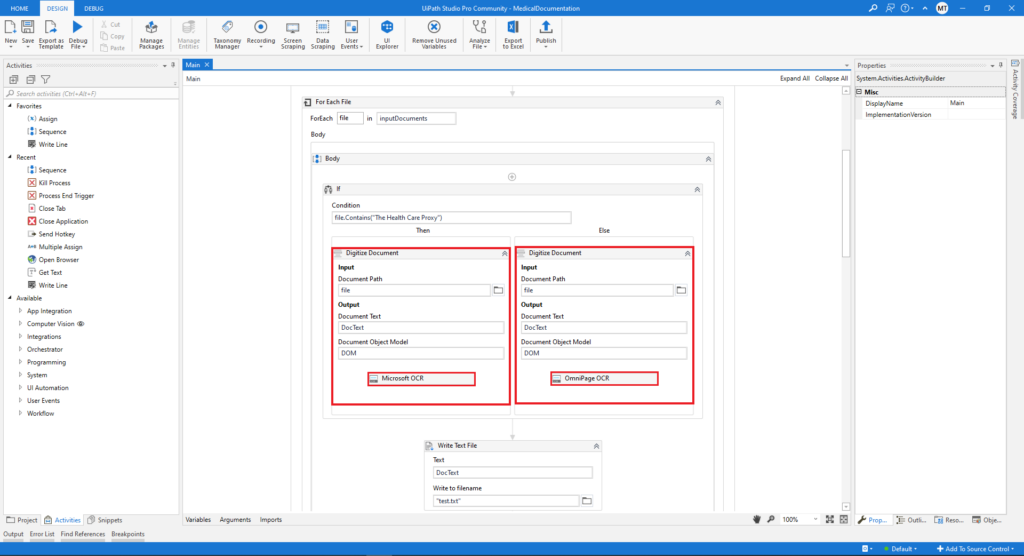
Once the Digitize Document activity was completed, a Write Text File activity was added so the output from the previous process could be stored in the .txt file. In this .txt we can see that all the information from one of the documents is extracted.

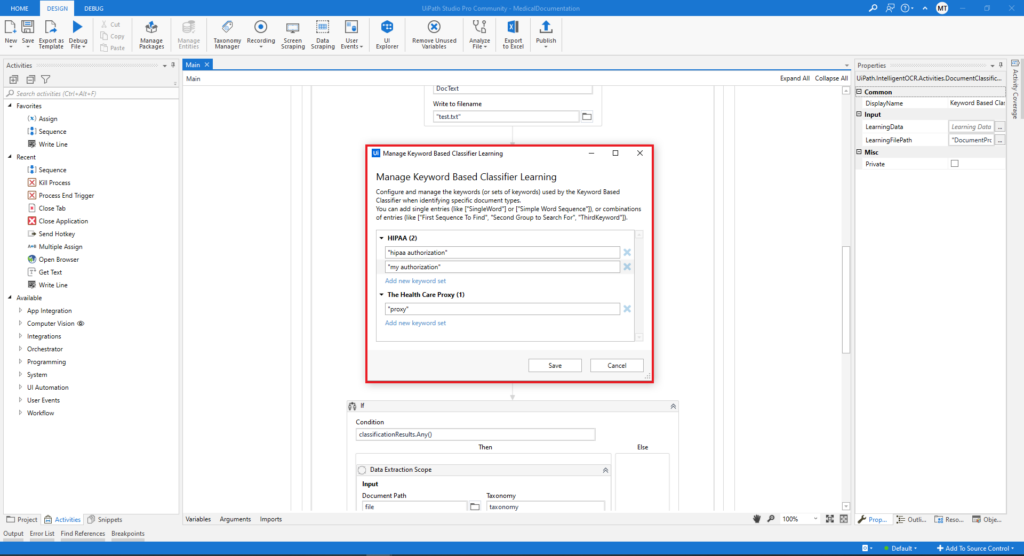
The next activity is the Classify Document Scope. The reason why we are using this activity is that in this process we have two different documents. After all the input variables are set (Document Path, Document Text, DOM, and Taxonomy), we define a variable as an output for Classification Results. Also in this activity, we need to add one more activity that is called Keyword Based Classifier. In order to configure this classifier, we need to create one blank JSON file in the DocumentProcessing folder and after that in the Learning File Path field, the path to this JSON file is populated.
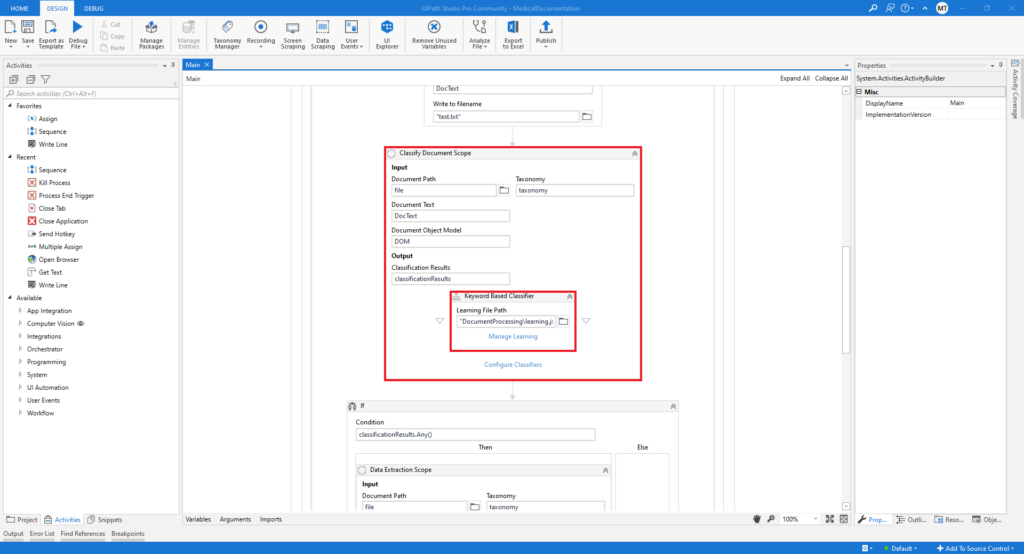
In the Keyword Based Classifier, the keywords from each document are written, and we can add as much as we want. This part is significant because it helps to easily detect the documents.
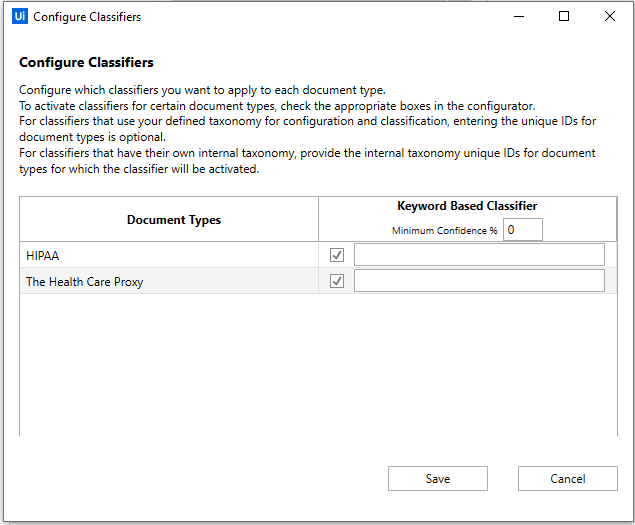
At the bottom of the Classify Document Scope activity, we can notice the field Configure Classifiers which is used for selecting the documents that should be processed.
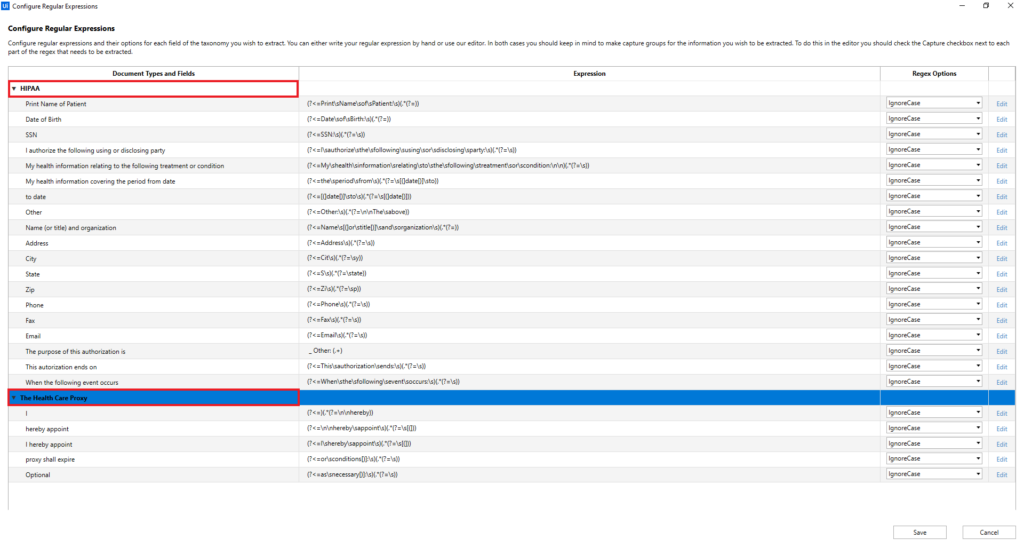
After the classification, the extraction of the data with the Data Extraction Scope activity follows. First, we set the input and output variables for this activity, and then for the extraction of the data we use the Regex Based Extractor. At this point, the regular expressions for every text field are defined.
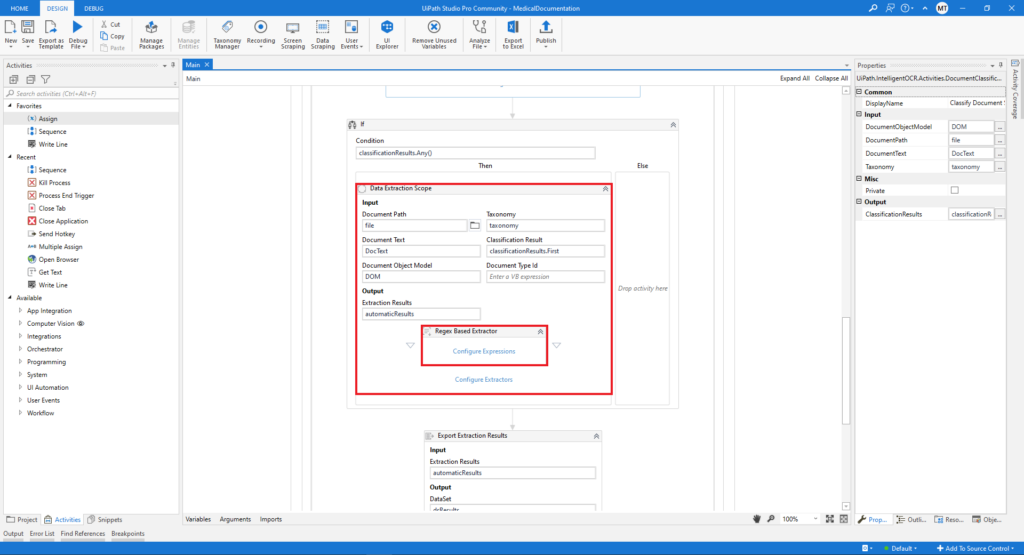
The next activity in this sequence is the Export Extraction Results activity. In this part, the results from the data extraction are converted i.e. exported to a variable of type DataSet.
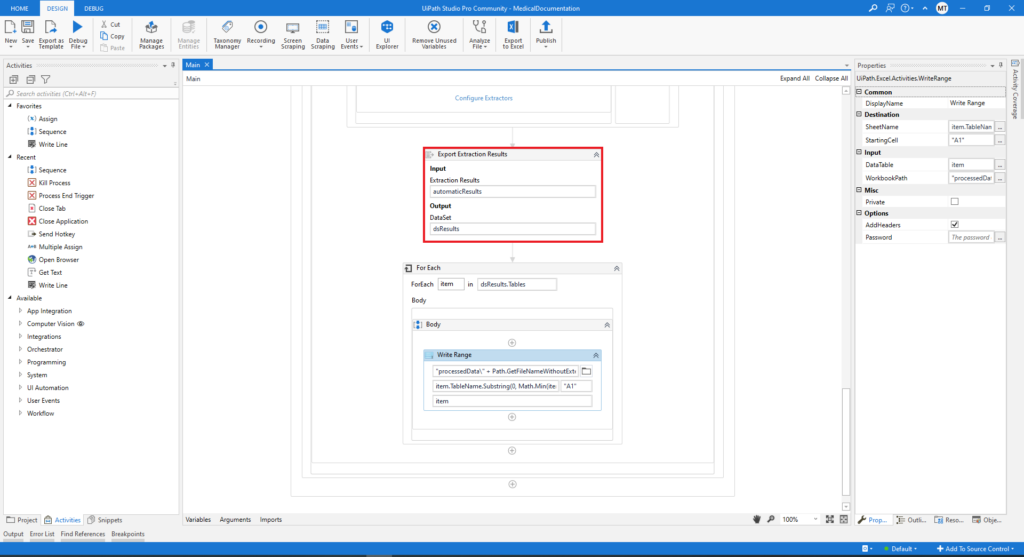
In the end, the process is finished with the Write Range activity which is getting the data from the DataSet and is writing the extracted data in an Excel document.
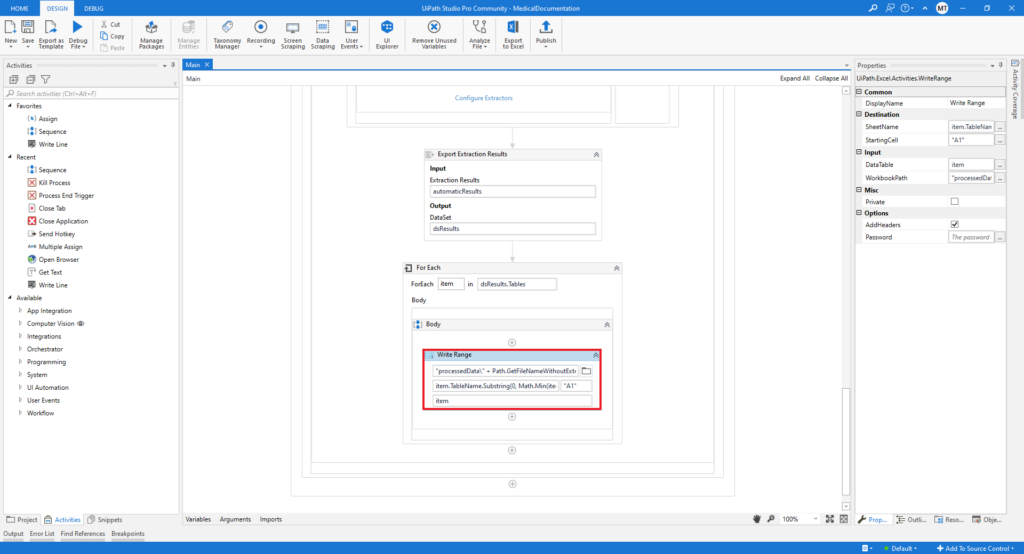
The results of the entire process can be seen below – all the values from the fields that were defined in the Taxonomy Manager are populated in a separate column in the Excel document.
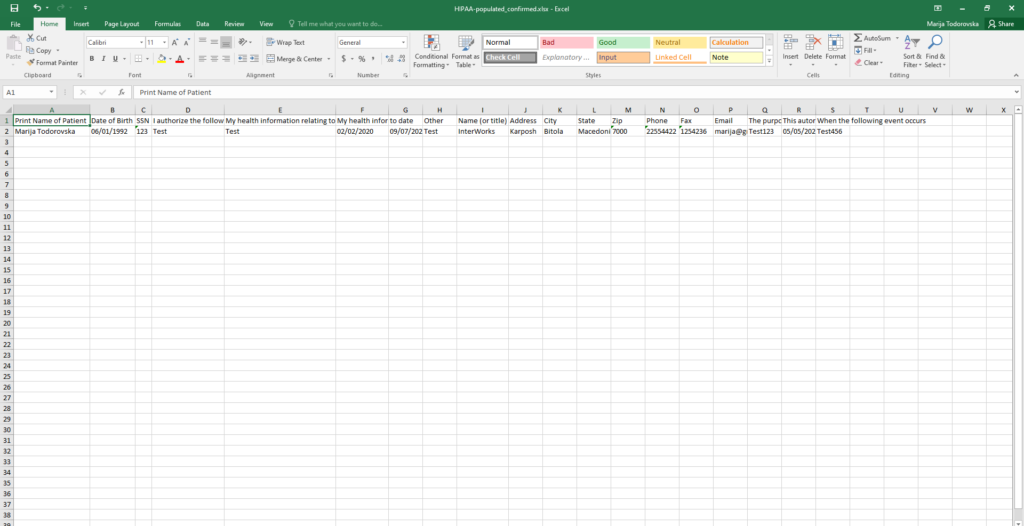
Conclusion
As we are witnesses of fast technological progress, we cannot just stay still and not search for solutions to problems that affect efficiency. By creating this RPA solution, we wanted to facilitate the processes involving a lot of documents in healthcare institutions by eliminating repetitive administrative tasks. This solution simplifies daily tasks and makes work easier and less time-consuming. Once the solution is created, there is no need for human intervention, and all activities are done with high accuracy and no hesitation.
If you want to see how the solution works, feel free to contact us.